The transition to serverless computing has reshaped software development, creating new opportunities and challenges for developers. Understanding the nuances of serverless architecture, from its fundamental concepts to its practical implementation, is now crucial. This guide provides a structured approach to navigating the interview process for serverless developer roles, equipping you with the knowledge and skills needed to excel.
This comprehensive Artikel covers essential topics, including serverless fundamentals, core technologies, architectural patterns, coding best practices, testing and debugging strategies, security considerations, and interview preparation. We will delve into technical and behavioral aspects, including system design, to provide a complete preparation strategy. The goal is to transform you into a confident and well-prepared candidate, ready to demonstrate your expertise and secure your desired role in the serverless landscape.
Understanding Serverless Fundamentals
Serverless computing represents a paradigm shift in cloud computing, abstracting away the underlying infrastructure management and allowing developers to focus solely on writing and deploying code. This approach promises increased agility, scalability, and cost efficiency. A thorough understanding of serverless fundamentals is crucial for anyone preparing for a serverless developer interview.
Core Concepts of Serverless Computing
Serverless computing, despite its name, still involves servers. However, the management of these servers is entirely handled by the cloud provider. Developers deploy code, and the provider dynamically allocates resources, scales the application, and handles all infrastructure-related tasks, such as provisioning, maintenance, and capacity planning.
- Function as a Service (FaaS): This is the core building block of serverless architectures. FaaS platforms allow developers to execute individual functions (code snippets) in response to events, such as HTTP requests, database updates, or scheduled triggers. Examples include AWS Lambda, Azure Functions, and Google Cloud Functions. The function is triggered by events and runs for a specific duration, typically measured in milliseconds.
- Event-Driven Architecture: Serverless applications are inherently event-driven. They react to events occurring within the cloud environment. Events can originate from various sources, including API calls, database changes, message queues, and scheduled tasks. This architecture promotes loose coupling and scalability.
- Statelessness: Functions are generally stateless. Each function invocation operates independently and does not retain state between invocations. This characteristic is critical for scalability and resilience. Any required state management is typically handled by external services, such as databases or caches.
- Automatic Scaling: Serverless platforms automatically scale the application based on demand. The cloud provider handles the allocation and deallocation of resources, ensuring that the application can handle fluctuating workloads without manual intervention.
- Pay-per-Use Pricing: Serverless computing typically follows a pay-per-use pricing model. Developers are charged only for the actual compute time consumed by their functions. This can significantly reduce costs compared to traditional infrastructure, particularly for applications with variable workloads.
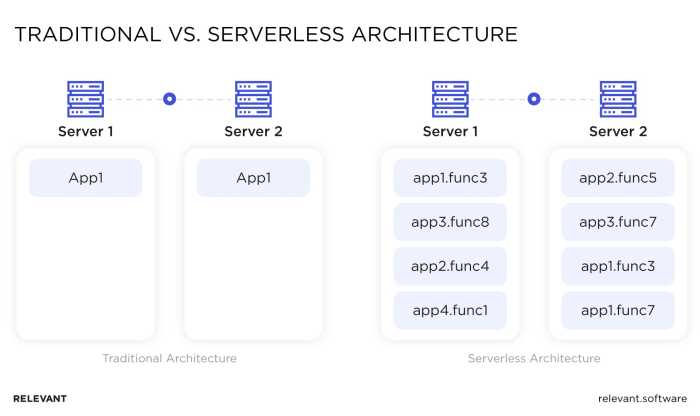
Comparison Between Serverless and Traditional Infrastructure
The following table compares serverless and traditional infrastructure across several key dimensions.
| Feature | Serverless | Traditional Infrastructure | Key Differences |
|---|---|---|---|
| Infrastructure Management | Managed by cloud provider | Managed by the developer or operations team | Serverless eliminates the need for infrastructure provisioning, maintenance, and scaling. |
| Compute Model | Function-as-a-Service (FaaS) | Virtual machines, containers, or physical servers | Serverless applications are built around individual functions, while traditional applications are typically deployed as monolithic applications or microservices. |
| Scaling | Automatic and dynamic | Manual or automated (e.g., using auto-scaling groups) | Serverless platforms automatically scale based on demand, while traditional infrastructure requires manual configuration or more complex auto-scaling setups. |
| Pricing | Pay-per-use (based on execution time, memory usage, and number of invocations) | Pay-per-hour or fixed cost (based on instance size and uptime) | Serverless offers potentially lower costs for applications with intermittent workloads, while traditional infrastructure can be more cost-effective for consistently high workloads. |
| Deployment | Simplified; deploy individual functions | More complex; requires managing servers and application dependencies | Serverless simplifies deployment by focusing on deploying individual functions, while traditional deployments involve more steps and configuration. |
Advantages and Disadvantages of Serverless Architectures
Serverless architectures offer a compelling set of advantages but also introduce certain challenges. A balanced understanding of these trade-offs is essential for making informed decisions.
- Advantages:
- Reduced Operational Costs: The pay-per-use pricing model can significantly reduce costs, especially for applications with variable workloads or low traffic. For instance, a marketing campaign website that experiences peak traffic during specific periods would benefit from serverless’s automatic scaling and cost-effectiveness.
- Increased Developer Productivity: Developers can focus on writing code rather than managing infrastructure. This leads to faster development cycles and quicker time-to-market.
- Scalability and Availability: Serverless platforms automatically handle scaling, ensuring that applications can handle fluctuating workloads without manual intervention. This automatic scaling can handle unexpected traffic spikes.
- Improved Agility: Serverless architectures enable faster iteration and deployment of new features. This allows businesses to adapt quickly to changing market demands.
- Simplified Operations: The cloud provider handles all infrastructure-related tasks, reducing the operational burden on the development team. This reduces the need for specialized DevOps personnel.
- Disadvantages:
- Vendor Lock-in: Serverless applications are often tightly coupled with a specific cloud provider’s platform. Migrating to another provider can be challenging.
- Cold Starts: Functions may experience a “cold start” when invoked for the first time or after a period of inactivity. This can introduce latency. However, optimizations like “provisioned concurrency” can mitigate this.
- Monitoring and Debugging: Debugging serverless applications can be more complex than debugging traditional applications due to the distributed nature of the architecture. Monitoring tools and practices are essential.
- Limited Control: Developers have less control over the underlying infrastructure, which can be a limitation for certain types of applications. This is especially true in areas such as OS-level configurations or specific network settings.
- Statelessness Constraints: The stateless nature of functions requires developers to manage state externally, which can add complexity. Managing session data in a serverless environment requires careful consideration.
Core Serverless Technologies
A comprehensive understanding of core serverless technologies is crucial for any serverless developer interview. This section delves into the key services offered by major cloud providers, the pivotal role of Functions-as-a-Service (FaaS) platforms, and the significance of API gateways in architecting and deploying serverless applications. Mastery of these concepts demonstrates a solid foundation in serverless principles and best practices.
Key Services Offered by Major Cloud Providers for Serverless Development
Cloud providers offer a suite of serverless services that facilitate the development, deployment, and management of applications without the need to manage servers. These services vary slightly between providers but share common functionalities. Understanding these differences is essential for choosing the right platform for a given project.
- AWS (Amazon Web Services): AWS provides a comprehensive suite of serverless services.
- AWS Lambda: This is AWS’s FaaS offering, allowing developers to run code without provisioning or managing servers. Lambda supports various programming languages, including Node.js, Python, Java, Go, and C#.
- Amazon API Gateway: API Gateway is a fully managed service that enables developers to create, publish, maintain, monitor, and secure APIs at scale. It supports RESTful APIs, WebSocket APIs, and HTTP APIs.
- Amazon S3 (Simple Storage Service): S3 is an object storage service used for storing and retrieving any amount of data from anywhere on the web. It’s often used to store static website content, application artifacts, and data used by serverless functions.
- Amazon DynamoDB: DynamoDB is a fully managed NoSQL database service that provides fast and predictable performance with seamless scalability. It’s well-suited for serverless applications due to its ability to handle fluctuating workloads.
- Amazon EventBridge: EventBridge is a serverless event bus service that enables you to connect applications with data from various sources. It can be used to trigger Lambda functions based on events from other AWS services or custom applications.
- Azure (Microsoft Azure): Azure’s serverless offerings provide similar capabilities to AWS.
- Azure Functions: Azure Functions is Azure’s FaaS platform, offering a serverless compute service that allows developers to run event-triggered code without managing infrastructure. It supports various languages, including C#, JavaScript, Python, and Java.
- Azure API Management: This is a service for publishing, managing, and monitoring APIs. It provides features such as API gateway functionality, security, and analytics.
- Azure Blob Storage: Similar to AWS S3, Azure Blob Storage is an object storage service for storing unstructured data.
- Azure Cosmos DB: Cosmos DB is a globally distributed, multi-model database service that supports various APIs, including SQL, MongoDB, Cassandra, and Gremlin. It’s designed for high availability and scalability, making it suitable for serverless applications.
- Azure Event Grid: Event Grid is a fully managed event routing service that enables you to build event-driven applications. It allows you to subscribe to events from various Azure services and custom sources.
- GCP (Google Cloud Platform): GCP offers a strong set of serverless tools and services.
- Cloud Functions: Cloud Functions is GCP’s FaaS offering, allowing developers to execute code in response to events without managing servers. It supports Node.js, Python, Go, Java, .NET, and Ruby.
- Cloud API Gateway: Cloud API Gateway is a fully managed service that enables you to create, secure, and manage APIs. It supports various API protocols, including REST and gRPC.
- Cloud Storage: Cloud Storage is GCP’s object storage service, similar to AWS S3 and Azure Blob Storage.
- Cloud Firestore/Cloud Datastore: Firestore is a NoSQL document database, while Datastore is a NoSQL database service. Both are suitable for serverless applications.
- Cloud Pub/Sub: Pub/Sub is a real-time messaging service that allows you to send and receive messages between independent applications. It’s often used for event-driven architectures.
Role of Functions-as-a-Service (FaaS) Platforms
FaaS platforms are the core of serverless computing. They allow developers to execute code in response to events without the need to provision or manage servers. This event-driven nature significantly reduces operational overhead and allows developers to focus on writing code.
- Event-Driven Execution: FaaS functions are typically triggered by events, such as HTTP requests, database updates, file uploads, or scheduled timers. This event-driven model is a key characteristic of serverless architectures. For example, a Lambda function in AWS could be triggered by an object being uploaded to an S3 bucket.
- Scalability and Elasticity: FaaS platforms automatically scale the execution of functions based on demand. This elasticity ensures that applications can handle varying workloads without manual intervention. If a large number of users access a website, the associated serverless functions will automatically scale to handle the increased load.
- Pay-per-Use Pricing: FaaS providers typically charge based on the number of function invocations, the execution time, and the resources consumed. This pay-per-use pricing model can significantly reduce costs compared to traditional server-based architectures, especially for applications with intermittent workloads.
- Statelessness: FaaS functions are inherently stateless, meaning they do not maintain any persistent state between invocations. This statelessness allows for easy scaling and deployment across multiple instances. If state is needed, it is typically managed through external services like databases or object storage.
- Supported Languages and Runtimes: FaaS platforms support a variety of programming languages and runtimes, providing flexibility for developers. For instance, AWS Lambda supports Node.js, Python, Java, Go, and C#, allowing developers to choose the language they are most comfortable with.
Importance of API Gateways in Serverless Applications
API gateways play a critical role in serverless applications by providing a single entry point for all API requests. They handle tasks such as authentication, authorization, rate limiting, and request routing, allowing developers to focus on the business logic of their applications.
- Centralized Management: API gateways provide a central point for managing and monitoring all API traffic. This simplifies the process of applying security policies, monitoring performance, and making changes to API configurations.
- Security: API gateways enforce security policies, such as authentication and authorization, to protect APIs from unauthorized access. They can integrate with identity providers to authenticate users and implement authorization rules to control access to specific API endpoints.
- Request Routing and Transformation: API gateways route incoming requests to the appropriate backend services, such as FaaS functions. They can also transform requests and responses to match the requirements of the backend services. This abstraction simplifies the architecture and allows for changes to the backend services without impacting the client applications.
- Rate Limiting and Throttling: API gateways can implement rate limiting and throttling to protect backend services from being overwhelmed by excessive traffic. This helps to ensure the availability and performance of the APIs.
- Monitoring and Analytics: API gateways provide monitoring and analytics capabilities, allowing developers to track API usage, identify performance bottlenecks, and troubleshoot issues. This data is crucial for optimizing API performance and ensuring a positive user experience.
Serverless Architecture Patterns
Serverless architecture patterns are reusable blueprints for designing and implementing serverless applications. Understanding these patterns is crucial for effectively leveraging the benefits of serverless computing, such as scalability, cost efficiency, and reduced operational overhead. These patterns guide developers in structuring applications to handle various use cases, from simple web applications to complex, data-intensive processing pipelines. They provide a framework for organizing serverless components, defining interactions, and optimizing performance.
Design Common Serverless Architecture Patterns
Serverless architecture patterns provide a structured approach to building applications without managing servers. Several common patterns are frequently employed.
- Event-Driven Architecture: This pattern centers around events, which trigger functions. Components communicate asynchronously through events, promoting loose coupling and scalability. Events can originate from various sources, such as database changes, file uploads, or scheduled tasks. A common example is processing image uploads: when a new image is uploaded to a storage service (e.g., AWS S3), an event is triggered, and a serverless function automatically resizes the image and stores it in another location.
- Web Application Architecture: This pattern focuses on building web applications. It typically involves a front-end hosted on a content delivery network (CDN), an API gateway for handling requests, and serverless functions for backend logic. Data storage is often handled by a database service. This architecture enables rapid deployment and scaling of web applications. A classic example is a blog platform: users interact with the front-end, the API gateway routes requests to serverless functions that handle tasks like retrieving and storing blog posts, and a database stores the content.
- Data Processing Architecture: This pattern is designed for processing large volumes of data. It uses serverless functions to transform, analyze, and load data. Data sources can include streaming data from IoT devices, log files, or databases. This pattern supports real-time data processing and batch jobs. Consider a scenario involving sensor data: data streams from IoT devices are ingested, serverless functions perform real-time analysis, and the results are stored for later use or visualized on a dashboard.
- Microservices Architecture: This pattern involves breaking down an application into small, independent services, each responsible for a specific business function. Serverless functions can be used to implement these microservices, allowing for independent scaling and deployment. This pattern enhances agility and maintainability. An e-commerce platform could be implemented using microservices: one service handles user authentication, another manages product catalogs, and a third handles order processing.
Create an Example of a Serverless Web Application Architecture
A serverless web application architecture utilizes several components to deliver a scalable and cost-effective user experience. The following components and their interactions form a robust system.
- Content Delivery Network (CDN): The CDN serves static assets such as HTML, CSS, JavaScript, and images to users. A CDN caches these assets at edge locations around the world, reducing latency and improving website performance. For example, using Amazon CloudFront, the CDN distributes content geographically to minimize the distance between users and the data, improving load times.
- API Gateway: The API gateway acts as the entry point for all API requests. It handles routing, authentication, authorization, and rate limiting. The API gateway routes incoming requests to the appropriate serverless functions. For instance, Amazon API Gateway can authenticate user requests and route them to the backend functions.
- Serverless Functions: Serverless functions execute the backend logic of the application. They are triggered by events, such as HTTP requests from the API gateway. These functions handle tasks like processing user data, interacting with databases, and generating responses. For example, AWS Lambda functions can be used to handle API requests, perform data processing, and interact with other AWS services.
- Database: The database stores the application’s data. A serverless database, such as Amazon DynamoDB, provides scalability and automatic scaling. It handles the storage and retrieval of information, such as user profiles, product details, and order information.
- Authentication and Authorization: Authentication and authorization mechanisms ensure the security of the application. User authentication can be handled by a service like Amazon Cognito, which provides user sign-up, sign-in, and access control. The API gateway and serverless functions can then use this information to authorize user access to resources.
Demonstrate How to Implement a Serverless Microservices Architecture
Implementing a serverless microservices architecture involves breaking down an application into smaller, independent services that communicate through APIs. This architecture allows for independent scaling, deployment, and updates of each service.
- Service Decomposition: The first step is to identify the different business functions within the application and decompose them into independent microservices. Each service should focus on a specific task or set of related tasks. For example, an e-commerce platform might be divided into services such as user authentication, product catalog management, order processing, and payment processing.
- API Design: Each microservice exposes an API that defines how other services can interact with it. APIs should be well-defined, versioned, and documented. The API gateway acts as the single entry point for all API requests, routing requests to the appropriate microservice.
- Function Implementation: Serverless functions are used to implement the business logic within each microservice. Each function is responsible for a specific task, such as retrieving product details, processing an order, or authenticating a user.
- Data Storage: Each microservice should ideally manage its own data. This promotes loose coupling and allows each service to choose the database technology that best suits its needs. Serverless databases, such as Amazon DynamoDB, are well-suited for this architecture.
- Communication and Eventing: Microservices communicate with each other through APIs or by publishing and subscribing to events. Event-driven architectures are well-suited for microservices, as they enable asynchronous communication and loose coupling. Services can publish events to a message queue or event bus, and other services can subscribe to those events to react to changes.
- Deployment and Management: Each microservice should be deployed and managed independently. This allows for continuous delivery and updates without affecting other services. Serverless platforms provide tools for deploying, monitoring, and scaling serverless functions.
Coding and Development Practices
The ability to write efficient and performant code is crucial for serverless developers. This section delves into the best practices for writing serverless functions, providing code examples and optimization techniques to ensure optimal performance and cost-effectiveness. Mastering these practices is essential for building scalable and reliable serverless applications.
Best Practices for Writing Serverless Functions
Serverless functions, by their nature, have unique characteristics that necessitate specific coding practices. These practices are essential to mitigate common challenges like cold starts and manage state effectively, leading to improved performance and cost savings.
- Minimize Cold Starts: Cold starts are a significant performance bottleneck in serverless environments. When a function is invoked after a period of inactivity, the cloud provider needs to provision a new container instance, leading to a delay. Strategies to mitigate cold starts include:
- Provisioned Concurrency: Some providers offer provisioned concurrency, which pre-warms function instances, ensuring they are ready to handle requests immediately.
For example, AWS Lambda provides provisioned concurrency to maintain a specific number of function instances ready to serve traffic.
- Keep Functions Warm: Implementing a “heartbeat” mechanism to periodically invoke the function can keep it warm. This can be achieved through scheduled events or monitoring services.
- Optimize Code Size: Smaller code packages load faster. Reduce dependencies and code size to minimize loading times.
- Provisioned Concurrency: Some providers offer provisioned concurrency, which pre-warms function instances, ensuring they are ready to handle requests immediately.
- Effective State Management: Serverless functions are stateless by design. Managing state requires careful consideration.
- External Data Stores: Utilize external databases or storage services (e.g., Amazon DynamoDB, AWS S3, Azure Cosmos DB) to persist state.
- Avoid Local Storage: Local storage within a function’s container is ephemeral and unreliable. Do not rely on it for persistent data.
- Session Management: Implement session management using cookies or tokens stored in external data stores.
- Error Handling and Logging: Robust error handling and logging are vital for debugging and monitoring serverless applications.
- Centralized Logging: Implement centralized logging to aggregate logs from all function invocations. Use services like AWS CloudWatch Logs, Azure Monitor, or Google Cloud Logging.
- Detailed Error Messages: Provide detailed error messages to facilitate troubleshooting. Include timestamps, function names, and relevant context.
- Implement Retries: Implement retry mechanisms for transient errors, such as network issues or temporary database unavailability.
- Dependency Management: Efficient dependency management is crucial for code maintainability and performance.
- Package Dependencies: Package all dependencies within your deployment package. This ensures that the function has access to all required libraries.
- Use a Package Manager: Utilize package managers like npm (Node.js) or pip (Python) to manage dependencies and their versions.
- Minimize Dependencies: Reduce the number of dependencies to minimize the size of the deployment package and reduce cold start times.
Coding Examples in Common Serverless Languages
The following examples demonstrate how to write simple serverless functions in Python and Node.js, illustrating basic concepts such as input/output handling and interaction with external services.
- Python Example (AWS Lambda): This example demonstrates a simple Python function that processes an event and returns a response. It uses the `boto3` library to interact with AWS services.
import jsonimport boto3def lambda_handler(event, context): try: # Extract data from the event name = event['name'] message = f"Hello, name!" # Interact with AWS services (example: write to S3) s3 = boto3.client('s3') bucket_name = 'your-bucket-name' object_key = 'greeting.txt' s3.put_object(Bucket=bucket_name, Key=object_key, Body=message.encode('utf-8')) # Return a response response = 'statusCode': 200, 'body': json.dumps( 'message': message ) return response except Exception as e: # Handle errors print(f"Error: e") return 'statusCode': 500, 'body': json.dumps( 'message': 'Internal Server Error' )The Python code takes a ‘name’ from an event, constructs a greeting message, and writes it to an S3 bucket using the boto3 library. Error handling is included to manage potential exceptions.
The `lambda_handler` function serves as the entry point for the Lambda function.
- Node.js Example (AWS Lambda): This example shows a Node.js function that uses the `axios` library to make an HTTP request.
const axios = require('axios');exports.handler = async (event) => try const response = await axios.get('https://api.example.com/data'); const data = response.data; const responseBody = message: 'Data retrieved successfully', data: data ; const response = statusCode: 200, body: JSON.stringify(responseBody) ; return response; catch (error) console.error('Error:', error); const response = statusCode: 500, body: JSON.stringify( message: 'Internal Server Error' ) ; return response; ;The Node.js code retrieves data from a sample API endpoint using the `axios` library. The function logs any errors to the console and constructs a JSON response. The `handler` function serves as the entry point.
Tips for Optimizing Serverless Function Performance
Optimizing serverless function performance is crucial for cost efficiency and responsiveness. Several techniques can be applied to improve performance.
- Optimize Function Code:
- Reduce Code Complexity: Simplify the code to minimize execution time. Use efficient algorithms and data structures.
- Lazy Loading: Load dependencies only when they are needed. This can reduce the initial load time.
- Code Profiling: Use profiling tools to identify performance bottlenecks and optimize critical sections of code.
- Memory and Timeout Configuration:
- Allocate Sufficient Memory: Allocate enough memory to your function to avoid performance degradation. Increase memory can increase CPU power.
- Set Appropriate Timeout: Set a timeout that is sufficient for the function to complete its tasks, but not excessively long to avoid unnecessary costs.
- Caching:
- Implement Caching Strategies: Implement caching at different levels (e.g., in-memory caching, caching using a service like Redis) to reduce the load on external resources and improve response times.
- Cache Data from External Services: Cache frequently accessed data from external services to reduce latency and improve performance.
- Concurrency Management:
- Control Concurrency: Monitor the concurrency of your functions to avoid throttling and ensure optimal performance.
- Adjust Concurrency Limits: Adjust the concurrency limits of your functions based on your application’s traffic and performance requirements.
- Monitoring and Alerting:
- Monitor Performance Metrics: Continuously monitor key performance indicators (KPIs) such as execution time, memory usage, and error rates.
- Set Up Alerts: Configure alerts to notify you of any performance issues or anomalies.
Testing and Debugging Serverless Applications
Effective testing and debugging are crucial for the success of serverless applications. Due to the distributed nature of serverless architectures, identifying and resolving issues requires a different approach compared to traditional monolithic applications. Thorough testing ensures code reliability, while robust debugging techniques are essential for pinpointing and resolving problems that inevitably arise in production. This section will explore strategies for testing, debugging, monitoring, and logging serverless functions.
Strategies for Testing Serverless Functions
Testing serverless functions demands a multi-faceted approach to ensure code correctness and application stability. This includes unit tests, integration tests, and potentially end-to-end tests, each playing a specific role in the validation process.
- Unit Tests: Unit tests are the foundation of testing, focusing on individual functions or small, isolated components. They verify that each function behaves as expected given specific inputs and outputs.
- Implementation: Unit tests for serverless functions are typically written using testing frameworks specific to the chosen programming language (e.g., Jest for JavaScript, JUnit for Java, pytest for Python). These frameworks provide tools for writing test cases, mocking dependencies, and asserting expected results.
- Benefits: Unit tests provide rapid feedback on code changes, enabling developers to identify and fix bugs early in the development cycle. They also serve as documentation, illustrating how functions are intended to be used.
- Example (Python with pytest):
“`python
# function_to_test.py
def add(x, y):
return x + y# test_function_to_test.py
import pytest
from function_to_test import adddef test_add():
assert add(2, 3) == 5
assert add(-1, 1) == 0
“`In this example, the `test_add` function uses `pytest` to assert the expected behavior of the `add` function.
- Integration Tests: Integration tests verify the interactions between different components of the serverless application, including functions, APIs, databases, and other services.
- Implementation: Integration tests typically involve deploying the functions to a test environment and simulating real-world scenarios. This often requires setting up mock services or using test databases to isolate the application from production data.
- Benefits: Integration tests validate that the various parts of the application work together correctly. They help to identify issues related to service interactions, data flow, and API integration.
- Example: Testing an API Gateway integration with a Lambda function. This would involve sending requests to the API Gateway and verifying that the Lambda function is invoked correctly, processes the request, and returns the expected response. The testing framework might simulate different HTTP methods (GET, POST, etc.) and request payloads.
Debugging Techniques for Serverless Applications
Debugging serverless applications requires a different approach than debugging traditional applications. Because serverless functions execute in ephemeral environments, traditional debugging techniques like stepping through code with a debugger are often impractical. Instead, developers rely on a combination of logging, tracing, and specialized tools.
- Logging: Logging is the cornerstone of debugging serverless applications. Detailed logs provide insights into function execution, including input parameters, output values, and any errors that occur.
- Implementation: Logging is typically implemented using logging libraries provided by the programming language runtime or by the serverless platform itself (e.g., AWS CloudWatch Logs, Azure Monitor, Google Cloud Logging). Logs should include timestamps, log levels (e.g., DEBUG, INFO, WARNING, ERROR), and contextual information to aid in troubleshooting.
- Best Practices:
- Log at different levels to capture varying degrees of detail.
- Include unique request IDs to correlate logs across different functions and services.
- Avoid logging sensitive information.
- Use structured logging formats (e.g., JSON) for easier parsing and analysis.
- Tracing: Tracing provides a way to follow the flow of a request through a distributed system. It allows developers to visualize the interactions between different services and identify performance bottlenecks.
- Implementation: Serverless platforms often provide tracing services (e.g., AWS X-Ray, Azure Application Insights, Google Cloud Trace). These services automatically instrument function executions and collect tracing data.
- Benefits: Tracing helps to identify slow function invocations, errors that occur within specific services, and the overall performance of the application.
- Example: A request that goes through an API Gateway, triggers a Lambda function, accesses a DynamoDB table, and then returns a response. Tracing allows you to visualize the time spent in each of these components.
- Local Debugging: While debugging in production is often challenging, local debugging can be useful for replicating and resolving issues.
- Implementation: Many serverless platforms offer local development environments or tools that allow developers to run and debug functions locally. This allows developers to use traditional debuggers to step through code, inspect variables, and identify issues.
- Benefits: Local debugging allows for a more rapid feedback loop during development and can help to resolve issues before they are deployed to production.
Monitoring and Logging Serverless Function Executions
Monitoring and logging are essential for understanding the performance and health of serverless applications. Comprehensive monitoring provides insights into function execution times, error rates, and resource utilization. Effective logging provides detailed information about function behavior and can be used to diagnose and resolve issues.
- Monitoring Metrics: Serverless platforms automatically collect and expose various metrics related to function executions.
- Common Metrics:
- Invocations: The number of times a function has been executed.
- Errors: The number of errors that have occurred during function execution.
- Duration: The time it takes for a function to execute.
- Throttles: The number of times a function execution was throttled due to resource limitations.
- Concurrent Executions: The number of concurrent instances of a function running.
- Implementation: Monitoring dashboards are typically provided by the serverless platform (e.g., AWS CloudWatch, Azure Monitor, Google Cloud Monitoring). These dashboards allow developers to visualize metrics, set up alerts, and track the performance of their applications over time.
- Common Metrics:
- Log Analysis: Analyzing logs is a critical step in troubleshooting serverless applications.
- Implementation: Serverless platforms often provide tools for searching, filtering, and analyzing logs (e.g., AWS CloudWatch Logs Insights, Azure Log Analytics, Google Cloud Logging). These tools allow developers to search for specific events, identify patterns, and diagnose the root causes of issues.
- Techniques:
- Log Aggregation: Consolidating logs from different functions and services into a centralized location.
- Log Filtering: Using filters to focus on specific log events, such as errors or warnings.
- Log Analysis Tools: Employing tools like the ELK stack (Elasticsearch, Logstash, Kibana) or Splunk to analyze and visualize logs.
- Alerting: Setting up alerts is crucial for proactively identifying and responding to issues.
- Implementation: Serverless platforms allow developers to define alerts based on various metrics (e.g., error rates, function duration, resource utilization). When a metric exceeds a predefined threshold, an alert is triggered, which can notify developers via email, SMS, or other channels.
- Benefits: Alerts allow developers to respond to issues quickly and prevent them from impacting users. They can also be used to identify performance bottlenecks and other issues that need to be addressed.
- Example: An alert can be set up to notify the development team if the error rate for a specific Lambda function exceeds 1% over a 5-minute period. This allows the team to investigate and resolve the issue before it significantly impacts users.
Serverless Security Best Practices
Securing serverless applications is paramount due to the distributed nature of these systems and the inherent attack surface introduced by third-party services and function execution environments. Understanding and implementing robust security measures is crucial to protect data, maintain availability, and ensure the integrity of serverless applications. The dynamic nature of serverless necessitates a proactive and layered security approach, continuously monitored and updated to address evolving threats.
Common Security Vulnerabilities in Serverless Applications
Serverless applications are susceptible to various security vulnerabilities, many of which stem from the architecture’s unique characteristics. These vulnerabilities can lead to data breaches, denial-of-service attacks, and unauthorized access.
- Injection Flaws: These vulnerabilities occur when untrusted data is sent to an interpreter as part of a command or query. Serverless functions, especially those interacting with databases or external APIs, are vulnerable to SQL injection, command injection, and NoSQL injection attacks if input validation is inadequate. For example, a function that constructs a database query based on user input without proper sanitization could be exploited to retrieve or modify sensitive data.
- Broken Authentication and Authorization: Weak authentication and authorization mechanisms can allow attackers to gain unauthorized access to serverless functions and data. This includes issues such as weak password policies, lack of multi-factor authentication, and improper role-based access control. Consider a scenario where a function handles sensitive user data; if authorization is not correctly implemented, an attacker could potentially access another user’s information.
- Sensitive Data Exposure: Sensitive data, such as API keys, database credentials, and user data, may be inadvertently exposed in serverless functions, environment variables, or logs. Improperly secured storage or logging configurations can lead to the leakage of this sensitive information, which can be exploited by attackers to gain access to critical resources.
- XML External Entities (XXE): If a serverless function processes XML data, it can be vulnerable to XXE attacks. Attackers can exploit XML parsers to access local files, interact with internal network resources, or execute remote code. For instance, a function that processes XML configuration files without proper XXE protection could be used to retrieve sensitive system information.
- Insecure Deserialization: When a serverless function deserializes untrusted data, such as JSON or XML, it can be vulnerable to insecure deserialization attacks. Attackers can craft malicious serialized objects that, when deserialized, execute arbitrary code on the server. This could lead to remote code execution and compromise the entire serverless environment.
- Security Misconfiguration: Misconfigured security settings, such as overly permissive IAM roles, open ports, or default credentials, can create significant security risks. For example, a serverless function with excessive permissions could be exploited to access and manipulate sensitive resources.
- Serverless Function Abuse: Attackers may attempt to exploit serverless functions for malicious purposes, such as cryptomining, denial-of-service attacks, or botnet control. This could involve deploying malicious code to a serverless function or using existing functions to perform unauthorized operations.
- Supply Chain Attacks: Serverless applications often rely on third-party dependencies. If a dependency is compromised, it can introduce vulnerabilities into the serverless application. Attackers can inject malicious code into a dependency, which is then executed when the serverless function runs.
Securing Serverless Functions and APIs
Securing serverless functions and APIs involves implementing a multi-layered approach that encompasses various security best practices. This includes securing code, infrastructure, and data.
- Secure Code Development: Implement secure coding practices throughout the development lifecycle. This includes input validation and sanitization to prevent injection attacks, output encoding to prevent cross-site scripting (XSS) attacks, and secure handling of sensitive data. Using static and dynamic analysis tools to identify and fix code vulnerabilities is also crucial.
- Least Privilege Principle: Grant serverless functions only the necessary permissions to access resources. Avoid using overly permissive IAM roles, and regularly review and update permissions based on the function’s requirements. This minimizes the impact of a potential security breach.
- Environment Variable Management: Securely store and manage sensitive information, such as API keys and database credentials, using environment variables. Utilize secure secrets management services provided by cloud providers, such as AWS Secrets Manager, to encrypt and manage secrets. Avoid hardcoding sensitive information directly into the code.
- API Gateway Security: Implement security measures at the API gateway level. This includes authentication, authorization, request validation, and rate limiting. Utilize features like API keys, OAuth, and JWT tokens to secure API endpoints. Configure the API gateway to filter malicious requests and prevent denial-of-service attacks.
- Input Validation and Sanitization: Thoroughly validate and sanitize all user inputs to prevent injection attacks. This includes validating the data type, format, and range of inputs. Sanitize inputs by removing or encoding potentially malicious characters. Consider using a Web Application Firewall (WAF) to protect against common web attacks.
- Regular Security Audits and Penetration Testing: Conduct regular security audits and penetration testing to identify vulnerabilities and assess the effectiveness of security measures. This should include both automated and manual testing. Address identified vulnerabilities promptly and update security measures accordingly.
- Monitoring and Logging: Implement comprehensive monitoring and logging to detect and respond to security incidents. Log all relevant events, such as authentication attempts, API requests, and errors. Use security information and event management (SIEM) tools to analyze logs and identify potential threats. Set up alerts to notify administrators of suspicious activity.
- Use of Security Tools: Employ security tools provided by cloud providers or third-party vendors. This includes tools for vulnerability scanning, code analysis, and runtime protection. Utilize these tools to automate security tasks and improve the overall security posture of the serverless application.
- Function Isolation: Use function isolation techniques to limit the impact of a security breach. This includes running functions in separate containers or sandboxes. This prevents attackers from gaining access to other functions or resources.
Implementing Authentication and Authorization in Serverless Environments
Implementing robust authentication and authorization mechanisms is critical for securing serverless applications. This ensures that only authorized users and services can access resources and perform actions.
- Authentication Methods: Choose appropriate authentication methods based on the application’s requirements. Common methods include:
- API Keys: Simple for basic API access control.
- JSON Web Tokens (JWT): Widely used for stateless authentication, often used in conjunction with OAuth 2.0.
- OAuth 2.0: Enables delegated access to resources without sharing user credentials.
- Identity Providers (IdPs): Utilize services like Amazon Cognito, Auth0, or Okta to manage user identities and authentication.
- Authorization Strategies: Implement authorization strategies to control access to resources and actions. Common strategies include:
- Role-Based Access Control (RBAC): Assign users to roles with specific permissions.
- Attribute-Based Access Control (ABAC): Define access control based on attributes of users, resources, and the environment.
- API Gateway Integration: Leverage the API gateway’s built-in authentication and authorization features. Configure the API gateway to authenticate users and authorize requests based on predefined policies. Integrate with IdPs to handle user authentication.
- Function-Level Authorization: Implement authorization logic within serverless functions to enforce fine-grained access control. Verify user permissions before executing sensitive operations. Use JWTs to pass user information and authorization claims to functions.
- Token Management: Securely manage authentication tokens. Use short-lived tokens and refresh tokens to minimize the impact of token compromise. Store tokens securely, and implement token revocation mechanisms.
- Example using AWS Cognito and API Gateway:
- Setup: Configure an Amazon Cognito user pool and an API gateway.
- Authentication: Users authenticate through the Cognito user pool, receiving an ID token.
- Authorization: Configure the API gateway to use Cognito authorizer to validate the ID token. The API gateway uses the claims in the token to authorize access to specific API endpoints.
- Function Execution: The API gateway passes the user’s identity to the backend serverless function, allowing it to perform additional authorization checks.
- Regular Audits and Monitoring: Regularly audit authentication and authorization configurations. Monitor authentication events and access logs for suspicious activity. Set up alerts to notify administrators of unauthorized access attempts or policy violations.
Serverless Interview Preparation – Technical Questions

Preparing for a serverless developer interview necessitates a deep understanding of serverless principles and practical application. This section focuses on the technical aspects of serverless, providing example questions, detailed answers, and scenario-based challenges to help candidates demonstrate their expertise. The goal is to equip candidates with the knowledge and analytical skills to excel in serverless-related interviews.
Example Technical Interview Questions on Serverless Concepts
Understanding core serverless concepts is fundamental. Interviewers often assess this knowledge through a series of technical questions designed to gauge the candidate’s comprehension.
- Serverless Architecture Definition: Serverless architecture is a cloud computing execution model where the cloud provider dynamically manages the allocation of machine resources. This includes server provisioning and management, eliminating the need for developers to manage servers directly.
- Function-as-a-Service (FaaS) Explanation: FaaS is a key component of serverless computing, allowing developers to execute code without managing the underlying infrastructure. Code is executed in response to events, such as HTTP requests or database updates.
- Event-Driven Architecture in Serverless: Serverless applications frequently utilize event-driven architectures. Events trigger function executions, creating a decoupled system where different services communicate asynchronously.
- Benefits of Serverless: The advantages of serverless include reduced operational overhead, automatic scaling, cost optimization through pay-per-use pricing, and faster development cycles.
- Serverless Limitations: Limitations of serverless include vendor lock-in, cold starts, and debugging complexities.
FaaS Platforms: Questions and Answers
FaaS platforms form the backbone of serverless computing. The following questions and answers are typical of those asked to assess a candidate’s understanding of these platforms.
- AWS Lambda: AWS Lambda is a serverless compute service that lets you run code without provisioning or managing servers. It supports multiple programming languages and integrates seamlessly with other AWS services.
- Question: Describe the process of deploying a function to AWS Lambda.
- Answer: The deployment process involves packaging the code (along with any dependencies) into a ZIP file or container image, uploading it to Lambda, and configuring the function’s trigger and resource settings.
- Azure Functions: Azure Functions is a serverless compute service on the Microsoft Azure platform. It allows developers to run code triggered by various events, such as HTTP requests, timers, or messages in Azure storage queues.
- Question: Explain the role of triggers and bindings in Azure Functions.
- Answer: Triggers initiate the execution of a function in response to events, while bindings provide a declarative way to connect functions to other Azure services, such as storage accounts or databases.
- Google Cloud Functions: Google Cloud Functions is a serverless execution environment that enables developers to build and connect event-driven applications. It allows developers to execute code in response to events generated by Google Cloud services.
- Question: What are the advantages of using Google Cloud Functions?
- Answer: Advantages include automatic scaling, pay-per-use pricing, integration with Google Cloud services, and support for multiple programming languages.
- FaaS Platform Comparison: Comparing the capabilities of different FaaS platforms is crucial for choosing the right platform for a project.
- Question: Compare and contrast AWS Lambda, Azure Functions, and Google Cloud Functions.
- Answer: AWS Lambda offers broad integration with AWS services, Azure Functions provides robust integration with Azure services, and Google Cloud Functions integrates seamlessly with Google Cloud services. All platforms offer automatic scaling and pay-per-use pricing, but they differ in supported languages, trigger types, and tooling.
Scenario-Based Question: Troubleshooting a Serverless Application
Scenario-based questions assess a candidate’s ability to apply their knowledge to solve real-world problems. This scenario focuses on troubleshooting.
- Scenario: A serverless application built with AWS Lambda and API Gateway is experiencing high latency and occasional 500 errors. The application processes image uploads and performs image resizing.
- Question: How would you approach troubleshooting this issue?
- Answer:
- Review Logs: Examine CloudWatch logs for Lambda functions and API Gateway to identify errors, performance bottlenecks, and potential causes of the latency. Check for error messages, timeouts, or high execution times.
- Monitor Metrics: Analyze Lambda function metrics (e.g., invocation count, duration, errors, throttles) and API Gateway metrics (e.g., latency, 5XX errors) to pinpoint problem areas.
- Identify the Bottleneck: Determine which part of the application is causing the delays. This could be the image resizing function, database interactions, or network latency.
- Optimize Code: Review the Lambda function code for inefficiencies, such as slow database queries or inefficient image processing algorithms. Optimize the code for performance.
- Increase Resources: If the function is consistently timing out, increase the function’s memory allocation and execution timeout.
- Implement Caching: If applicable, implement caching to reduce the load on backend services and improve response times.
- Implement Retries: Implement retries for failed operations to handle transient errors.
- Consider Cold Starts: Evaluate the impact of cold starts and explore strategies to mitigate them, such as using provisioned concurrency.
- Test Thoroughly: After implementing changes, thoroughly test the application to ensure the issue is resolved and no new problems have been introduced.
Serverless Interview Preparation – Behavioral Questions

Behavioral interview questions are designed to assess how a candidate has handled situations in the past, providing insights into their skills, work ethic, and problem-solving abilities. For serverless roles, these questions focus on areas like teamwork, project experience, and adapting to the rapid pace of serverless development. The STAR method (Situation, Task, Action, Result) is a widely recognized framework for answering these questions effectively, ensuring a structured and comprehensive response.
Examples of Behavioral Interview Questions Relevant to Serverless Roles
The following examples showcase the types of behavioral questions a candidate might encounter in a serverless role interview.
- Describe a time you had to explain a complex technical concept to a non-technical stakeholder.
- Tell me about a project where you had to work closely with a team to achieve a common goal.
- Describe a time you had to debug a challenging serverless application. What was your approach?
- Give an example of a time you had to learn a new serverless technology quickly. How did you approach the learning process?
- Describe a situation where you identified a potential performance bottleneck in a serverless application. What steps did you take to address it?
- Tell me about a time you had to deal with a production outage in a serverless environment. How did you handle the situation?
- Describe a time you had to make a difficult technical decision on a serverless project. What factors did you consider?
- Give an example of a time you received negative feedback on a serverless project. How did you respond?
Answering Questions about Teamwork and Problem-Solving in a Serverless Context
Effective responses to teamwork and problem-solving questions should demonstrate the candidate’s ability to collaborate, analyze, and resolve issues in a serverless environment. Using the STAR method ensures a structured and compelling answer.
- Teamwork: When describing a teamwork scenario, emphasize the collaborative aspects. Detail the specific roles each team member played and how you contributed to the team’s success. Focus on how you communicated with your teammates, especially in a distributed serverless environment.
- Problem-Solving: For problem-solving questions, clearly Artikel the issue, the steps taken to diagnose the problem, and the ultimate solution. Highlight the tools and techniques used for debugging, such as logging, monitoring, and tracing within the serverless architecture. Show how you analyzed the situation and made informed decisions.
Demonstrating Your Serverless Project Experience
Providing specific examples of serverless projects allows candidates to showcase their practical skills and knowledge. Using the STAR method to structure each project description ensures clarity and impact.
Project Example: Serverless Image Processing Pipeline
Situation: A company needed to automate the resizing and optimization of user-uploaded images for its e-commerce platform. This process was previously handled manually, leading to delays and inconsistencies in image quality. The existing infrastructure was not designed for the scalability required by the project.
Task: Design and implement a serverless image processing pipeline to automatically resize and optimize images uploaded by users. The pipeline needed to handle high traffic, ensure low latency, and minimize operational overhead.
Action:
- Used AWS Lambda functions triggered by Amazon S3 object creation events to initiate the processing workflow.
- Utilized the AWS SDK for Node.js within the Lambda functions to interact with S3, resize images using the Sharp library, and optimize them using techniques like progressive JPEG encoding.
- Implemented an Amazon API Gateway to expose an endpoint for users to upload images to S3.
- Configured CloudWatch for logging and monitoring the performance of the Lambda functions and API Gateway.
- Integrated automated testing using Jest and serverless-offline to validate the functions’ behavior.
Result: The serverless image processing pipeline successfully automated image resizing and optimization. The platform achieved significant improvements in image loading times, reduced storage costs, and freed up manual processes. The solution handled a 5x increase in image uploads during peak periods without performance degradation, demonstrating the scalability of the serverless architecture. The implementation also led to a 20% reduction in storage costs by optimizing image sizes.
Project Example: Real-time Chat Application
Situation: A startup required a real-time chat application for its internal team to facilitate communication and collaboration. Traditional approaches required significant infrastructure management and operational overhead.
Task: Develop a scalable and cost-effective real-time chat application using serverless technologies. The application needed to support concurrent users, provide low-latency message delivery, and ensure data persistence.
Action:
- Implemented a serverless architecture using AWS AppSync as a GraphQL API.
- Utilized AWS Lambda functions to handle business logic, such as user authentication and message processing.
- Leveraged Amazon DynamoDB for data storage, providing scalable and fast access to chat messages and user information.
- Implemented WebSocket connections using AppSync for real-time message delivery.
- Configured user authentication using Amazon Cognito to secure access to the chat application.
- Integrated a CI/CD pipeline using AWS CodePipeline to automate deployments and updates.
Result: The real-time chat application was successfully deployed and scaled to support the entire team. The application delivered messages with minimal latency, providing a seamless user experience. The project reduced infrastructure costs by 60% compared to traditional server-based solutions, and the team reported a 30% increase in communication efficiency. The CI/CD pipeline allowed for frequent and reliable updates.
Serverless Interview Preparation – System Design
Designing serverless systems is a core competency for serverless developers. Interviewers frequently assess a candidate’s ability to architect scalable, resilient, and cost-effective solutions using serverless principles. This section focuses on system design aspects, equipping you with the knowledge and skills to confidently tackle system design questions in serverless interviews.
Design a serverless system for a specific use case (e.g., image processing)
The use case of image processing provides a compelling example for demonstrating serverless system design principles. A common scenario involves users uploading images, which then undergo various transformations (resizing, format conversion, watermarking), before being stored and served.Here’s a design for a serverless image processing system:* User Upload: Users upload images via an HTTPS endpoint, which is handled by an API Gateway.
Triggering Image Processing
The API Gateway triggers an AWS Lambda function. This function acts as an orchestrator, receiving the image upload event details.
Image Storage and Processing
The orchestrator function stores the original image in an Amazon S3 bucket. It then invokes a series of other Lambda functions, each responsible for a specific image transformation task (e.g., resizing, format conversion, watermarking). These functions are triggered by the orchestrator using asynchronous invocations, allowing for parallel processing.
Queueing Mechanism (Optional)
An Amazon SQS queue can be introduced between the orchestrator and the transformation functions. This adds decoupling and resilience, allowing the system to handle bursts of upload traffic without overwhelming the transformation functions.
Data Storage and Management
Processed images are stored in a separate Amazon S3 bucket. Metadata about each image (original size, processed sizes, format) is stored in a database, such as Amazon DynamoDB.
Content Delivery
Processed images are served via Amazon CloudFront, a content delivery network (CDN), for fast and efficient global distribution.
Monitoring and Logging
The entire system is monitored using Amazon CloudWatch, which collects logs, metrics, and provides alarms for any issues.
Elaborate on the factors to consider when designing a serverless system
Several critical factors influence the design of a serverless system, impacting its performance, cost, and maintainability. Understanding these factors is crucial for making informed design decisions.
- Scalability and Performance: Serverless systems inherently scale automatically. However, consider the following:
- Concurrency Limits: AWS Lambda has default concurrency limits. These limits should be sufficient for most workloads, but it’s important to be aware of them and plan for potential throttling if needed.
- Cold Starts: Cold starts (the initial latency when a Lambda function is invoked) can affect performance. Consider strategies like provisioned concurrency to mitigate cold starts for critical functions.
- Database Performance: The choice of database and its configuration (e.g., provisioned throughput for DynamoDB) significantly impacts performance. Optimize database queries and access patterns to avoid bottlenecks.
- Cost Optimization: Serverless architectures offer pay-per-use pricing, making cost optimization a key design consideration.
- Function Duration: Optimize function code to minimize execution time, reducing costs.
- Resource Allocation: Configure memory and CPU for Lambda functions appropriately, avoiding over-provisioning.
- Storage Costs: Choose the appropriate storage classes for S3 buckets (e.g., Standard, Intelligent-Tiering, Glacier) based on access frequency and storage needs.
- Security: Security is paramount in any system.
- IAM Roles and Permissions: Grant functions only the necessary permissions using least privilege principles.
- Data Encryption: Encrypt data at rest (e.g., S3 buckets, DynamoDB tables) and in transit (HTTPS).
- VPC Configuration: For increased security, deploy Lambda functions within a Virtual Private Cloud (VPC).
- Resilience and Availability: Design for failures.
- Idempotency: Ensure that functions are idempotent (can be executed multiple times without unintended side effects).
- Error Handling and Retries: Implement robust error handling and retry mechanisms for function invocations.
- Decoupling: Utilize queues (e.g., SQS) to decouple components and improve resilience against failures.
- Monitoring and Observability: Implement comprehensive monitoring and logging.
- Metrics and Alarms: Use CloudWatch metrics and alarms to monitor system health and performance.
- Logging: Implement detailed logging for troubleshooting and auditing.
- Tracing: Use AWS X-Ray for distributed tracing to understand the flow of requests through the system.
- Maintainability and Development Practices: Consider long-term maintainability.
- Code Organization: Structure code logically, using modular design principles.
- Testing: Implement thorough unit and integration tests.
- Infrastructure as Code (IaC): Use IaC tools (e.g., AWS CloudFormation, Terraform) to manage infrastructure in a repeatable and automated manner.
Illustrate the system design with a detailed diagram of the components and their interactions
The system design is represented through a diagram, described as follows:The diagram depicts a flow starting from a user and progressing through various AWS services.* The User: Represented by a rectangle, initiating the process.
API Gateway
A cloud icon with an API Gateway label. An arrow originates from the User rectangle and points to the API Gateway, signifying the upload initiation.
Lambda Orchestrator Function
A cloud icon with a Lambda logo, labeled as “Orchestrator Function.” An arrow extends from the API Gateway to the Lambda function.
Amazon S3 (Original Images Bucket)
A cylindrical icon with the S3 logo, labeled “S3 (Original Images).” An arrow from the Lambda function leads to this bucket, denoting the storage of the original images.
SQS Queue (Optional)
A cloud icon with an SQS logo. The Lambda function can publish messages to this queue.
Lambda Transformation Functions (Multiple)
Several cloud icons with Lambda logos, labeled as “Resize Function,” “Convert Function,” and “Watermark Function,” each representing a specific transformation task. Arrows originate from the SQS queue (if used) or directly from the Orchestrator Function, pointing to each transformation function.
Amazon S3 (Processed Images Bucket)
A cylindrical icon with the S3 logo, labeled “S3 (Processed Images).” Arrows extend from each transformation function to this bucket, indicating the storage of processed images.
DynamoDB
A database icon, labeled “DynamoDB.” An arrow from the Lambda functions points to DynamoDB, showing the storage of metadata.
Amazon CloudFront
A cloud icon with the CloudFront logo, labeled “CloudFront.” Arrows originate from the “S3 (Processed Images)” bucket to the CloudFront, showing the content delivery.
Amazon CloudWatch
A cloud icon with the CloudWatch logo. Lines extend from all components (API Gateway, Lambda functions, S3 buckets, DynamoDB, CloudFront) to the CloudWatch icon, illustrating the monitoring of the system.The diagram’s arrows indicate the direction of data flow and function invocations, while the labels provide context to each component’s function. The entire system is enclosed, implying it operates within the AWS cloud infrastructure.
The visual representation emphasizes the event-driven nature of the serverless architecture.
Last Word
In conclusion, mastering the serverless developer interview demands a multifaceted approach. By thoroughly understanding serverless principles, core technologies, and best practices, coupled with effective preparation for technical and behavioral questions, you can significantly enhance your chances of success. This guide has provided a framework for achieving this, equipping you with the tools and knowledge to confidently navigate the interview process and showcase your expertise in this rapidly evolving field.
Embrace the challenges, and you will be well-positioned to thrive in the world of serverless computing.
Detailed FAQs
What is the difference between serverless and Platform as a Service (PaaS)?
While both abstract away infrastructure management, PaaS typically requires developers to manage the application’s runtime environment, whereas serverless completely handles the execution environment, scaling, and provisioning, allowing developers to focus solely on code.
How do I handle state management in a serverless application?
Serverless applications often utilize external services for state management, such as databases (e.g., DynamoDB, MongoDB Atlas), object storage (e.g., S3), or caching services (e.g., Redis). Careful consideration is needed for state persistence and consistency across function invocations.
What are some common pitfalls to avoid when building serverless applications?
Common pitfalls include inefficient function design leading to cold starts, over-reliance on monolithic functions, neglecting security best practices, and poor monitoring and logging practices. Addressing these proactively is essential for robust serverless applications.
How can I optimize the cost of a serverless application?
Cost optimization strategies involve careful resource allocation, optimizing function execution time, using cost-effective storage solutions, and leveraging features like reserved instances or savings plans where applicable. Monitoring usage and identifying areas for improvement is also crucial.