Automating application deployment with continuous delivery is transforming how software is built and released, offering a more efficient and reliable approach. This method embraces the principles of Continuous Delivery (CD), a practice that emphasizes automating the software release process to deliver updates and features frequently and predictably.
This document will explore the core concepts of CD, from the initial code commit to the final deployment, highlighting the key components of a CD pipeline. We will delve into version control, build automation, automated testing, deployment strategies, infrastructure as code, monitoring, logging, and security considerations. By understanding these elements, organizations can streamline their development lifecycles, reduce errors, and accelerate time-to-market.
Introduction to Automating Application Deployment with Continuous Delivery
Automating application deployment with Continuous Delivery (CD) is a pivotal practice in modern software development. It streamlines the software release process, enabling faster, more reliable, and more frequent deployments. This approach contrasts sharply with traditional, manual deployment methods, which are often slow, error-prone, and resource-intensive. This section will explore the core principles of CD, define automated application deployment, highlight its benefits, and discuss the challenges organizations face without adopting this methodology.
Core Principles of Continuous Delivery
Continuous Delivery is a software development practice where code changes are automatically built, tested, and prepared for release to production. It’s a natural extension of Continuous Integration (CI), which focuses on merging code changes frequently. CD emphasizes automation and visibility at every stage of the software delivery pipeline, from code commit to production deployment.
- Automation: Automation is the cornerstone of CD. It involves automating build, test, and deployment processes. This reduces manual intervention, minimizes human error, and accelerates the delivery cycle.
- Visibility: Transparency across the entire delivery pipeline is crucial. This includes providing real-time feedback on build status, test results, and deployment progress. Tools like dashboards and automated reporting systems provide this visibility.
- Feedback Loops: CD incorporates feedback loops to quickly identify and address issues. This involves gathering feedback from various sources, including automated tests, monitoring tools, and user interactions.
- Incremental Changes: CD promotes delivering small, incremental changes rather than large, infrequent releases. This approach reduces the risk of introducing bugs and makes it easier to roll back changes if necessary.
- Collaboration: Successful CD requires strong collaboration between development, operations, and testing teams. This collaborative approach ensures that everyone is aligned and working towards the same goals.
Definition of Automated Application Deployment
Automated application deployment is the process of automatically deploying software applications to various environments, such as testing, staging, and production, without manual intervention. It leverages automation tools and scripts to execute the deployment process, including tasks like building the application, configuring servers, deploying code, and running tests.
Automated application deployment eliminates manual steps and human errors, making the process faster, more reliable, and repeatable.
Benefits of Automating Application Deployment Using CD
Adopting Continuous Delivery and automating application deployment offers several significant advantages for organizations. These benefits translate to improved efficiency, faster time-to-market, and higher quality software.
- Faster Time-to-Market: Automating deployments significantly reduces the time it takes to release new features and bug fixes to production. This allows businesses to respond more quickly to market demands and customer feedback. For example, companies using CD can release updates multiple times a day, while those using manual deployment may release updates only a few times a month.
- Reduced Risk: By automating the deployment process and incorporating automated testing, CD reduces the risk of human error and ensures that deployments are consistent and reliable. Automated testing identifies bugs early in the development cycle, reducing the likelihood of production issues.
- Improved Quality: Frequent testing and continuous feedback loops help to identify and fix bugs quickly. This leads to higher quality software and a better user experience. Continuous monitoring and feedback mechanisms provide insights into application performance and user behavior, enabling proactive issue resolution.
- Increased Efficiency: Automating deployment frees up developers and operations teams from manual tasks, allowing them to focus on more strategic work. This improves overall efficiency and productivity. Automating tasks like server provisioning, configuration management, and deployment orchestration streamlines workflows.
- Enhanced Collaboration: CD fosters better collaboration between development, operations, and testing teams. This collaborative approach leads to improved communication, shared responsibility, and a more cohesive work environment.
Common Challenges Organizations Face Without CD
Organizations that do not adopt Continuous Delivery often face several challenges that can hinder their ability to deliver software efficiently and effectively. These challenges impact various aspects of the software development lifecycle, from development speed to operational reliability.
- Slow Release Cycles: Without automation, the release process is often slow and cumbersome, leading to infrequent releases and delayed time-to-market. Manual processes are prone to delays caused by human error and coordination issues.
- Increased Risk of Errors: Manual deployments are prone to errors, which can lead to downtime, data loss, and a poor user experience. The lack of automation increases the likelihood of configuration mistakes and deployment failures.
- Difficulties in Scaling: As applications grow in complexity and user base, manual deployment becomes increasingly difficult to scale. Organizations struggle to handle the increased workload and complexity without automation.
- Siloed Teams: Without a shared understanding of the deployment process, development, operations, and testing teams often work in silos. This lack of collaboration leads to communication breakdowns and inefficiencies.
- Limited Feedback Loops: Without automated testing and monitoring, organizations receive limited feedback on the quality and performance of their software. This makes it difficult to identify and address issues promptly.
Core Components of a CD Pipeline
A Continuous Delivery (CD) pipeline automates the process of taking code changes from version control and delivering them to production. This automation ensures faster, more reliable, and more frequent releases. The core components work in concert to provide a streamlined and efficient path from code commit to live application.
Key Stages of a Typical CD Pipeline
A typical CD pipeline consists of several key stages, each playing a crucial role in the overall process. These stages, when executed correctly, facilitate a predictable and repeatable release cycle.
- Source Code Management (Version Control): This is where the process begins. Developers commit their code changes to a central repository, such as Git. This triggers the pipeline to start.
- Build Stage: The code is compiled, dependencies are resolved, and the application is packaged into a deployable artifact. This artifact could be a container image, a WAR file, or any other format suitable for deployment.
- Test Stage: Automated tests, including unit tests, integration tests, and potentially end-to-end tests, are executed to verify the quality and functionality of the built artifact. Tests can be run in parallel to reduce overall execution time.
- Deployment Stage: The artifact is deployed to a target environment. This might involve deploying to a staging environment for further testing or directly to production, depending on the pipeline’s configuration and the organization’s release strategy.
- Monitoring and Feedback: After deployment, the application is monitored for performance and stability. Logs and metrics are collected, and alerts are triggered if any issues arise. Feedback from this stage can be used to improve future releases.
Role of Version Control Systems in CD
Version control systems are fundamental to Continuous Delivery. They provide the foundation for tracking changes, collaborating on code, and automating the release process. They are essential for maintaining code integrity and enabling rapid, iterative development.
- Code Storage and History: Version control systems, such as Git, store the complete history of code changes. This allows for easy rollback to previous versions in case of errors.
- Branching and Merging: Developers can work on different features or bug fixes in separate branches. Once the changes are ready, they can be merged back into the main branch. This facilitates parallel development and reduces the risk of conflicts.
- Triggering the Pipeline: Committing code to a version control system is often the trigger that starts the CD pipeline. The pipeline automatically detects the changes and initiates the build, test, and deployment stages.
- Collaboration: Version control systems facilitate collaboration among developers by providing a central repository for code and a mechanism for managing changes.
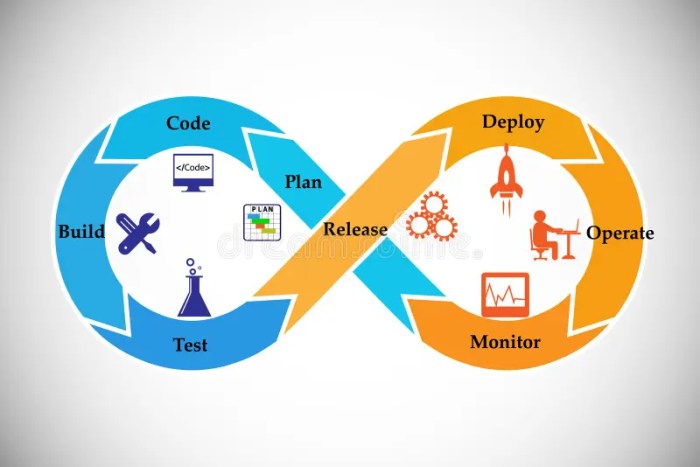
Diagram of a Simplified CD Pipeline
A simplified CD pipeline can be visualized as a series of interconnected stages. This diagram illustrates the flow of code changes from source code to production.
Diagram Description: The diagram illustrates a linear flow. At the beginning is the “Source Code” represented by a Git repository. An arrow points from it to the “Build” stage, which involves compiling the code and creating an artifact. The next arrow leads to the “Test” stage, where automated tests are executed. Following this, the “Deploy” stage deploys the artifact to the target environment.
Finally, an arrow points from the “Deploy” stage to “Monitor,” indicating the ongoing monitoring of the deployed application. The feedback loop from monitoring can also feed back into the source code repository for improvements.
Tools Used for Build Automation
Build automation tools streamline the process of compiling code, managing dependencies, and creating deployable artifacts. These tools are critical for ensuring consistent and reproducible builds.
| Tool | Description |
|---|---|
| Maven | Primarily used for Java projects, Maven manages dependencies, builds, and deployments. It follows a standardized project structure and uses a declarative approach. |
| Gradle | A versatile build automation tool that supports multiple languages and project types. Gradle offers flexibility and uses a Groovy or Kotlin-based domain-specific language (DSL) for configuration. |
| Jenkins | A widely used open-source automation server that can orchestrate the entire CD pipeline. Jenkins supports various plugins for integration with different tools and services. |
| GitLab CI/CD | Integrated CI/CD features within the GitLab platform. It provides a complete solution for managing the software development lifecycle, including version control, build automation, and deployment. |
| Travis CI | A cloud-based continuous integration service that automates the build, test, and deployment process. It is commonly used for open-source projects. |
| CircleCI | Another cloud-based CI/CD platform that offers fast build times and supports various programming languages and platforms. |
Version Control and Branching Strategies
Version control is the cornerstone of effective Continuous Delivery. It provides the necessary foundation for managing code changes, collaborating with a team, and ensuring the reliability of software releases. Implementing robust version control practices allows developers to track modifications, revert to previous states, and automate the deployment process with confidence.
Importance of Version Control in CD
Version control is fundamentally important to Continuous Delivery because it enables several critical capabilities. It tracks every change made to the codebase, allowing developers to understand the evolution of the software. This history is essential for debugging, auditing, and understanding the impact of specific changes. It also allows for parallel development, where multiple developers can work on different features or bug fixes concurrently without interfering with each other’s work.
Finally, it facilitates automation by providing a central source of truth for the codebase, which can be easily accessed and integrated into the CD pipeline.
Examples of Effective Branching Strategies
Branching strategies define how developers manage and merge code changes within a version control system. The chosen strategy significantly impacts the development workflow and the ease of integrating code into the main branch.
- Gitflow: Gitflow is a popular branching model that defines a strict branching structure designed to streamline collaboration. It uses a main branch (e.g., `main` or `master`), a `develop` branch for integrating features, feature branches for individual features, release branches for preparing releases, and hotfix branches for urgent bug fixes. This strategy promotes code stability by isolating feature development and providing clear points for integration and release.
- GitHub Flow: GitHub Flow is a simpler branching model, particularly suited for projects with continuous delivery. It involves a `main` branch and feature branches created from `main`. When a feature is complete, the feature branch is merged back into `main` via a pull request. This strategy emphasizes continuous integration and frequent releases.
- Trunk-Based Development: Trunk-based development involves developers integrating their code changes directly into the main branch (or trunk) frequently, ideally multiple times a day. Feature flags are often used to manage incomplete features. This strategy promotes rapid integration and fast feedback cycles, but requires a strong focus on automated testing and code quality.
Integrating Version Control with a CD Pipeline
Integrating version control with a CD pipeline involves several key steps that automate the build, testing, and deployment processes.
- Code Repository Integration: The CD pipeline is configured to monitor the version control repository (e.g., GitHub, GitLab, Bitbucket) for changes. Whenever a new commit is pushed to a specific branch (e.g., `main` or `develop`), the pipeline is triggered.
- Automated Build: Upon triggering, the pipeline automatically builds the application. This typically involves compiling the code, resolving dependencies, and creating deployable artifacts.
- Automated Testing: The built application is then subjected to automated testing, including unit tests, integration tests, and potentially end-to-end tests. This ensures the quality and stability of the software.
- Deployment: If all tests pass, the pipeline automatically deploys the application to the target environment (e.g., staging or production). This may involve updating servers, configuring databases, and restarting services.
- Rollback Mechanism: The CD pipeline often includes a rollback mechanism that allows for quick reversion to a previous, stable version if deployment issues arise. This might involve deploying a previous artifact or reverting the database schema.
Best Practices for Managing Code in a CD Environment
Following best practices for code management is essential for maintaining a smooth and efficient CD pipeline.
- Use a Centralized Version Control System: Choose a reputable and reliable version control system (e.g., Git) and ensure all team members use it consistently.
- Implement a Branching Strategy: Select a branching strategy (e.g., Gitflow, GitHub Flow, Trunk-Based Development) that aligns with the project’s needs and team’s workflow.
- Write Clear and Concise Commit Messages: Commit messages should clearly explain the changes made, making it easier to track the evolution of the codebase.
- Perform Code Reviews: Code reviews by other team members help catch errors, ensure code quality, and share knowledge.
- Automate Everything: Automate as much of the build, test, and deployment processes as possible to reduce manual effort and potential errors.
- Implement Continuous Integration: Integrate code changes frequently to detect and resolve integration issues early.
- Test Thoroughly: Implement a comprehensive suite of automated tests to ensure the application’s quality and stability.
- Use Feature Flags: Feature flags allow developers to release new features without immediately exposing them to all users, providing a mechanism to control and manage the rollout of new functionality.
- Monitor and Log: Implement robust monitoring and logging to track application performance, identify issues, and provide valuable insights.
Build Automation and Continuous Integration
Build automation and Continuous Integration (CI) are essential practices in modern software development, forming the backbone of efficient and reliable application deployment. They streamline the process of converting source code into executable software, ensuring code quality and accelerating the delivery cycle. This section delves into the core concepts and practical implementation of build automation and CI.
Purpose of Build Automation
Build automation streamlines the process of converting source code into a functional application. This process typically involves compiling code, linking libraries, running tests, and packaging the application for deployment. The primary purpose is to automate these repetitive tasks, reducing manual effort and minimizing the potential for human error.
Popular Build Automation Tools
Several robust tools facilitate build automation. Choosing the right tool depends on project requirements, team expertise, and existing infrastructure.
- Jenkins: An open-source automation server, Jenkins is highly versatile and supports a vast ecosystem of plugins. It can handle various build and deployment processes, making it a popular choice for projects of all sizes. It is widely used in different organizations like Netflix, LinkedIn, and eBay.
- GitLab CI: Integrated directly into GitLab, this tool offers a seamless CI/CD experience, especially beneficial for teams already using GitLab for version control. It’s known for its ease of use and tight integration with Git repositories.
- Travis CI: Another popular CI service, Travis CI is primarily designed for open-source projects but also supports private repositories. It offers a simple configuration and integrates well with GitHub.
- CircleCI: This cloud-based CI/CD platform is known for its speed and scalability. It supports a wide range of languages and platforms and offers features like parallel testing.
- TeamCity: Developed by JetBrains, TeamCity is a commercial CI/CD server known for its robust features and integrations with JetBrains IDEs.
Configuring a CI Server to Automatically Build and Test Code
Configuring a CI server involves several key steps to automate the build and testing process. These steps ensure that every code change triggers an automated process, validating the code’s quality.
- Source Code Repository Integration: The CI server must be connected to the version control system (e.g., Git) where the source code resides. This connection enables the server to detect code changes and trigger builds automatically.
- Build Definition: A build definition, often defined in a configuration file (e.g., `Jenkinsfile` for Jenkins or `.gitlab-ci.yml` for GitLab CI), specifies the steps required to build the application. This includes commands for compiling code, running tests, and packaging the application.
- Test Execution: The build definition includes instructions for running automated tests. These tests verify the functionality of the code, identify bugs, and ensure code quality. Test results are then collected and reported.
- Notification and Reporting: The CI server provides feedback on the build and test results. This includes notifications (e.g., email, Slack) to the development team and detailed reports that highlight any failures or issues.
Step-by-Step Procedure for Setting Up a Basic CI Pipeline
Setting up a basic CI pipeline involves several well-defined steps, from configuring the CI server to integrating with the version control system and defining the build process. This provides a structured approach to automated builds and testing.
- Choose a CI Server: Select a CI server (e.g., Jenkins, GitLab CI) based on project requirements and team preferences.
- Install and Configure the CI Server: Install the chosen CI server on the appropriate infrastructure (e.g., a server, cloud instance). Configure the server’s basic settings, such as user accounts and network configurations.
- Integrate with Version Control: Connect the CI server to the source code repository (e.g., GitHub, GitLab, Bitbucket). This typically involves providing the CI server with the repository URL and credentials.
- Create a Build Definition: Create a build definition file (e.g., `Jenkinsfile`, `.gitlab-ci.yml`) that specifies the build process. This file defines the steps for compiling code, running tests, and packaging the application.
- Define Build Steps: Within the build definition, specify the commands for building and testing the application. This includes commands for installing dependencies, running tests, and generating reports.
- Configure Triggers: Configure triggers to automatically initiate builds. Common triggers include code pushes to specific branches or scheduled intervals.
- Test the Pipeline: Trigger a build manually or by pushing a code change. Verify that the build process runs correctly and that test results are reported.
- Monitor and Iterate: Continuously monitor the CI pipeline, analyze build results, and make adjustments to optimize the process. Refine the build definition as the project evolves.
Automated Testing Strategies
Automated testing is a cornerstone of Continuous Delivery (CD), enabling rapid feedback and ensuring software quality throughout the deployment pipeline. It allows developers to catch bugs early, reduce manual effort, and build confidence in each release. Effective automated testing strategies are crucial for achieving the speed and reliability that CD aims to provide.
Different Types of Automated Tests
A comprehensive testing strategy incorporates various test types to cover different aspects of the software. Each type serves a specific purpose and contributes to the overall quality assurance process.
- Unit Tests: These tests focus on individual components or units of code, such as functions or methods. They verify that each unit behaves as expected in isolation. Unit tests are typically the fastest to execute and are written by developers during the development phase. For example, a unit test might verify that a function correctly calculates the factorial of a number, given different inputs.
- Integration Tests: Integration tests verify the interaction between different components or modules of the software. They ensure that these components work together seamlessly. These tests often involve testing the communication between different parts of the application or with external services like databases or APIs. An example would be testing the interaction between a web server and a database to ensure data is correctly stored and retrieved.
- End-to-End (E2E) Tests: Also known as system tests, E2E tests simulate real user scenarios, testing the entire application from the user interface (UI) to the backend systems. They verify that the application functions correctly as a whole. E2E tests are the most comprehensive but also the slowest to execute. An example is testing a user login flow, including UI interaction, authentication, and access to protected resources.
- Performance Tests: These tests assess the performance characteristics of the software, such as response time, throughput, and resource utilization. They help identify bottlenecks and ensure the application can handle the expected load. Performance tests include load testing, stress testing, and endurance testing. For instance, load testing simulates multiple users accessing the application simultaneously to evaluate its performance under pressure.
- Security Tests: Security tests identify vulnerabilities in the software that could be exploited by attackers. They include penetration testing, vulnerability scanning, and security audits. These tests ensure that the application is protected against common security threats, such as SQL injection and cross-site scripting (XSS).
Importance of Test-Driven Development (TDD) in CD
Test-Driven Development (TDD) is a software development process where tests are written before the code. This approach significantly benefits CD by promoting early bug detection and improving code quality.
- Reduced Bugs: Writing tests before code forces developers to think about the requirements and expected behavior of the software, leading to more robust and less error-prone code.
- Improved Code Design: TDD encourages developers to write modular and testable code, resulting in better design and easier maintenance.
- Faster Feedback: TDD provides immediate feedback on code changes, allowing developers to identify and fix issues quickly.
- Increased Confidence: With a comprehensive suite of tests, developers can be confident that their changes will not break existing functionality.
- Facilitates Refactoring: TDD makes it easier to refactor code, as the tests act as a safety net, ensuring that the refactoring does not introduce any regressions.
TDD follows a simple cycle: write a failing test, write the code to pass the test, and then refactor the code.
Incorporating Automated Testing into the CD Pipeline
Integrating automated testing into the CD pipeline is essential for achieving continuous feedback and rapid releases. This integration ensures that tests are executed automatically at various stages of the pipeline.
- Build Stage: Unit tests are typically executed during the build stage. If any unit tests fail, the build is considered unsuccessful, and the deployment process is halted.
- Integration Stage: Integration tests are run after the build and unit tests have passed. This stage verifies the interactions between different components.
- Testing Stage: E2E tests, performance tests, and security tests are often executed in a dedicated testing stage. This stage simulates real-world scenarios and validates the application’s functionality, performance, and security.
- Deployment Stage: Before deploying to production, automated tests, such as smoke tests, are run to ensure that the application is functioning correctly in the target environment.
- Continuous Monitoring: After deployment, automated tests, such as monitoring and alerting systems, continuously monitor the application’s performance and health.
Examples of Testing Frameworks and Tools
Various testing frameworks and tools are available to support automated testing across different programming languages and testing types. The choice of tools depends on the project’s specific requirements and technology stack.
- Unit Testing Frameworks:
- JUnit (Java): A widely used framework for writing and running unit tests in Java.
- pytest (Python): A versatile framework that simplifies writing and running tests in Python.
- Jest (JavaScript): A popular testing framework for JavaScript applications, particularly those using React.
- Integration Testing Frameworks:
- Spring Test (Java): Provides utilities for testing Spring-based applications, including integration tests.
- Selenium (Web): An open-source tool for automating web browser interactions, often used for integration and E2E testing.
- End-to-End Testing Frameworks:
- Cypress (Web): A modern E2E testing framework designed for the web, providing fast and reliable tests.
- Playwright (Web): A cross-browser testing framework for automating web applications.
- Performance Testing Tools:
- JMeter: An open-source tool for load testing and performance measurement.
- LoadRunner: A commercial tool for load testing and performance analysis.
- Security Testing Tools:
- OWASP ZAP: An open-source web application security scanner.
- SonarQube: A platform for continuous inspection of code quality and security.
Deployment Strategies
Deployment strategies are crucial for a smooth and reliable software delivery process. They define how new versions of an application are released to users, minimizing downtime and mitigating risks. Choosing the right strategy depends on factors like application complexity, user base size, and the acceptable level of risk.
Deployment Strategy Comparison
Different deployment strategies offer various approaches to releasing new application versions. Each strategy has its own set of advantages and disadvantages, making it essential to select the one that best fits the project’s requirements.Here’s a comparison of several common deployment strategies:
| Deployment Strategy | Description | Advantages | Disadvantages |
|---|---|---|---|
| Blue/Green Deployment | Two identical environments (blue and green) are maintained. One (e.g., blue) serves live traffic, while the other (green) receives the new version. Once testing is complete, traffic is switched to the green environment. |
|
|
| Canary Deployment | A small subset of users (the “canary”) receives the new version of the application. If the canary deployment performs well, the new version is gradually rolled out to the rest of the users. |
|
|
| Rolling Deployment | New application instances are deployed one by one, or in small batches, while the existing instances continue to serve traffic. As new instances become available, the old instances are removed. |
|
|
| Immutable Deployment | The application is deployed as an immutable artifact (e.g., a container image). When a new version is released, the old version is replaced with the new version, often by spinning up new instances and terminating the old ones. |
|
|
Implementing a Canary Deployment
Implementing a canary deployment involves several key steps to ensure a safe and controlled rollout. This approach allows for early detection of issues and minimizes the impact on users.Here’s a breakdown of the implementation process:
- Select a Canary Group: Identify a small group of users (e.g., 1-5% of your user base) to be the canary. This group can be chosen based on various criteria, such as geographic location, user segment, or a random selection.
- Deploy the New Version: Deploy the new version of the application to a separate environment or a subset of instances. This environment will serve as the canary.
- Route Traffic to the Canary: Configure your load balancer or traffic routing system to direct traffic from the canary group to the new version. This can be done using various techniques, such as:
- Header-based routing: Route requests based on HTTP headers.
- Cookie-based routing: Set a cookie for canary users.
- Percentage-based routing: Route a percentage of traffic to the new version.
- Monitor and Observe: Continuously monitor the performance and behavior of the canary deployment. Key metrics to track include:
- Error rates: Monitor for any increases in errors or exceptions.
- Response times: Ensure response times remain within acceptable limits.
- User experience: Analyze user feedback and any reported issues.
- Resource utilization: Monitor CPU, memory, and other resource metrics.
- Analyze and Validate: Analyze the collected data to determine if the canary deployment is successful. If the performance is satisfactory, proceed to the next step. If issues are detected, revert to the previous version.
- Gradual Rollout: If the canary deployment is successful, gradually increase the percentage of traffic directed to the new version. This allows for a controlled rollout to the entire user base. The rollout might involve stages:
- 1% of users
- 5% of users
- 20% of users
- 50% of users
- 100% of users
- Full Release: Once the new version has been successfully deployed to the entire user base, remove the canary deployment configuration.
- Example: Consider an e-commerce website. A canary deployment could be used to test a new checkout process. The new checkout process is deployed to a small percentage of users. If the checkout process performs well (e.g., no increase in abandoned carts, no reported errors), the new checkout process is rolled out to all users. If the checkout process has problems (e.g., increased abandoned carts), the traffic is reverted to the old checkout process.
Infrastructure as Code (IaC)

Infrastructure as Code (IaC) is a cornerstone of modern software development and continuous delivery. It represents a paradigm shift in how infrastructure is managed, moving away from manual configuration and towards automated, code-driven provisioning. This approach brings the benefits of version control, automation, and repeatability to infrastructure management, mirroring the practices used for application code.
The Concept of Infrastructure as Code (IaC)
IaC is the practice of managing and provisioning infrastructure (servers, networks, load balancers, etc.) through code rather than manual processes. This code defines the desired state of the infrastructure, and tools are used to automatically create, modify, and destroy infrastructure resources to match this state. The code is typically written in a declarative or imperative language, and it’s stored in version control systems, allowing for tracking changes, collaboration, and rollback capabilities.
Examples of IaC Tools
Several tools are available to implement IaC, each with its strengths and weaknesses. The choice of tool depends on factors like cloud provider, complexity of the infrastructure, and team expertise. Some popular examples include:
- Terraform: Terraform, developed by HashiCorp, is a widely used IaC tool that supports multiple cloud providers and on-premises infrastructure. It uses a declarative language (HashiCorp Configuration Language or HCL) to define infrastructure. Terraform plans changes before applying them, allowing for preview and validation. It excels at managing complex infrastructure deployments across multiple providers. For instance, a company using Terraform could define its entire cloud infrastructure, including virtual machines, databases, and networking, in code.
This code can then be versioned, allowing for easy replication of the environment, as well as the ability to rollback to previous infrastructure configurations if issues arise.
- Ansible: Ansible, also developed by Red Hat, is an agentless automation tool that uses YAML to describe infrastructure configuration and orchestration. Ansible is well-suited for configuration management and task automation, making it ideal for deploying and configuring software on existing servers. It’s often used in conjunction with other IaC tools like Terraform. An example use case for Ansible is automating the installation and configuration of web servers on a fleet of virtual machines.
- CloudFormation: CloudFormation is an IaC service provided by Amazon Web Services (AWS). It uses YAML or JSON templates to define and manage AWS resources. CloudFormation is tightly integrated with the AWS ecosystem, making it a natural choice for users of AWS services. For example, a company migrating its on-premises applications to AWS could use CloudFormation to define and deploy all the necessary AWS resources, such as EC2 instances, S3 buckets, and databases.
How IaC Supports Automated Deployment
IaC significantly enhances automated deployment by providing a consistent and repeatable way to provision the infrastructure required to run applications. When combined with continuous integration and continuous delivery (CI/CD) pipelines, IaC allows for:
- Faster deployments: Infrastructure can be provisioned rapidly and consistently, eliminating manual steps and reducing deployment times.
- Reduced errors: Automation minimizes the risk of human error, leading to more reliable deployments.
- Increased consistency: IaC ensures that the infrastructure is configured consistently across different environments (development, testing, production).
- Improved scalability: Infrastructure can be easily scaled up or down based on application needs.
- Enhanced rollback capabilities: If a deployment fails, the infrastructure can be easily rolled back to a previous state.
IaC Best Practices
Adhering to best practices is crucial for effective IaC implementation. These practices help to ensure that the infrastructure is manageable, maintainable, and secure.
- Version control: Store IaC code in a version control system (e.g., Git) to track changes, enable collaboration, and facilitate rollbacks.
- Modularity and reusability: Break down IaC code into reusable modules or templates to avoid duplication and improve maintainability.
- Testing: Implement testing strategies (e.g., unit tests, integration tests) to validate the IaC code and ensure that it behaves as expected.
- Security: Incorporate security best practices into IaC code, such as using secrets management tools, following the principle of least privilege, and regularly reviewing security configurations.
- Documentation: Document the IaC code and its purpose to facilitate understanding and collaboration.
- Idempotency: Design IaC code to be idempotent, meaning that running the code multiple times produces the same result.
- Automation of updates: Automate the process of updating infrastructure configurations using CI/CD pipelines.
- Regularly review and audit: Regularly review and audit the IaC code to ensure that it aligns with the organization’s standards and best practices. This helps identify potential issues early on and maintain the integrity of the infrastructure.
Monitoring and Logging
Implementing robust monitoring and logging practices is crucial for the success of any Continuous Delivery (CD) pipeline. They provide essential insights into the performance, health, and behavior of applications and infrastructure throughout the deployment lifecycle. Effective monitoring and logging enable rapid identification and resolution of issues, ensure optimal application performance, and provide valuable data for continuous improvement of the CD process.
Importance of Monitoring and Logging in a CD Environment
Monitoring and logging are indispensable elements within a CD environment, serving multiple critical functions that directly contribute to the reliability, performance, and maintainability of deployed applications. These practices are essential for achieving the goals of CD, which include faster release cycles, reduced risk, and improved customer satisfaction.
- Real-time Visibility: Monitoring provides real-time visibility into the application’s behavior, including performance metrics (response times, throughput, error rates), resource utilization (CPU, memory, disk I/O), and application-specific metrics. Logging captures detailed information about events, errors, and user actions, providing context for troubleshooting and analysis.
- Proactive Issue Detection: Monitoring systems can be configured to detect anomalies and trigger alerts based on predefined thresholds. This allows teams to proactively identify and address issues before they impact users. Logging enables the analysis of historical data to identify trends and potential problems.
- Faster Troubleshooting: When issues arise, monitoring and logging provide the data needed to quickly diagnose the root cause. Detailed logs, coupled with performance metrics, help pinpoint the exact point of failure and accelerate the resolution process.
- Performance Optimization: Monitoring tools provide insights into application performance bottlenecks. This information can be used to optimize code, infrastructure, and deployment processes, leading to improved performance and scalability.
- Compliance and Auditing: Comprehensive logging helps meet compliance requirements and facilitates audits. Log data provides a record of all actions performed on the system, including deployments, configuration changes, and user activities.
- Continuous Improvement: By analyzing monitoring data and logs, teams can identify areas for improvement in the application, infrastructure, and CD pipeline itself. This data-driven approach enables continuous optimization and refinement of the deployment process.
Examples of Monitoring and Logging Tools
Numerous tools are available for monitoring and logging in a CD environment, each with its own strengths and weaknesses. The choice of tools depends on the specific requirements of the application, infrastructure, and team preferences. Some popular and widely adopted examples are detailed below.
- Prometheus: Prometheus is a powerful, open-source monitoring system designed for collecting and storing time-series data. It excels at monitoring dynamic environments, such as containerized applications, and is well-suited for collecting metrics from various sources. It uses a pull-based model, where it scrapes metrics from configured targets. Prometheus is often used with Grafana for visualization.
Prometheus is particularly effective for monitoring containerized applications, as it can dynamically discover and monitor services based on labels and annotations.
- Grafana: Grafana is a versatile open-source platform for data visualization and analysis. It integrates seamlessly with various data sources, including Prometheus, Elasticsearch, and InfluxDB. Grafana allows users to create highly customizable dashboards to visualize metrics, track trends, and identify anomalies. It is a key component in visualizing data collected by Prometheus.
Grafana’s ability to create interactive dashboards makes it an invaluable tool for monitoring application health and performance in real time.
- ELK Stack (Elasticsearch, Logstash, Kibana): The ELK stack (now often referred to as the Elastic Stack) is a popular open-source solution for log management and analysis. Elasticsearch is a distributed search and analytics engine that stores and indexes log data. Logstash is a data processing pipeline that collects, parses, and transforms logs. Kibana is a visualization and exploration tool that allows users to search, analyze, and visualize log data stored in Elasticsearch.
The ELK stack is widely used for centralizing and analyzing logs from various sources, providing a comprehensive view of application and infrastructure behavior.
- Datadog: Datadog is a commercial monitoring and analytics platform that provides comprehensive monitoring capabilities for applications, infrastructure, and network performance. It offers a wide range of integrations with popular technologies and services, and provides features such as real-time dashboards, alerting, and log management.
Datadog is a popular choice for organizations that require a comprehensive, cloud-based monitoring solution with a wide range of features and integrations.
- New Relic: New Relic is another commercial monitoring platform that offers application performance monitoring (APM), infrastructure monitoring, and log management capabilities. It provides real-time insights into application performance, error rates, and user experience.
New Relic is often used by large enterprises to monitor complex applications and infrastructure environments.
Integrating Monitoring and Logging into the CD Pipeline
Integrating monitoring and logging into the CD pipeline is crucial for ensuring that the deployment process is reliable, efficient, and well-understood. This integration involves configuring monitoring and logging tools to collect data from all stages of the pipeline, from build and testing to deployment and operation.
- Build Stage: Integrate build tools (e.g., Maven, Gradle) with logging frameworks (e.g., Log4j, SLF4j) to capture build events, warnings, and errors. Configure build scripts to generate reports that include build times, test results, and code quality metrics.
- Testing Stage: Configure test frameworks (e.g., JUnit, TestNG) to generate detailed test reports, including pass/fail rates, test execution times, and error messages. Integrate these reports with a logging and monitoring system to track test performance and identify failing tests. Use tools like SonarQube for static code analysis to track code quality metrics.
- Deployment Stage: Implement monitoring and logging within deployment scripts to capture deployment events, such as the start and end of deployments, the status of each deployment step, and any errors that occur. Integrate with infrastructure provisioning tools (e.g., Terraform, Ansible) to monitor infrastructure changes.
- Runtime Environment: Configure applications to log detailed information about their behavior, including user actions, API calls, database queries, and error messages. Deploy monitoring agents (e.g., Prometheus exporters, Datadog agents) to collect metrics from applications and infrastructure. Implement health checks to monitor the availability and responsiveness of services.
- Alerting and Notification: Configure alerting rules in the monitoring system to notify teams of critical issues, such as high error rates, slow response times, or infrastructure failures. Integrate with notification channels (e.g., Slack, email, PagerDuty) to ensure timely responses to incidents.
- Automated Rollbacks: Integrate monitoring and alerting with automated rollback mechanisms. If a deployment introduces critical issues, the monitoring system should trigger an automated rollback to the previous stable version.
- Centralized Logging: Centralize logs from all stages of the pipeline and from the runtime environment. This allows for easier analysis, troubleshooting, and correlation of events. Use tools like the ELK stack or Datadog for centralized log management.
Designing a Dashboard Showing Key Metrics for a Deployed Application
Designing an effective dashboard is essential for quickly understanding the health and performance of a deployed application. The dashboard should display key metrics that provide insights into application behavior, resource utilization, and user experience. The specific metrics will vary depending on the application, but the following are common and recommended:
- Response Time: Display the average and percentile response times for key API endpoints or application pages. This metric reflects the speed at which the application is responding to user requests.
For example, a dashboard could show the 95th percentile response time for the /products endpoint, indicating that 95% of requests are served within a certain timeframe.
- Error Rate: Monitor the rate of errors, such as HTTP 500 errors or application-specific exceptions. A high error rate indicates potential problems with the application’s code or infrastructure.
An increase in the error rate, from 1% to 10%, could indicate a recent code change has introduced a bug.
- Throughput: Track the number of requests per second or minute to assess the application’s load and capacity. This metric is essential for understanding how the application is handling traffic.
For example, a dashboard could show the number of orders processed per minute, providing insights into the application’s ability to handle peak loads.
- CPU Utilization: Monitor the CPU utilization of the application servers to identify potential performance bottlenecks. High CPU utilization can indicate that the application is under heavy load or that the code is inefficient.
If CPU utilization consistently exceeds 80%, it may be necessary to scale the application horizontally by adding more servers.
- Memory Usage: Track the memory usage of the application servers to identify potential memory leaks or other memory-related issues.
An increasing trend in memory usage, without a corresponding increase in traffic, could indicate a memory leak.
- Disk I/O: Monitor the disk I/O activity to identify potential disk-related bottlenecks. High disk I/O can impact application performance.
If disk I/O is consistently high, it may be necessary to optimize database queries or consider using faster storage solutions.
- Database Performance: Monitor key database metrics, such as query response times, connection pool usage, and error rates. This helps to identify database-related performance issues.
A sudden increase in database query response times could indicate a problem with the database schema or the underlying infrastructure.
- User Experience Metrics: Track metrics related to user experience, such as page load times, click-through rates, and conversion rates. These metrics provide insights into user satisfaction.
A decrease in conversion rates could indicate that a recent code change has negatively impacted the user experience.
- Deployment Status: Display the status of recent deployments, including the deployment version, the deployment time, and any errors that occurred.
This provides a quick overview of the current deployment status and allows for quick identification of any issues.
The dashboard should be designed to be easily readable and actionable. Use clear visualizations, such as line graphs, bar charts, and gauges, to display the metrics. Configure alerts to notify teams of critical issues. The dashboard should be readily accessible to all team members involved in the CD pipeline, providing a centralized view of the application’s health and performance.
Security Considerations in CD
Implementing Continuous Delivery (CD) offers numerous benefits, but it also introduces new security challenges. Automating the deployment process, while streamlining releases, can expand the attack surface if not properly secured. A robust CD pipeline must therefore incorporate security measures at every stage to mitigate potential risks and maintain the integrity of the application and infrastructure. Neglecting security in CD can lead to vulnerabilities, data breaches, and compliance violations.
Security Risks Associated with Automated Deployment
Automated deployment introduces several security risks that must be carefully considered. These risks can be categorized based on their origin and impact.
- Unauthorized Access and Deployment: Automated deployments can be exploited if access controls are not properly configured. This could allow malicious actors to deploy unauthorized or compromised code, potentially leading to data breaches or system compromise.
- Vulnerability Exploitation: Automated deployments can quickly propagate vulnerabilities if the build process doesn’t include adequate security checks. If a vulnerable version of the application is deployed, attackers can exploit these vulnerabilities before they are patched.
- Configuration Errors: Automated deployments rely on configuration files and scripts. Incorrectly configured files can introduce security flaws, such as exposing sensitive information or misconfiguring access controls.
- Supply Chain Attacks: CD pipelines often pull dependencies from external sources. If these dependencies are compromised, attackers can inject malicious code into the build process, impacting the deployed application.
- Data Breaches: During the deployment process, sensitive data, such as credentials or configuration information, may be exposed if not properly secured. If these are not handled securely, they can lead to data breaches.
- Insider Threats: Automated deployments can be vulnerable to insider threats if access controls and monitoring are not strict. Malicious or negligent insiders could potentially manipulate the deployment process.
Security Best Practices in a CD Pipeline
Implementing security best practices is crucial for protecting the CD pipeline and the applications it deploys. These practices should be integrated into every stage of the CD process.
- Secure Access Controls: Implement strict access controls and authentication mechanisms to restrict who can access and modify the CD pipeline. Use role-based access control (RBAC) to grant users only the necessary permissions.
- Secrets Management: Securely manage secrets, such as API keys, passwords, and database credentials. Use a dedicated secrets management tool or vault to store and retrieve these secrets. Avoid hardcoding secrets in code or configuration files.
- Infrastructure as Code (IaC) Security: Secure IaC templates and configurations. Scan IaC code for vulnerabilities and misconfigurations before deployment.
- Dependency Management: Implement a robust dependency management strategy. Regularly update dependencies to patch known vulnerabilities. Use a software composition analysis (SCA) tool to identify and manage dependencies.
- Network Segmentation: Segment the network to isolate the CD pipeline and deployed applications from other parts of the infrastructure. This limits the impact of a security breach.
- Regular Security Audits: Conduct regular security audits and penetration testing to identify vulnerabilities in the CD pipeline and deployed applications.
- Immutable Infrastructure: Consider using immutable infrastructure, where servers are replaced rather than updated. This reduces the attack surface and simplifies security management.
- Automated Security Patching: Automate the patching process to ensure that security updates are applied promptly.
Integrating Security Testing into the CD Process
Integrating security testing into the CD process ensures that security vulnerabilities are identified and addressed early in the development lifecycle. This approach, often referred to as “shifting left,” helps prevent vulnerabilities from reaching production.
- Static Application Security Testing (SAST): Integrate SAST tools into the build process to analyze the source code for vulnerabilities, such as SQL injection, cross-site scripting (XSS), and buffer overflows. SAST tools analyze the code without executing it.
- Dynamic Application Security Testing (DAST): Incorporate DAST tools into the testing phase to scan the deployed application for vulnerabilities while it is running. DAST tools simulate attacks to identify weaknesses.
- Software Composition Analysis (SCA): Use SCA tools to analyze the application’s dependencies for known vulnerabilities. This helps identify and manage third-party library risks.
- Container Scanning: If using containers, scan container images for vulnerabilities before deployment. This can identify vulnerabilities in the base images and application dependencies.
- Security Testing in Production: Consider incorporating security testing into the production environment, such as penetration testing and vulnerability scanning.
- Automated Security Testing: Automate security tests as part of the build and deployment pipelines. This ensures that security checks are performed consistently and frequently.
- Threat Modeling: Conduct threat modeling exercises to identify potential threats and vulnerabilities in the application and infrastructure.
Checklist for Securing a CD Pipeline
This checklist provides a structured approach to securing a CD pipeline. Regularly reviewing and updating this checklist is essential for maintaining a secure environment.
- Access Control:
- Implement role-based access control (RBAC) for all pipeline components.
- Use multi-factor authentication (MFA) for all users.
- Regularly review and revoke access privileges.
- Use a secrets management tool or vault.
- Never hardcode secrets in code or configuration files.
- Rotate secrets regularly.
- Secure IaC templates and configurations.
- Implement network segmentation.
- Monitor infrastructure for suspicious activity.
- Use a secure build environment.
- Scan dependencies for vulnerabilities.
- Regularly update dependencies.
- Integrate SAST, DAST, and SCA into the pipeline.
- Scan container images for vulnerabilities.
- Automate security testing.
- Monitor the pipeline and deployed applications for security events.
- Implement automated rollback mechanisms.
- Regularly review logs and audit trails.
- Ensure compliance with relevant security standards.
- Conduct regular security audits.
- Maintain detailed documentation of the CD pipeline and security controls.
Conclusive Thoughts
In conclusion, automating application deployment with continuous delivery provides a robust framework for modern software development. By adopting CD principles, teams can significantly improve their software delivery processes, increase efficiency, and enhance the quality of their applications. This approach not only reduces risks but also fosters a culture of continuous improvement and innovation, allowing businesses to respond rapidly to changing market demands and deliver exceptional user experiences.
Essential Questionnaire
What is the difference between Continuous Integration (CI) and Continuous Delivery (CD)?
Continuous Integration focuses on automating the build and testing phases of the software development lifecycle, while Continuous Delivery extends this to automate the deployment process, making software releases more frequent and reliable.
What are the benefits of using a CD pipeline?
CD pipelines offer several advantages, including faster time-to-market, reduced risk of errors, improved software quality, increased team efficiency, and greater responsiveness to user feedback.
How do I choose the right deployment strategy for my application?
The best deployment strategy depends on your application’s specific needs, risk tolerance, and infrastructure. Considerations include downtime requirements, the ability to roll back changes, and the complexity of your application. Common strategies include blue/green, canary, and rolling deployments.
What tools are commonly used in a CD pipeline?
Popular tools include version control systems like Git, build automation tools like Jenkins and GitLab CI, testing frameworks, infrastructure as code tools like Terraform and Ansible, and monitoring and logging tools like Prometheus and ELK stack.