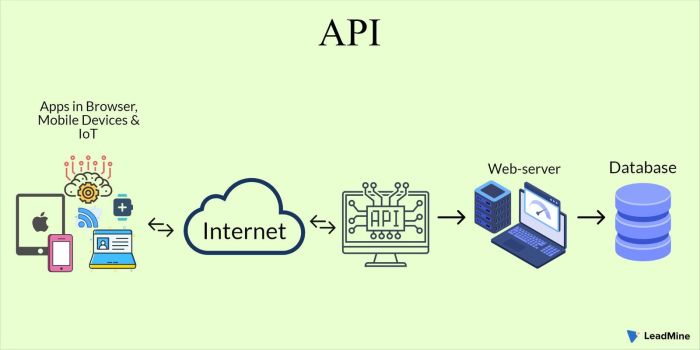
The construction of a serverless GraphQL API with AWS AppSync represents a paradigm shift in modern application development, offering scalability, cost-efficiency, and enhanced developer productivity. This approach leverages the power of GraphQL, a query language for APIs, to provide clients with the precise data they request, optimizing network usage and improving application performance. Coupled with a serverless architecture, this combination minimizes operational overhead and allows developers to focus on building features rather than managing infrastructure.
This guide delves into the intricacies of creating a robust and scalable serverless GraphQL API using AppSync, encompassing the entire lifecycle from initial setup to advanced optimization. It explores the benefits of a serverless model, details the necessary AWS services, and provides practical examples for implementing schema design, data sources, resolvers, authentication, authorization, and real-time subscriptions. The objective is to provide a comprehensive understanding of the concepts and techniques required to build a production-ready GraphQL API.
Introduction to Serverless GraphQL APIs with AppSync
Serverless GraphQL APIs, particularly when implemented with AWS AppSync, offer a compelling architecture for building scalable, efficient, and cost-effective applications. This approach leverages the benefits of serverless computing, allowing developers to focus on business logic rather than infrastructure management. The combination of GraphQL’s flexibility and AppSync’s managed services provides a powerful solution for modern API development.
Benefits of a Serverless Approach for GraphQL APIs
The serverless paradigm presents several advantages for GraphQL API development, primarily centered around operational efficiency and cost optimization. By offloading infrastructure management to a cloud provider, developers can concentrate on writing code and delivering features faster.
- Reduced Operational Overhead: Serverless architectures eliminate the need for server provisioning, maintenance, and scaling. This reduces the operational burden on development teams, freeing up resources for core product development. The cloud provider handles tasks like patching, updates, and capacity planning.
- Automatic Scalability: Serverless platforms automatically scale resources based on demand. This ensures that the API can handle fluctuating traffic loads without manual intervention. For example, during peak hours, the API will automatically scale to handle increased requests, and during off-peak hours, it will scale down to conserve resources.
- Cost Optimization: Serverless models typically follow a pay-per-use pricing structure. This means that you only pay for the compute resources consumed, which can lead to significant cost savings compared to traditional server-based deployments, especially for applications with variable workloads. For example, an e-commerce platform might see increased traffic during sales events, and the serverless API would automatically scale and only charge for the actual requests made.
- Faster Development Cycles: Serverless frameworks often offer pre-built components and integrations that streamline the development process. Developers can focus on business logic and API design, rather than spending time on infrastructure setup and configuration. This leads to faster development cycles and quicker time-to-market.
- Improved Fault Tolerance: Serverless platforms are designed with built-in fault tolerance. If one component fails, the platform automatically redirects traffic to other healthy components, ensuring high availability and minimal downtime.
Overview of AWS AppSync
AWS AppSync is a fully managed service that simplifies the creation of GraphQL APIs. It handles the complexities of building and operating a GraphQL backend, providing features such as data source integration, real-time subscriptions, and advanced security options.
- Managed GraphQL Service: AppSync provides a managed GraphQL service, which means that AWS handles the underlying infrastructure, including server provisioning, scaling, and maintenance. Developers interact with AppSync through the AWS Management Console, the AWS CLI, or SDKs.
- Data Source Integration: AppSync integrates with various data sources, including Amazon DynamoDB, AWS Lambda functions, Amazon Elasticsearch Service, and HTTP endpoints. This allows developers to easily connect their GraphQL API to different data stores and services.
- Real-time Subscriptions: AppSync supports real-time subscriptions, allowing clients to receive updates from the API in real-time. This is particularly useful for applications that require live data updates, such as chat applications, social media feeds, and dashboards.
- Security Features: AppSync offers robust security features, including authentication, authorization, and data validation. Developers can use API keys, Amazon Cognito user pools, or IAM roles to secure their APIs and control access to data.
- Offline Capabilities: AppSync provides offline capabilities, enabling users to interact with the API even when they are not connected to the internet. Data can be cached locally and synchronized with the server when the connection is restored.
Advantages of GraphQL over REST APIs in a Serverless Context
GraphQL offers several advantages over REST APIs, especially in a serverless environment, improving efficiency and developer experience. Its flexibility and efficiency make it a suitable choice for modern applications.
- Efficient Data Fetching: GraphQL allows clients to request only the data they need, reducing over-fetching and under-fetching. This results in more efficient data transfer and improved performance, especially on mobile devices or in bandwidth-constrained environments. This contrasts with REST APIs, where clients often retrieve more data than necessary, increasing the load on both the server and the client.
- Strong Typing and Schema: GraphQL uses a strong typing system and a schema, which defines the structure of the data. This enables developers to easily understand the API’s capabilities and validate data at both the client and server sides, reducing errors and improving maintainability.
- Single Endpoint: GraphQL APIs typically have a single endpoint, which simplifies the client-side code and reduces the number of API calls. This contrasts with REST APIs, which often require multiple endpoints to retrieve different types of data.
- Flexibility and Adaptability: GraphQL is highly flexible and adaptable, allowing developers to easily modify the API schema and add new features without breaking existing clients. This makes it easier to evolve the API over time and meet changing business requirements.
- Developer Experience: GraphQL offers a superior developer experience with features like introspection, which allows developers to explore the API’s schema and available data, and tooling like GraphiQL, an in-browser IDE for testing and querying GraphQL APIs.
Setting up the AWS Environment
The creation of a serverless GraphQL API using AWS AppSync necessitates a well-configured AWS environment. This involves provisioning the required AWS services, establishing appropriate Identity and Access Management (IAM) roles, and configuring the AWS Command Line Interface (CLI) for efficient management. The following sections detail the essential steps to establish this foundation.
Required AWS Services
Several AWS services are crucial for building a serverless GraphQL API with AppSync. Understanding their roles and functionalities is paramount for a successful implementation.
- AWS AppSync: AppSync acts as the central component, providing a managed GraphQL service. It handles API creation, data source integration, and real-time capabilities. AppSync allows developers to define a GraphQL schema, connect it to various data sources, and expose a unified API endpoint.
- Amazon DynamoDB: DynamoDB is a fully managed NoSQL database service that provides fast and scalable data storage. It is a popular choice for storing data accessed by AppSync APIs due to its seamless integration and performance characteristics. DynamoDB can store various data types and supports features like automatic scaling and data replication.
- AWS Lambda: Lambda enables the execution of code without managing servers. It is used as a data source for AppSync, allowing developers to integrate custom logic and interact with other AWS services. Lambda functions can be triggered by AppSync queries, mutations, and subscriptions, enabling complex data processing and business logic.
- Amazon CloudWatch: CloudWatch provides monitoring and logging capabilities for the entire infrastructure. It is used to monitor the performance of AppSync APIs, DynamoDB tables, and Lambda functions. CloudWatch allows developers to track metrics, set alarms, and troubleshoot issues.
- AWS IAM (Identity and Access Management): IAM is fundamental for managing access to AWS resources. IAM enables the creation of users, groups, and roles, each with specific permissions. This ensures that only authorized entities can access and modify the resources required for the GraphQL API.
IAM Roles and Permissions Design
IAM roles are essential for granting the necessary permissions to AWS services, enabling them to interact with each other securely. Proper IAM role design is crucial for the security and functionality of the AppSync API.
- AppSync Service Role: This role is assumed by the AppSync service itself. It requires permissions to interact with other AWS services, such as DynamoDB and Lambda, based on the defined data sources. The service role typically has the following permissions:
- Access to DynamoDB tables: Allows AppSync to read and write data to DynamoDB tables.
- Invocation of Lambda functions: Allows AppSync to invoke Lambda functions for data processing.
- Access to CloudWatch: Allows AppSync to log API metrics and errors to CloudWatch.
- Lambda Execution Role: This role is assumed by the Lambda functions that are used as data sources. It grants the Lambda functions the permissions they need to access other AWS resources, such as DynamoDB, S3, and other services. The Lambda execution role typically has the following permissions:
- Read and write access to DynamoDB tables.
- Access to other AWS services, depending on the specific function requirements.
- Logging to CloudWatch.
- DynamoDB IAM Policies: DynamoDB IAM policies control access to DynamoDB tables. These policies specify which actions are allowed on specific tables. For example, a policy might allow AppSync to read and write data to a specific DynamoDB table. Policies should follow the principle of least privilege, granting only the necessary permissions.
- Example IAM Role Policy for AppSync to access DynamoDB:
"Version": "2012-10-17", "Statement": [ "Effect": "Allow", "Action": [ "dynamodb:GetItem", "dynamodb:PutItem", "dynamodb:UpdateItem", "dynamodb:DeleteItem", "dynamodb:Query", "dynamodb:Scan" ], "Resource": "arn:aws:dynamodb:REGION:ACCOUNT_ID:table/YOUR_TABLE_NAME" ]
Creating an AWS Account and Configuring the CLI
Setting up an AWS account and configuring the AWS CLI are fundamental prerequisites for interacting with AWS services, including AppSync.
- Creating an AWS Account: The first step involves creating an AWS account. This requires providing basic information and payment details. Once the account is created, you can access the AWS Management Console and start using AWS services.
- Installing and Configuring the AWS CLI: The AWS CLI is a command-line tool that allows you to interact with AWS services from your terminal.
- Installation: Install the AWS CLI on your local machine. The installation process varies depending on your operating system. Instructions are available on the AWS documentation website.
- Configuration: Configure the AWS CLI by providing your AWS access key ID, secret access key, and the default region. You can configure the CLI using the
aws configurecommand. This command prompts for your credentials and region. - Verification: Verify the CLI configuration by running a simple command, such as
aws sts get-caller-identity. This command should return information about your IAM user or role.
- Example AWS CLI Configuration: The configuration process involves setting up the CLI with your AWS credentials and default region. The
aws configurecommand guides you through this process.$ aws configureAWS Access Key ID [None]: AKIAIOSFODNN7EXAMPLEAWS Secret Access Key [None]: wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEYDefault region name [None]: us-east-1Default output format [None]: json
Defining the GraphQL Schema

The GraphQL schema serves as the contract between the client and the server, defining the structure and capabilities of the API. It dictates the data types, queries, mutations, and subscriptions available, ensuring data consistency and enabling efficient data fetching. A well-defined schema is crucial for a robust and maintainable serverless GraphQL API, facilitating clear communication and reducing the potential for errors.
This section will explore the key components of a GraphQL schema, focusing on type definitions, relationships, best practices, and error handling.
Creating a GraphQL Schema with Example Types
A GraphQL schema is written in the GraphQL Schema Definition Language (SDL). It defines the types of data available, the operations that can be performed on that data, and the relationships between different data entities. Let’s consider a simplified example for a blog application.
First, the type definitions:
“`graphql
type User
id: ID!
username: String!
email: String
posts: [Post!]!
type Post
id: ID!
title: String!
content: String
author: User!
comments: [Comment!]!
type Comment
id: ID!
text: String!
author: User!
post: Post!
“`
The `User`, `Post`, and `Comment` types are defined. Each type has fields with specific types, such as `ID`, `String`, and `[Post!]!` (a list of `Post` objects). The exclamation mark `!` denotes a non-nullable field, meaning it must always have a value.
Next, defining the queries:
“`graphql
type Query
getUser(id: ID!): User
getPost(id: ID!): Post
listPosts: [Post!]!
“`
The `Query` type defines the operations to fetch data. `getUser` retrieves a `User` by ID, `getPost` retrieves a `Post` by ID, and `listPosts` retrieves a list of all posts.
Then, defining the mutations:
“`graphql
type Mutation
createUser(username: String!, email: String): User
createPost(title: String!, content: String!, authorId: ID!): Post
createComment(postId: ID!, authorId: ID!, text: String!): Comment
“`
The `Mutation` type defines the operations to modify data. `createUser` creates a new user, `createPost` creates a new post, and `createComment` creates a new comment.
Finally, defining the subscriptions:
“`graphql
type Subscription
newPost: Post!
newComment: Comment!
“`
The `Subscription` type defines real-time updates. `newPost` publishes a new post, and `newComment` publishes a new comment. AppSync supports subscriptions using WebSockets.
Demonstrating Handling Relationships Between Data Types
Relationships between data types are a core feature of GraphQL schemas, enabling efficient data retrieval and navigation. The example above demonstrates these relationships.
The `User` type includes a `posts: [Post!]!` field, indicating that a user can have multiple posts. This is a one-to-many relationship.
The `Post` type includes an `author: User!` field, indicating that a post has one author, who is a `User`. This is a many-to-one relationship. The `Post` also includes a `comments: [Comment!]!` field, establishing a one-to-many relationship with the `Comment` type.
The `Comment` type includes `author: User!` and `post: Post!` fields, representing many-to-one relationships back to the `User` and `Post` types, respectively.
Consider the following GraphQL query:
“`graphql
query
getUser(id: “user123”)
id
username
posts
id
title
“`
This query retrieves a user and all of their posts. The GraphQL server, such as AppSync, uses the relationships defined in the schema to fetch the related data efficiently. It knows to retrieve the posts associated with the specified user ID.
Providing Examples of Schema Best Practices
Schema best practices are essential for building a maintainable and robust GraphQL API. This includes error handling, data validation, and code organization.
- Error Handling: GraphQL provides built-in error handling mechanisms. Errors are returned in the `errors` field of the response. Custom error types and handling can be implemented to provide more specific error information. For example:
“`graphql
type Query
getUser(id: ID!): User
getPost(id: ID!): Post
listPosts: [Post!]!
searchPosts(searchTerm: String!): [Post!]!
type User
id: ID!
username: String!
email: String
posts: [Post!]!
type Post
id: ID!
title: String!
content: String
author: User!
comments: [Comment!]!
errors: [Error!]
type Comment
id: ID!
text: String!
author: User!
post: Post!
type Error
message: String!
code: String!
“`
The `Post` type includes an `errors` field. If a post cannot be retrieved due to an error, the error information can be added to this field. This allows clients to handle errors more gracefully.
- Data Validation: Input validation ensures data integrity. This can be done within the schema using directives or through resolvers. Directives can enforce constraints. For example, a directive could ensure that the title length is within specific limits.
“`graphql
directive @maxLength(length: Int!) on FIELD_DEFINITION
type Post
id: ID!
title: String! @maxLength(length: 255)
content: String
author: User!
comments: [Comment!]!
“`
In this example, the `@maxLength` directive is used to validate the `title` field. The implementation of this directive is done at the resolver level.
- Code Organization: Organizing the schema into smaller, reusable modules can improve maintainability. This can be achieved by using separate schema files and combining them during deployment. Also, using interfaces and unions can help in managing and scaling the schema effectively.
Configuring Data Sources (DynamoDB, Lambda, etc.)
Configuring data sources is a critical step in building a serverless GraphQL API with AppSync. This involves connecting your GraphQL schema to various AWS services that will store and manage your data. The choice of data sources depends on the specific requirements of your application, including data storage needs, processing logic, and scalability requirements. AppSync offers seamless integration with several AWS services, allowing you to leverage the power and flexibility of the cloud.
Integrating DynamoDB as a Data Source
DynamoDB is a fully managed NoSQL database service that provides fast and predictable performance with seamless scalability. Integrating DynamoDB as a data source for AppSync is a common and efficient approach for storing and retrieving data.
The process involves these key steps:
- Creating a DynamoDB Table: Before configuring AppSync, you must create a DynamoDB table to store your data. Define the primary key and any secondary indexes based on your data access patterns. For example, a table to store user profiles might have a primary key of `userId` and an optional secondary index for `email`.
- Configuring the AppSync Data Source: Within the AppSync console, navigate to the “Data Sources” section and select “Create Data Source.” Choose “DynamoDB” as the data source type. Specify the following:
- Data source name: A descriptive name for the data source.
- Region: The AWS region where your DynamoDB table is located.
- Table name: The name of the DynamoDB table you created.
- IAM role: An IAM role that grants AppSync the necessary permissions to access your DynamoDB table. AppSync can create this role for you, or you can use an existing one. The role must have permissions to perform actions like `dynamodb:GetItem`, `dynamodb:PutItem`, `dynamodb:UpdateItem`, and `dynamodb:DeleteItem` on the DynamoDB table.
- Attaching Resolvers to GraphQL Fields: Once the data source is configured, you must attach resolvers to the corresponding GraphQL fields in your schema. Resolvers are the bridge between your GraphQL schema and the data source. They define how AppSync translates GraphQL queries and mutations into operations on your DynamoDB table. For example, a `getUser` query in your schema might be resolved by a DynamoDB resolver that performs a `GetItem` operation on the `users` table, using the `userId` provided in the query as the key.
- Writing Resolver Mapping Templates: Resolvers use mapping templates, written in Apache Velocity Template Language (VTL), to transform the GraphQL request into a format that DynamoDB understands (request mapping template) and to transform the DynamoDB response into a format that GraphQL understands (response mapping template). The request mapping template typically constructs the DynamoDB query parameters, such as the `Key` for a `GetItem` operation. The response mapping template extracts the data from the DynamoDB response and formats it for the GraphQL client.
Example: A simple request mapping template for a `GetItem` operation might look like this:
"version" : "2018-05-29",
"operation" : "GetItem",
"key" :
"id" :
"S" : "$ctx.args.id"This template constructs a `GetItem` request to DynamoDB, using the `id` argument passed in the GraphQL query as the key.
Setting up a Lambda Function to Handle Complex Business Logic
AWS Lambda allows you to run code without provisioning or managing servers. Integrating Lambda functions with AppSync enables you to handle complex business logic, perform data transformations, and integrate with other AWS services.
The setup involves these steps:
- Creating a Lambda Function: Create a Lambda function in the AWS Lambda console. Choose a runtime environment that supports your preferred programming language (e.g., Node.js, Python, Java). The function’s code will contain the business logic that you want to execute. For example, a Lambda function could be responsible for validating user input, performing calculations, or interacting with external APIs.
- Configuring the Lambda Function’s Permissions: The Lambda function requires appropriate permissions to access other AWS services or resources it needs to interact with. Create an IAM role for the Lambda function that grants it the necessary permissions. For example, if the function needs to read data from a DynamoDB table, the role must have `dynamodb:GetItem` and other relevant permissions.
- Configuring the AppSync Data Source: In the AppSync console, create a new data source of type “AWS Lambda.” Specify the following:
- Data source name: A descriptive name for the data source.
- Region: The AWS region where your Lambda function is located.
- Lambda function: Select the Lambda function you created.
- IAM role: An IAM role that grants AppSync the necessary permissions to invoke the Lambda function. AppSync can create this role for you, or you can use an existing one. This role must have permissions to invoke the Lambda function (e.g., `lambda:InvokeFunction`).
- Attaching Resolvers to GraphQL Fields: Similar to DynamoDB, you need to attach resolvers to your GraphQL schema fields to invoke the Lambda function. These resolvers will map the GraphQL request to the Lambda function’s input and transform the Lambda function’s response into a GraphQL-compatible format.
- Writing Resolver Mapping Templates: Resolver mapping templates are crucial for the interaction between AppSync and the Lambda function.
- Request Mapping Template: This template transforms the GraphQL request into a format that the Lambda function expects. It typically includes the arguments passed in the GraphQL query or mutation.
Example: A simple request mapping template for a mutation to create a user might look like this:
"version": "2018-05-29",
"operation": "Invoke",
"payload":
"name": "$ctx.args.name",
"email": "$ctx.args.email"This template passes the `name` and `email` arguments from the GraphQL mutation to the Lambda function as the payload.
- Response Mapping Template: This template transforms the Lambda function’s response into a format that can be returned to the GraphQL client. It typically extracts the relevant data from the Lambda function’s response and formats it for the GraphQL response.
Example: A simple response mapping template might look like this:
#if($ctx.error)
$util.error($ctx.error.message, $ctx.error.type)
#end
$util.toJson($ctx.result)
This template checks for errors and returns the result from the Lambda function in JSON format.
- Request Mapping Template: This template transforms the GraphQL request into a format that the Lambda function expects. It typically includes the arguments passed in the GraphQL query or mutation.
Connecting Other AWS Services (e.g., S3, RDS) as Data Sources
AppSync supports integration with various other AWS services, including S3 (Simple Storage Service) for storing and retrieving files and RDS (Relational Database Service) for interacting with relational databases.
The process for each service differs slightly but generally follows a similar pattern:
- Configuring the Data Source: In the AppSync console, create a data source for the specific service. The configuration options will vary depending on the service. For example, when configuring an S3 data source, you’ll need to specify the S3 bucket name and the IAM role that grants AppSync access to the bucket. When configuring an RDS data source, you’ll need to provide the database endpoint, database name, and credentials.
- Attaching Resolvers to GraphQL Fields: As with other data sources, you need to attach resolvers to your GraphQL schema fields. These resolvers will translate GraphQL queries and mutations into operations on the chosen service.
- Writing Resolver Mapping Templates: Resolver mapping templates are essential for interacting with these services.
- S3: For S3, the request mapping template would construct the API calls (e.g., `getObject`, `putObject`) and specify the bucket and key. The response mapping template would extract the data from the S3 response.
Example: An S3 request mapping template for retrieving an object might look like this:
"version": "2018-05-29",
"operation": "GetObject",
"bucket": "your-s3-bucket-name",
"key": "$ctx.args.key" - RDS: For RDS, the request mapping template would construct SQL queries to interact with the database. The response mapping template would transform the database results into a GraphQL-compatible format.
Example: An RDS request mapping template for a `SELECT` query might look like this:
"version": "2018-05-29",
"statements": [
"SELECT
- FROM users WHERE id = :id",
],
"variableMap":
":id": "$ctx.args.id"
- S3: For S3, the request mapping template would construct the API calls (e.g., `getObject`, `putObject`) and specify the bucket and key. The response mapping template would extract the data from the S3 response.
- IAM Role Permissions: Ensure the IAM role associated with the AppSync data source has the necessary permissions to access the other AWS services. For example, the role must have `s3:GetObject` and `s3:PutObject` permissions to interact with S3 or `rds:Connect` and other relevant permissions to interact with RDS.
Implementing Resolvers
Resolvers are the crucial link between your GraphQL schema and the underlying data sources. They define how your API fetches, processes, and returns data in response to client queries and mutations. Properly implemented resolvers are essential for the performance, security, and overall functionality of your serverless GraphQL API. They handle the complexity of interacting with various AWS services, transforming data as needed, and providing a seamless experience for your API consumers.
Understanding the different resolver types and their applications is fundamental to building a robust AppSync API. The choice of resolver type depends on the complexity of the operation and the nature of the data source. This section will explore the implementation of resolvers, demonstrating the use of different resolver types and providing concrete examples for common GraphQL operations.
Resolver Types and Their Applications
The choice of resolver type is critical for optimizing performance and managing complexity. AppSync offers different resolver types, each suited for specific scenarios.
- Direct Resolvers: These resolvers directly interact with a single data source. They are the simplest type and are suitable for operations where minimal data transformation is required. Direct resolvers are configured directly within the AppSync console, mapping incoming GraphQL fields to specific operations in the data source.
- Pipeline Resolvers: Pipeline resolvers provide a more flexible and powerful approach. They consist of multiple functions that execute sequentially. Each function can perform a specific task, such as data transformation, authorization, or interaction with other AWS services. Pipeline resolvers are ideal for complex operations that require multiple steps. They offer a structured way to orchestrate the execution flow, enhancing the API’s modularity and maintainability.
- Lambda Resolvers: Lambda resolvers use AWS Lambda functions to process requests. This approach allows for custom logic, data manipulation, and integration with other AWS services or third-party APIs. Lambda resolvers are particularly useful when the data source requires complex business logic or when the API needs to interact with external systems. The Lambda function receives the request context, allowing it to access information about the user, the query, and the data source.
Creating Resolvers for Queries and Mutations
Resolvers are defined within the AppSync console, mapping GraphQL fields to data source operations. The process involves specifying the data source, the operation type (e.g., GetItem, PutItem, Scan for DynamoDB), and any necessary request and response mapping templates.
- Query Resolvers: Query resolvers handle read operations, retrieving data from the data source. They map GraphQL query fields to the corresponding data source operations, such as `GetItem` or `Scan` for DynamoDB. The resolver’s request mapping template constructs the request to the data source, while the response mapping template transforms the data source response into the GraphQL response format.
- Mutation Resolvers: Mutation resolvers handle write operations, modifying data in the data source. They map GraphQL mutation fields to operations like `PutItem`, `UpdateItem`, or `DeleteItem` for DynamoDB. The request mapping template constructs the request to the data source, including the data to be written or modified. The response mapping template transforms the data source response into the GraphQL response format, often including the updated data.
Example Resolver Code for Various Operations
The following examples illustrate how to implement resolvers for common GraphQL operations using DynamoDB as the data source. These examples demonstrate both direct and pipeline resolver approaches.
- Create Operation (Direct Resolver):
This example demonstrates a direct resolver for a `createTodo` mutation that adds a new item to a DynamoDB table. The request mapping template is configured to construct the `PutItem` request.
Request Mapping Template (Velocity Template Language – VTL):
"version" : "2018-05-29", "operation" : "PutItem", "key" : "id" : "S" : "$util.autoId()" , "attributeValues" : "title" : "S" : "$ctx.args.input.title" , "description" : "S" : "$ctx.args.input.description" , "completed" : "BOOL": false
Response Mapping Template:
$util.toJson($ctx.result)
- Read Operation (Direct Resolver):
This example shows a direct resolver for a `getTodo` query, retrieving a single item from the DynamoDB table based on its ID. The request mapping template is configured to construct the `GetItem` request.
Request Mapping Template (VTL):
"version" : "2018-05-29", "operation" : "GetItem", "key" : "id" : "S" : "$ctx.args.id"
Response Mapping Template:
$util.toJson($ctx.result)
- Update Operation (Direct Resolver):
This example shows a direct resolver for an `updateTodo` mutation, updating an item in the DynamoDB table. The request mapping template is configured to construct the `UpdateItem` request.
Request Mapping Template (VTL):
"version" : "2018-05-29", "operation" : "UpdateItem", "key" : "id" : "S" : "$ctx.args.input.id" , "update" : "expression" : "SET #title = :title, #description = :description, #completed = :completed", "expressionNames" : "#title" : "title", "#description" : "description", "#completed" : "completed" , "expressionValues" : ":title" : "S" : "$ctx.args.input.title" , ":description" : "S" : "$ctx.args.input.description" , ":completed" : "BOOL": $ctx.args.input.completed
Response Mapping Template:
$util.toJson($ctx.result)
- Delete Operation (Direct Resolver):
This example demonstrates a direct resolver for a `deleteTodo` mutation, deleting an item from the DynamoDB table. The request mapping template is configured to construct the `DeleteItem` request.
Request Mapping Template (VTL):
"version" : "2018-05-29", "operation" : "DeleteItem", "key" : "id" : "S" : "$ctx.args.id"
Response Mapping Template:
$util.toJson($ctx.result)
Authentication and Authorization
Securing a serverless GraphQL API built with AWS AppSync is paramount to protecting sensitive data and ensuring only authorized users can access it. This involves two critical processes: authentication, which verifies the identity of a user, and authorization, which determines what resources a user is permitted to access. AppSync offers a variety of methods for implementing both, providing flexibility in meeting diverse security requirements.
Authentication Methods
Authentication confirms a user’s identity. AppSync supports several authentication methods, each with its strengths and weaknesses, allowing for tailoring to specific application needs. Choosing the right method depends on the application’s security posture, user base, and integration requirements.
- API Keys: This is the simplest method, primarily intended for development and testing. Each request includes an API key, and AppSync validates the key against a pre-configured list. While easy to implement, API keys are not ideal for production environments due to their lack of user identity management and vulnerability to exposure.
- IAM Roles: This leverages AWS Identity and Access Management (IAM) roles, providing a robust and secure authentication mechanism. Users assume an IAM role, granting them access to AWS resources based on the role’s permissions. This is particularly suitable for service-to-service communication or when integrating with other AWS services. The identity is implicitly trusted by the AWS environment.
- Amazon Cognito: Cognito is a fully managed service for user authentication, authorization, and user management. It provides features such as user sign-up, sign-in, multi-factor authentication (MFA), and social identity providers (e.g., Facebook, Google). Cognito is a recommended choice for applications that require user-facing authentication, offering a seamless user experience and robust security features. Using Cognito with AppSync allows for fine-grained control over user access based on Cognito user groups or attributes.
- OpenID Connect (OIDC): OIDC is an authentication layer built on top of OAuth 2.0. AppSync can be configured to use OIDC providers such as Okta, Auth0, or other compatible services. This allows users to authenticate using their existing accounts from these providers. This is a flexible approach for integrating with third-party identity providers, enabling centralized user management and single sign-on (SSO) capabilities.
Authorization Rules Design
Authorization defines what resources a user can access. AppSync’s authorization capabilities are crucial for implementing secure access control. Implementing authorization involves defining rules that dictate which users or groups of users are allowed to perform specific operations (queries, mutations, subscriptions) on specific data.
A well-designed authorization system is critical for data integrity and security. It should consider various factors, including user roles, data sensitivity, and compliance requirements. The authorization rules are typically defined within the GraphQL schema, enabling AppSync to enforce them automatically during request processing. AppSync allows different authorization strategies, and they can be combined to achieve the desired level of control.
Consider a scenario where a medical application needs to control access to patient records, the authorization rules should be designed to ensure that only authorized medical personnel (doctors, nurses) can access patient data, and access is restricted based on the user’s role and the relationship to the patient.
- Authorization Modes: AppSync offers different authorization modes that control how access is managed:
- API Key: As previously mentioned, this is a basic mode and not suitable for complex authorization scenarios. It allows access based on the presence of a valid API key.
- IAM: Allows access based on the IAM role assumed by the user. This is suitable for server-to-server communication or when users assume an IAM role.
- Amazon Cognito User Pools: Enables access control based on Cognito user pools. You can specify the user pool and user groups allowed to access specific operations.
- OpenID Connect: Allows access control based on OIDC tokens and claims. You can specify the claims (e.g., roles) required for access.
- Multiple Authorization Types: AppSync allows the use of multiple authorization types simultaneously. This provides flexibility. For example, you could use Cognito User Pools for authenticated users and API keys for public access to read-only data.
- Authorization Directives: Authorization directives are added to the GraphQL schema to define access control rules. These directives specify the authorization mode and, optionally, the user groups or roles allowed to access a specific field or operation. For example, the
@authdirective can be used to specify that a mutation is only accessible to users in a particular Cognito user group. - Example Schema with Authorization:
Here’s an example of how to use authorization directives in a GraphQL schema to control access to a ‘Patient’ type.
type Patient @model @auth(rules: [ allow: groups, groups: ["doctors"] , allow: groups, groups: ["nurses"], operations: [read] , allow: owner ]) id: ID! name: String! medicalHistory: String owner: StringIn this example:
- The
@authdirective specifies authorization rules. - The first rule allows users in the “doctors” group to access all operations (create, read, update, delete).
- The second rule allows users in the “nurses” group to only read the patient information.
- The third rule allows the owner of the patient record to access all operations (owner-based authorization).
- The
Implementing Fine-Grained Access Control
Fine-grained access control enables precise control over data access, based on user roles, attributes, or relationships. AppSync supports various methods for implementing fine-grained access control, enabling you to tailor access permissions to meet specific requirements.
The goal is to ensure that users only have access to the data they are authorized to view or modify. This can involve checking user roles, data ownership, or other criteria within resolvers or schema directives. Consider a social media application where users should only be able to view posts from their friends and themselves. Fine-grained access control would be required to implement this functionality, ensuring data privacy and a personalized user experience.
This might involve checking the relationship between the requesting user and the post’s author within the resolver before returning the post data.
- Cognito User Groups: Using Cognito user groups is a common approach. Users are assigned to groups based on their roles or responsibilities. The authorization rules in the GraphQL schema can then specify which user groups are allowed to access specific operations or data. For example, a “doctors” group could have access to sensitive patient data, while a “patients” group only has access to their own data.
- Owner-Based Authorization: Owner-based authorization is suitable when data has an owner (e.g., a user who created the data). The authorization rules can check the owner field in the data against the user’s identity. AppSync provides the
@authdirective with theownersetting to simplify this process. - Custom Resolvers: Resolvers are the functions that fetch data from data sources (e.g., DynamoDB, Lambda). You can implement custom logic within resolvers to perform fine-grained access control. This allows you to check user roles, attributes, or other conditions before returning data. For example, you could check the user’s role in a Lambda resolver before fetching data from a database.
For example, if you are using a Lambda resolver to fetch patient data, you could check the user’s role retrieved from Cognito or IAM, and if the user is not authorized, return an error or filter the data.
- Schema Directives with Custom Logic: While AppSync provides built-in directives like
@auth, you can also create custom schema directives to encapsulate complex authorization logic. This allows you to reuse authorization rules across multiple fields and operations. Custom directives can call custom Lambda functions or other services to perform authorization checks. - Data Filtering: In resolvers, you can filter data based on user attributes or roles. For example, when retrieving a list of items, you could filter the results to only include items that the user is authorized to view. This can be particularly useful when combined with owner-based authorization or role-based access control.
Implementing Subscriptions

GraphQL subscriptions provide a mechanism for real-time updates from a GraphQL API. AppSync facilitates the implementation of subscriptions, enabling clients to receive data changes as they occur. This is achieved through WebSockets, providing a persistent connection between the client and the server.
Real-time Updates with GraphQL Subscriptions
GraphQL subscriptions differ from queries and mutations. While queries fetch data and mutations modify data, subscriptions enable clients to subscribe to specific events and receive updates whenever those events occur. These updates are pushed from the server to the client in real-time, without the client having to repeatedly poll for changes.
- Mechanism: AppSync utilizes WebSockets to maintain a persistent connection between clients and the server. When a subscription is established, the server monitors for events that match the subscription’s criteria. Upon the occurrence of a matching event, the server pushes the updated data to the subscribed clients.
- Data Transfer: The data transmitted through subscriptions is typically a subset of the overall data, specifically the parts that have changed. This efficient data transfer minimizes bandwidth usage and improves the responsiveness of the application.
- Implementation: Subscriptions are defined in the GraphQL schema alongside queries and mutations. Resolvers are then configured to trigger the subscriptions when relevant events occur, such as data creation, updates, or deletions.
Subscribing to Data Changes in Real-time
Subscribing to data changes involves defining the subscription in the GraphQL schema and then implementing resolvers to publish updates when the underlying data changes. This process ensures that clients receive immediate notifications of modifications to the data they are interested in.
- Schema Definition: The GraphQL schema includes a `type Subscription` which defines the available subscription operations. These operations specify the data that clients can subscribe to and the events that trigger updates.
- Resolver Implementation: Resolvers for subscriptions are responsible for publishing data changes. They typically interact with data sources (e.g., DynamoDB, Lambda functions) and notify AppSync of the changes.
- Client-Side Subscription: Clients use GraphQL clients (e.g., Apollo Client, Relay) to establish a WebSocket connection to the AppSync endpoint and subscribe to specific subscriptions. The client specifies the subscription query and receives real-time updates whenever the subscribed event occurs.
Examples of Subscription Use Cases
Subscriptions are particularly useful in applications where real-time data updates are crucial for a good user experience. They enhance user engagement and provide timely information, enhancing the functionality of numerous applications.
- Chat Applications: In a chat application, subscriptions can be used to receive real-time updates about new messages. When a user sends a message, a mutation creates the message in the database, and the resolver triggers a subscription to notify all relevant users. The client then receives the new message and displays it in the chat window.
- Real-time Dashboards: Dashboards that display real-time metrics, such as stock prices or sensor readings, can utilize subscriptions. As the data changes, the server pushes the updated information to the clients, ensuring the dashboard remains up-to-date.
- Gaming Applications: In multiplayer games, subscriptions can be used to synchronize game state updates between players. When a player moves, attacks, or performs any other action, a mutation triggers a subscription that updates the game state for all other players. This provides a seamless and responsive gaming experience.
- Social Media Feeds: Subscriptions can be employed to update social media feeds in real time. When a new post is created, or a comment is added, a subscription notifies the relevant users, allowing them to view the updated feed without manual refresh.
Testing the API
Thorough testing is crucial for ensuring the reliability, performance, and security of a serverless GraphQL API built with AWS AppSync. Testing validates that the API functions as designed, handles errors gracefully, and meets the specified requirements. Different testing methodologies, ranging from manual exploration to automated suites, are employed to cover various aspects of the API’s behavior. Effective testing identifies potential issues early in the development cycle, reducing the risk of production failures and improving the overall user experience.
Methods for Testing the GraphQL API
Several methods can be employed to test a GraphQL API built with AppSync. The choice of method depends on the complexity of the API, the desired level of testing, and the available resources.
- AppSync Console: The AppSync console provides a built-in query editor for directly interacting with the API. This allows developers to manually test queries and mutations by entering GraphQL operations and viewing the responses. This is particularly useful for quickly validating the schema and resolvers. The console also supports the execution of subscriptions, enabling real-time testing of data updates.
- Postman or Similar API Clients: Postman, Insomnia, and other API client tools offer a more advanced environment for testing. These tools allow users to create and save collections of GraphQL requests, manage environment variables, and automate test execution. They provide features like request history, response validation, and the ability to organize tests into logical groups. These are beneficial for creating reusable test suites and simulating various user scenarios.
- GraphQL Playground: GraphQL Playground is a browser-based IDE for exploring, testing, and documenting GraphQL APIs. It offers features like auto-completion, schema documentation, and the ability to visually inspect the data returned by queries. It’s a convenient tool for developers to understand and experiment with the API’s functionality.
- Command-Line Tools (e.g., `curl`, `wscat`): Command-line tools like `curl` can be used to send raw HTTP requests to the AppSync endpoint. This approach allows for fine-grained control over the request headers and payload. `wscat` can be used to test subscriptions by connecting to the WebSocket endpoint and sending and receiving messages. This is helpful for verifying the API’s behavior under different network conditions or security protocols.
- Testing Libraries and Frameworks (e.g., Jest, Mocha): For automated testing, developers can leverage testing libraries and frameworks like Jest or Mocha in conjunction with GraphQL client libraries (e.g., `graphql-request`). These frameworks allow developers to write unit and integration tests that verify the functionality of resolvers, data sources, and other API components. These tools support test-driven development (TDD) and behavior-driven development (BDD) methodologies.
Testing Different Query Types and Mutations
Testing should encompass a range of query types and mutations to ensure the API behaves as expected under various scenarios. Different test cases are created to validate data retrieval, modification, and error handling.
- Queries: Queries are used to retrieve data from the API. Testing queries involves verifying that the correct data is returned, that the data is in the expected format, and that the API handles various filtering and pagination parameters correctly. For instance, if a query retrieves a list of items, tests should confirm that:
- The correct number of items is returned.
- Items are returned in the expected order.
- Filtering based on specific criteria works as expected.
- Pagination (e.g., using `limit` and `offset` or cursor-based pagination) functions correctly.
- Mutations: Mutations are used to modify data in the API. Testing mutations involves verifying that data is correctly created, updated, or deleted. Tests should cover various scenarios, including:
- Creating new items.
- Updating existing items.
- Deleting items.
- Handling validation errors (e.g., required fields missing, invalid data types).
- Verifying that the data source (e.g., DynamoDB) is updated correctly.
- Subscriptions: Subscriptions enable real-time updates. Testing subscriptions involves verifying that clients receive the correct updates when data changes. This includes:
- Verifying that clients receive updates when new items are created.
- Verifying that clients receive updates when existing items are updated.
- Verifying that clients receive updates when items are deleted.
- Testing the behavior of subscriptions under different network conditions (e.g., network latency, disconnections).
- Error Handling: Tests should verify that the API handles errors gracefully. This includes:
- Testing error responses for invalid input (e.g., incorrect data types, missing required fields).
- Testing error responses for authorization failures (e.g., unauthorized access to resources).
- Testing error responses for data source failures (e.g., DynamoDB errors).
- Verifying that error messages are informative and helpful for debugging.
Strategies for Automating API Testing
Automating API testing improves efficiency, reliability, and maintainability. Automation involves writing scripts or using specialized tools to execute tests automatically.
- Test Frameworks and Libraries: Use testing frameworks like Jest or Mocha. These frameworks provide features like test runners, assertion libraries, and reporting tools. GraphQL client libraries, such as `graphql-request` or `@apollo/client`, can be used to send GraphQL requests from within the tests.
- Test Suites: Organize tests into logical test suites based on functionality or API endpoints. This allows for better organization and easier execution of tests. For example, create a test suite for queries, a test suite for mutations, and a test suite for subscriptions.
- Data Setup and Teardown: Implement data setup and teardown procedures to prepare the environment for each test and clean up after the test is complete. This ensures that tests are independent and do not interfere with each other.
For example, before a test that creates a new item, the setup procedure might create a clean database. After the test, the teardown procedure might delete the created item.
- Environment Variables: Use environment variables to configure the API endpoint, authentication credentials, and other test-specific settings. This allows tests to be run in different environments (e.g., development, staging, production) without modifying the test code.
- Continuous Integration/Continuous Delivery (CI/CD): Integrate automated tests into a CI/CD pipeline. This allows tests to be executed automatically whenever code changes are pushed to the repository. This helps catch bugs early and ensures that the API is always in a deployable state.
For instance, a CI/CD pipeline could be configured to run automated tests every time a pull request is created. If any tests fail, the pull request would be blocked from merging until the issues are resolved.
- Mocking and Stubbing: Use mocking and stubbing techniques to isolate components and test them independently. This is particularly useful for testing resolvers that interact with external services or data sources.
For example, to test a resolver that calls an external API, you could mock the API call and return predefined data. This allows you to test the resolver’s logic without actually making a call to the external API.
- Test Reporting and Analysis: Implement test reporting to track test results and identify areas for improvement. Test reports provide information on the number of tests passed, failed, and skipped, as well as the time it took to run the tests. Analyze the test results to identify patterns of failures, performance bottlenecks, and areas where more tests are needed.
Deploying and Managing the API
Deploying and managing a serverless GraphQL API built with AWS AppSync is crucial for ensuring its availability, performance, and scalability in a production environment. This involves several key steps, from initial deployment to ongoing monitoring and optimization. Effective management allows for efficient resource utilization, cost control, and the ability to adapt to changing user demands.
Deploying to a Production Environment
Deploying the AppSync API to a production environment involves a series of steps to ensure a smooth transition and minimize downtime. This process leverages AWS services like CloudFormation and the AWS Management Console.
- API Creation and Configuration: The AppSync API is initially created and configured, including defining the schema, data sources (e.g., DynamoDB, Lambda), and resolvers. This configuration is often managed through the AWS Management Console or infrastructure-as-code tools like CloudFormation or the AWS CLI.
- Environment Variables and Secrets Management: Securely store and manage sensitive information, such as API keys, database credentials, and other configuration parameters. AWS Secrets Manager or AWS Systems Manager Parameter Store are commonly used for this purpose. This prevents hardcoding sensitive information in your resolvers or application code.
- Deployment using CloudFormation (Recommended): CloudFormation allows for infrastructure-as-code, making the deployment process repeatable and version-controlled. The AppSync API, along with its associated resources, is defined in a CloudFormation template (YAML or JSON). The template is then used to create or update the API stack. This is generally the preferred approach for production deployments because it provides a robust mechanism for managing infrastructure changes and rollbacks.
- Testing and Validation: Thoroughly test the API after deployment. Use tools like Postman, Insomnia, or the AppSync console to validate the API’s functionality, performance, and security. Ensure that all queries, mutations, and subscriptions work as expected. This step involves both functional testing and performance testing to assess API responsiveness under various load conditions.
- DNS and Domain Configuration (Optional): If a custom domain is required, configure the DNS records to point to the AppSync API endpoint. Use Route 53 or another DNS provider to manage the DNS settings. This enables users to access the API via a custom domain name.
- Monitoring and Logging: Configure monitoring and logging using CloudWatch. Set up alarms to detect and respond to issues such as high error rates, latency, or throttling. Regularly review logs to identify and troubleshoot issues. This step is crucial for maintaining API health and performance.
Monitoring API Performance with CloudWatch Metrics
Monitoring the API’s performance is essential for identifying and addressing potential issues, optimizing resource utilization, and ensuring a positive user experience. AWS CloudWatch provides a comprehensive set of metrics for AppSync APIs.
CloudWatch metrics offer insights into several key aspects of API performance. They include:
- Request Count: The number of API requests received.
- Latency: The time taken to process API requests, from request to response.
- Error Rate: The percentage of API requests that result in errors.
- Throttling: The number of requests throttled due to rate limiting.
- Data Transfer: The amount of data transferred in and out of the API.
To monitor API performance effectively, set up CloudWatch dashboards and alarms. Create dashboards that visualize key metrics over time. Configure alarms to trigger notifications when metrics exceed predefined thresholds. For example, an alarm can be set to trigger when the error rate exceeds a certain percentage or when latency increases beyond an acceptable level.
Example: A company uses a serverless GraphQL API for its e-commerce platform. They observe a sudden spike in API latency during peak hours. By monitoring CloudWatch metrics, they identify that the increase in latency is correlated with a surge in the number of concurrent users. This allows them to quickly address the issue by scaling their resources or optimizing their resolvers to handle the increased load.
This proactive approach ensures a seamless user experience, even during periods of high traffic.
Scaling and Optimizing the API
Scaling and optimizing the API are crucial for handling high traffic, maintaining performance, and controlling costs. Several strategies can be employed to achieve this.
- Caching: Implement caching to reduce the load on backend resources and improve response times. AppSync supports caching at the resolver level, which allows for caching of specific data or results. The cache can be configured to store data for a specified time, reducing the need to fetch data from the data sources for frequently accessed information.
- Data Source Optimization: Optimize the data sources, such as DynamoDB tables or Lambda functions, to improve performance. For DynamoDB, use appropriate indexing strategies and consider the use of DynamoDB Accelerator (DAX) for caching. For Lambda functions, optimize the code, increase memory allocation, and use provisioned concurrency to minimize cold starts.
- Rate Limiting: Implement rate limiting to protect the API from abuse and ensure fair usage. AppSync supports rate limiting at the API level, allowing for the configuration of request limits per API key or user. This prevents individual users from consuming excessive resources and impacting other users.
- Schema Optimization: Optimize the GraphQL schema to reduce the complexity of queries and mutations. Avoid over-fetching data by only requesting the fields that are needed. Use pagination to handle large datasets efficiently.
- Resource Allocation: Carefully allocate resources, such as memory and compute capacity, to the data sources and resolvers. Monitor resource utilization and adjust the allocation as needed to meet the demands of the API. Consider using auto-scaling features to dynamically adjust resources based on traffic patterns.
- Load Testing: Conduct load testing to simulate realistic traffic scenarios and identify performance bottlenecks. Use tools like JMeter or Gatling to simulate a high volume of requests and measure the API’s performance under load. This helps in identifying areas that need optimization.
Example: A social media platform uses a serverless GraphQL API for its mobile app. During a major product launch, they anticipate a significant increase in user traffic. To prepare for this, they implement several optimization strategies. They enable caching for frequently accessed data, such as user profiles and posts. They optimize their DynamoDB tables by implementing appropriate indexing strategies.
They set up rate limiting to prevent abuse. They also perform load testing to simulate the anticipated traffic volume. As a result, the API remains responsive and performs well during the product launch, providing a seamless user experience despite the surge in traffic. This demonstrates the importance of proactive optimization for handling high traffic and ensuring API stability.
Advanced Topics and Best Practices
Serverless GraphQL APIs built with AWS AppSync offer significant advantages in scalability, maintainability, and cost-effectiveness. However, to fully leverage these benefits, it’s crucial to understand advanced topics and adhere to best practices. This section delves into crucial areas like pagination, filtering, caching, and client-side library integration, providing practical guidance for building robust and performant GraphQL APIs.
Pagination and Filtering in GraphQL Queries
Efficiently managing large datasets is essential for any GraphQL API. Pagination and filtering are fundamental techniques to achieve this, allowing clients to retrieve data in manageable chunks and refine results based on specific criteria. Implementing these features enhances the API’s performance and user experience.
- Pagination Strategies: Pagination enables clients to request data in pages, preventing overwhelming the server and improving response times. Two primary strategies are commonly employed:
- Offset-based Pagination: This approach uses `limit` and `offset` parameters to specify the number of items to retrieve and the starting position.
- Cursor-based Pagination: Also known as keyset pagination, this method uses a cursor (typically an ID or timestamp) to indicate the starting point for the next page.
- Filtering Techniques: Filtering allows clients to refine data based on specific criteria, such as s, categories, or dates. This enhances the flexibility and usefulness of the API.
- Direct Field Filtering: The most straightforward approach involves adding filter parameters directly to the GraphQL query.
- Complex Filtering with Input Types: For more complex filtering scenarios, define input types in the GraphQL schema to encapsulate filtering criteria.
- Best Practices for Pagination and Filtering:
- Schema Design: Carefully design the GraphQL schema to include pagination and filtering capabilities. Use clear and consistent naming conventions.
- Performance Optimization: Optimize database queries to efficiently handle pagination and filtering. Consider using indexes and query optimization techniques.
- User Experience: Provide clear and intuitive pagination controls (e.g., “next,” “previous” buttons, page numbers) in the client application.
- Error Handling: Implement robust error handling to gracefully manage invalid filter parameters or pagination requests.
Example:
query
getProducts(limit: 10, offset: 20)
id
name
description
Here, `limit` is set to 10, and `offset` to 20, meaning the API should return 10 products, starting from the 21st product.
Pros: Relatively simple to implement.
Cons: Inefficient for large datasets as the server must process all preceding records. Performance degrades with increasing `offset` values.
Example:
query
getProducts(first: 10, after: "cursorValue")
edges
node
id
name
description
cursor
pageInfo
hasNextPage
endCursor
In this example, `first` specifies the number of items, and `after` provides the cursor value to start from. The response includes `edges` (the data), `cursor` (for the next page), and `pageInfo` with metadata.
Pros: More efficient for large datasets as it avoids processing unnecessary records. Provides consistent performance regardless of the page number.
Cons: More complex to implement than offset-based pagination. Requires careful consideration of cursor design (e.g., using unique identifiers or timestamps).
Example:
query
getProducts(category: "Electronics", price_gt: 100)
id
name
description
price
Here, the query filters products by `category` and `price` using greater-than operator (`gt`).
Implementation Note: The backend resolver needs to interpret these filter parameters and query the underlying data source (e.g., DynamoDB) accordingly.
Example:
GraphQL Schema:
input ProductFilter
category: String
price_gt: Float
name_contains: String
GraphQL Query:
query
getProducts(filter: category: "Electronics", price_gt: 100, name_contains: "TV" )
id
name
description
price
This approach allows for a more structured and maintainable filtering mechanism.
Implementing Caching in AppSync
Caching significantly improves the performance and responsiveness of GraphQL APIs by storing frequently accessed data closer to the client. AWS AppSync provides built-in caching capabilities, allowing developers to configure caching at different levels.
- Caching Levels: AppSync offers several caching levels, providing flexibility in optimizing the API for different use cases.
- Per-Field Caching: This is the most granular level of caching. It allows caching individual fields within a GraphQL type. This is configured directly in the schema.
- Per-Type Caching: This caches all fields of a specific type. This is also configured in the schema.
- Caching Strategies: AppSync supports different caching strategies, allowing you to fine-tune the caching behavior.
- Default Caching: AppSync’s default caching strategy.
- Optimistic Caching: Caches the data even before the data source has responded. Useful for scenarios where data is likely to be the same.
- Cache Configuration: Configuring caching involves defining the cache settings within the AppSync console or through infrastructure-as-code (e.g., CloudFormation, Terraform). Key configuration parameters include:
- Time-to-Live (TTL): Specifies the duration (in seconds) for which data is cached.
- Caching Behavior: Determines how AppSync handles cache updates (e.g., automatic invalidation, on-demand updates).
- Cache Encryption: Enables encryption of the cache data for enhanced security.
- Cache Size: The size of the cache can be adjusted to accommodate the needs of your application.
- Cache Invalidation: Invalidation is crucial to ensure data consistency. AppSync provides mechanisms for invalidating cached data.
- Automatic Invalidation: AppSync can automatically invalidate the cache when data is updated through mutations. This is often the default behavior.
- Manual Invalidation: Developers can manually invalidate the cache using the `InvalidateCache` API. This allows for more control over cache updates.
- Monitoring and Optimization: Regularly monitor the cache performance using AppSync’s built-in metrics (e.g., cache hit rate, cache miss rate). Analyze the cache hit and miss rates to identify potential optimization opportunities. Adjust TTLs, caching strategies, and cache sizes based on performance analysis.
Example (GraphQL Schema):
type Product @cached(ttl: 3600)
id: ID!
name: String!
description: String
price: Float
In this example, the `@cached(ttl: 3600)` directive indicates that the `Product` type should be cached for 3600 seconds (1 hour). All fields within the `Product` type are cached.
Use Case: Suitable for frequently accessed data that doesn’t change often (e.g., product details, static content).
Example (GraphQL Schema):
type Query
getProduct(id: ID!): Product @cached(ttl: 600)
Here, the `getProduct` query is cached for 600 seconds (10 minutes). The cache applies to the entire response of the query.
Use Case: Useful for caching responses of frequently used queries that retrieve entire objects.
Example (Using the `InvalidateCache` API):
mutation
invalidateCache(
type: "Product",
ids: ["product123", "product456"]
)
This mutation invalidates the cache for the specified `Product` objects.
Use Case: Necessary when data updates occur outside of AppSync (e.g., through direct database modifications).
Using AppSync with Client-Side Libraries
Integrating AppSync with client-side libraries like Apollo Client and Relay simplifies the process of building GraphQL-based applications. These libraries provide features like data fetching, caching, and state management, streamlining the development process.
- Apollo Client: Apollo Client is a popular and versatile GraphQL client that provides a comprehensive set of features for building GraphQL applications.
- Installation: Install Apollo Client using a package manager (e.g., npm, yarn).
- Initialization: Configure Apollo Client to connect to the AppSync endpoint.
- Data Fetching: Use the `useQuery` hook (for queries) and `useMutation` hook (for mutations) to fetch and manipulate data.
- product.name
- Subscriptions: Apollo Client supports GraphQL subscriptions, allowing real-time updates.
- Caching: Apollo Client provides its own in-memory cache, which can be configured to improve performance. AppSync’s caching can be used in conjunction with Apollo Client’s cache.
- Relay: Relay is a GraphQL client developed by Facebook. It is known for its performance and advanced features.
- Installation and Setup: Relay requires a more complex setup than Apollo Client. It typically involves using the Relay compiler to generate code from the GraphQL schema.
- Data Fetching: Relay uses a declarative approach to data fetching, where components specify the data they need using GraphQL fragments.
- Caching and Data Consistency: Relay has a sophisticated caching mechanism and provides features for managing data consistency across the application.
- Relay Compiler: The Relay compiler optimizes GraphQL queries and generates efficient code for data fetching.
- Client Library Selection Considerations: The choice between Apollo Client and Relay depends on the project’s requirements.
- Apollo Client: Offers a more approachable learning curve and is suitable for a wide range of projects.
- Relay: Best suited for large, complex applications that require high performance and robust data management. It has a steeper learning curve.
- Other Client Libraries: Other options include URQL, and others, each with its own strengths and weaknesses.
- Best Practices for Client-Side Integration:
- Code Generation: Use code generation tools (e.g., Apollo Codegen, Relay Compiler) to generate type-safe code from the GraphQL schema. This reduces errors and improves developer productivity.
- Error Handling: Implement comprehensive error handling to gracefully manage errors from the GraphQL API.
- Performance Optimization: Optimize queries to fetch only the required data. Use pagination and filtering to manage large datasets.
- State Management: Use the client library’s state management features (e.g., Apollo Client’s cache, Relay’s store) to manage application state effectively.
npm install @apollo/client graphql
Example (JavaScript):
import ApolloClient, InMemoryCache, HttpLink from '@apollo/client';
const client = new ApolloClient(
link: new HttpLink(
uri: 'YOUR_APPSYNC_ENDPOINT',
headers:
'x-api-key': 'YOUR_API_KEY', // If using API key authentication
,
),
cache: new InMemoryCache(),
);
Replace `YOUR_APPSYNC_ENDPOINT` and `YOUR_API_KEY` with the appropriate values.
Example (React):
import useQuery from '@apollo/client';
import gql from '@apollo/client';
const GET_PRODUCTS = gql`
query GetProducts
getProducts
id
name
description
`;
function ProductList()
const loading, error, data = useQuery(GET_PRODUCTS);
if (loading) return
Loading...
;
if (error) return
Error: error.message
;
return (
- data.getProducts.map(product => (
))
);
Example (React):
import useSubscription from '@apollo/client';
import gql from '@apollo/client';
const PRODUCT_CREATED = gql`
subscription OnProductCreated
onProductCreated
id
name
`;
function ProductSubscription()
const loading, error, data = useSubscription(PRODUCT_CREATED);
if (loading) return
Loading...
; if (error) return
Error: error.message
; return (
New product: data.onProductCreated.name
);
Refer to the official Relay documentation for detailed installation and setup instructions.
Example (React):
import graphql, useFragment from 'react-relay';
const ProductFragment = graphql`
fragment Product_product on Product
id
name
description
`;
function Product(props)
const data = useFragment(ProductFragment, props.product);
return (
data.name

data.description
);
Epilogue
In conclusion, building a serverless GraphQL API with AppSync offers a compelling solution for developing modern, scalable, and efficient applications. By embracing the flexibility of GraphQL and the power of serverless technologies, developers can create APIs that are easier to manage, more cost-effective, and deliver superior performance. This guide provides a roadmap for navigating the complexities of this architecture, empowering developers to leverage the full potential of AppSync and GraphQL to build innovative and impactful solutions.
General Inquiries
What is the primary advantage of using a serverless approach for GraphQL APIs?
The primary advantage is the elimination of server management, leading to automatic scaling, reduced operational costs, and increased developer productivity. This allows developers to focus on code rather than infrastructure maintenance.
How does AppSync handle authentication and authorization?
AppSync supports various authentication methods, including API keys, IAM roles, and Cognito user pools. Authorization is managed through directives in the GraphQL schema, enabling fine-grained access control based on user roles and permissions.
Can I integrate existing databases other than DynamoDB with AppSync?
Yes, AppSync supports integration with various data sources, including relational databases like RDS, and other AWS services via Lambda functions, providing flexibility in data storage choices.
What are the best practices for optimizing API performance in AppSync?
Key optimization strategies include implementing caching, optimizing resolvers for efficiency, using pagination for large datasets, and leveraging CloudWatch for monitoring and performance analysis.