The modern landscape of software development is rapidly evolving, with serverless computing emerging as a transformative paradigm. This approach allows developers to build and deploy applications without managing the underlying infrastructure, offering unprecedented scalability and efficiency. Setting up a serverless development environment involves a shift in perspective, moving away from traditional server management towards a function-centric architecture. This guide will delve into the core concepts, tools, and processes required to successfully establish a robust and efficient serverless development environment.
We will explore the intricacies of selecting cloud providers, configuring accounts, installing necessary tools, and deploying functions. From the initial setup to advanced topics like API gateway integration, authentication, monitoring, and CI/CD pipelines, we’ll provide a comprehensive overview. The goal is to equip you with the knowledge and practical skills needed to embrace the power and flexibility of serverless architectures, ultimately leading to faster development cycles, reduced operational costs, and increased innovation.
Introduction to Serverless Development Environment

Serverless computing represents a paradigm shift in software development, moving away from the traditional model of managing and maintaining servers. Instead, developers focus on writing and deploying code, while the cloud provider handles the underlying infrastructure. This approach allows for increased agility, scalability, and cost efficiency, making it a compelling choice for modern application development.
Core Concept of Serverless Computing
Serverless computing fundamentally changes how applications are built and deployed. The core concept centers on the execution of code without the need to provision or manage servers. This implies that the cloud provider dynamically allocates resources, scaling them up or down based on the workload demands. Developers upload their code, and the cloud provider handles everything else: server provisioning, scaling, and management.
Definition of a Serverless Development Environment
A serverless development environment encompasses the tools, services, and practices that enable developers to build, test, and deploy serverless applications. It provides a streamlined workflow, reducing the operational overhead associated with traditional infrastructure management. This environment includes various components, each contributing to the overall efficiency and effectiveness of the serverless development process.
- Integrated Development Environments (IDEs): Modern IDEs offer plugins and extensions that facilitate the development of serverless functions. They provide features like code completion, debugging tools, and integration with cloud provider services, improving developer productivity.
- Command-Line Interface (CLI) Tools: CLIs are essential for managing serverless applications. They allow developers to deploy functions, manage resources, and monitor application performance from the command line, streamlining the development workflow.
- Local Emulation and Testing Frameworks: These tools enable developers to test serverless functions locally before deploying them to the cloud. They simulate the cloud environment, allowing for faster iteration and reduced development costs.
- Monitoring and Logging Services: Serverless environments rely heavily on monitoring and logging to track application performance and identify issues. Cloud providers offer comprehensive services for monitoring function invocations, errors, and latency.
- API Gateways: API gateways act as the entry point for serverless applications, routing requests to the appropriate functions. They handle authentication, authorization, and rate limiting, ensuring the security and scalability of the application.
Benefits of Serverless Environments over Traditional Setups
Serverless environments offer several advantages over traditional infrastructure-based setups. These benefits translate into increased developer productivity, reduced operational costs, and improved scalability.
- Reduced Operational Overhead: With serverless, developers do not have to manage servers, reducing the time and effort spent on infrastructure management. This allows them to focus on writing code and building features.
- Automatic Scaling: Serverless platforms automatically scale resources based on demand. This eliminates the need for manual scaling, ensuring that applications can handle varying workloads without performance degradation. This dynamic scaling is often reflected in the billing model, where you only pay for the resources actually consumed. For example, consider a website that experiences a sudden surge in traffic due to a marketing campaign.
In a traditional setup, the website might experience performance issues or require manual intervention to scale the infrastructure. In a serverless environment, the platform automatically scales the resources to handle the increased traffic, ensuring a smooth user experience without any manual intervention.
- Cost Efficiency: Serverless computing often follows a pay-per-use model, where developers only pay for the resources consumed. This can result in significant cost savings compared to traditional setups, especially for applications with intermittent workloads.
- Increased Developer Productivity: Serverless environments streamline the development workflow, allowing developers to deploy code faster and iterate more quickly. This leads to increased productivity and faster time-to-market.
- Improved Scalability and Reliability: Serverless platforms are designed for high availability and scalability. They automatically distribute resources across multiple availability zones, ensuring that applications can handle failures and scale to meet demand. Consider an e-commerce platform that experiences a large influx of orders during a holiday sale. A serverless architecture can automatically scale the application to handle the increased traffic, ensuring that all orders are processed efficiently.
Choosing a Cloud Provider
Selecting the appropriate cloud provider is a critical step in establishing a serverless development environment. The choice significantly impacts development workflows, cost optimization, scalability, and the overall operational efficiency of serverless applications. This decision necessitates a thorough evaluation of available platforms, their feature sets, pricing models, and the specific requirements of the project.
Popular Cloud Providers and Their Serverless Services
Several cloud providers have established themselves as leaders in the serverless computing space. Each provider offers a suite of services designed to facilitate the development, deployment, and management of serverless applications. The following discusses three prominent players: Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP).
- Amazon Web Services (AWS): AWS offers a comprehensive set of serverless services, including:
- AWS Lambda: A compute service that lets you run code without provisioning or managing servers. It supports various programming languages and triggers, such as HTTP requests, database updates, and scheduled events.
- Amazon API Gateway: A fully managed service that makes it easy for developers to create, publish, maintain, monitor, and secure APIs at any scale.
- Amazon DynamoDB: A fully managed NoSQL database service that provides fast and predictable performance with seamless scalability.
- Amazon S3: An object storage service offering industry-leading scalability, data availability, security, and performance.
- Microsoft Azure: Azure provides a robust serverless platform with the following key services:
- Azure Functions: An event-driven, compute-on-demand experience that lets you build and run applications without managing infrastructure. It supports various programming languages and triggers.
- Azure API Management: A hybrid, multi-cloud management platform for APIs across all environments.
- Azure Cosmos DB: A globally distributed, multi-model database service that provides guaranteed low latency and high availability.
- Azure Blob Storage: A massively scalable object storage for unstructured data.
- Google Cloud Platform (GCP): GCP’s serverless offerings are designed for scalability and ease of use, including:
- Cloud Functions: An event-driven, serverless compute platform that allows you to run your code without provisioning or managing servers.
- Cloud Run: A fully managed compute platform that enables you to run containerized applications. It supports various programming languages and frameworks.
- Cloud API Gateway: A fully managed service that makes it easy to create, publish, maintain, monitor, and secure APIs at any scale.
- Cloud Firestore: A NoSQL document database built for automatic scaling, high performance, and ease of application development.
- Cloud Storage: Object storage for storing any amount of data.
Comparison of Pricing Models for Serverless Functions
Pricing models for serverless functions vary across cloud providers, and understanding these differences is crucial for cost optimization. Generally, providers charge based on factors such as the number of invocations, the duration of execution (measured in milliseconds), and the memory allocated to the function.
- AWS Lambda: AWS Lambda utilizes a pay-per-use model. You are charged for the number of requests and the duration of your function’s execution. Pricing is based on the allocated memory and the compute time consumed. AWS also offers a free tier that provides a certain amount of compute time and requests per month.
- Azure Functions: Azure Functions also employs a pay-per-use model, similar to AWS Lambda. You are charged based on the number of executions and the resource consumption, including memory and CPU usage. Azure offers a consumption plan, which is ideal for event-driven workloads with fluctuating traffic.
- Google Cloud Functions and Cloud Run: Google Cloud Functions and Cloud Run use a pay-per-use pricing structure. With Cloud Functions, you are charged for the number of invocations, execution time, and memory consumption. Cloud Run charges based on the vCPU and memory usage, and the number of requests processed. GCP also offers a free tier for both services.
The core concept in serverless pricing is that you only pay for the resources your code uses. This differs significantly from traditional cloud computing, where you pay for provisioned resources regardless of actual utilization.
Key Features Comparison of Serverless Platforms
The following table presents a comparative analysis of the key features of each cloud provider’s serverless platform.
| Feature | AWS Lambda | Azure Functions | Google Cloud Functions/Cloud Run |
|---|---|---|---|
| Compute Service | AWS Lambda | Azure Functions | Cloud Functions/Cloud Run |
| Programming Languages Supported | Node.js, Python, Java, Go, C#, PowerShell, Ruby, C++, and more. | Node.js, Python, Java, C#, PowerShell, and more. | Node.js, Python, Go, Java, .NET, and more. Cloud Run supports containerized applications. |
| Trigger Support | API Gateway, S3, DynamoDB, Kinesis, CloudWatch Events, and more. | HTTP triggers, Azure Blob Storage, Azure Cosmos DB, Event Hubs, and more. | HTTP, Cloud Storage, Cloud Pub/Sub, Cloud Firestore, Cloud Scheduler, and more. |
| Container Support | Limited support through Lambda Layers and Container Images. | Yes, with Azure Functions Premium plan. | Cloud Run is built for containerized applications. Cloud Functions supports limited containerization. |
| Deployment Method | Code upload, container images (via ECR). | Code upload, container images (via ACR). | Code upload, container images (via Artifact Registry or other container registries). |
| Monitoring and Logging | CloudWatch | Azure Monitor, Application Insights | Cloud Logging, Cloud Monitoring |
| Integration with other services | Deep integration with AWS services (e.g., S3, DynamoDB, API Gateway). | Seamless integration with Azure services (e.g., Blob Storage, Cosmos DB, API Management). | Strong integration with GCP services (e.g., Cloud Storage, Cloud Firestore, Cloud API Gateway). |
| Pricing Model | Pay-per-use (requests and duration). | Pay-per-use (executions and resource consumption). | Pay-per-use (invocations, execution time, and memory). Cloud Run based on resource consumption. |
Setting Up an Account and Access
Establishing a secure and functional account with a cloud provider is a foundational step in any serverless development workflow. This involves not only account creation but also the configuration of access mechanisms that allow developers to interact with cloud resources programmatically. Proper setup is paramount for security, cost management, and efficient development.
Creating an Account with a Cloud Provider
The account creation process typically involves providing basic information and agreeing to terms of service. It’s crucial to provide accurate details as this information may be needed for billing and verification purposes.
- Account Registration: The first step is visiting the cloud provider’s website and initiating the account creation process. This usually involves selecting a plan, which may include a free tier with limited resources for experimentation.
- Information Submission: Provide personal or organizational information, including name, email address, and contact details. For organizational accounts, it’s essential to designate an administrator.
- Verification: Cloud providers employ verification methods to ensure the legitimacy of the account. This often involves email verification, phone number verification, or both. Some providers may require credit card information to prevent abuse, even for free tier accounts.
- Payment Method: If the selected plan requires payment, the user must provide payment details, such as a credit card or bank account information. Carefully review the pricing structure and potential charges.
- Account Confirmation: Once the account is verified and the payment information is processed (if applicable), the account is typically activated. Users can then access the cloud provider’s console and start using its services.
Configuring Access Keys or Service Accounts for Programmatic Access
Programmatic access enables developers to interact with cloud services using code, which is crucial for automating deployments, managing resources, and integrating serverless applications. This is generally accomplished through the use of access keys or service accounts.
- Understanding Access Keys: Access keys consist of an access key ID and a secret access key. These credentials act as the user’s identity and are used to authenticate API requests. It is crucial to store these keys securely and never commit them to version control.
- Creating Access Keys: Access keys are typically generated within the cloud provider’s console under the user’s account or an IAM (Identity and Access Management) user. When creating keys, the user should be provided with a warning to store the secret key securely, as it will only be shown once.
- Using Service Accounts: Service accounts are identities associated with specific resources or applications, rather than individual users. They’re often used in serverless environments to grant specific permissions to functions or services.
- Setting up Service Accounts: Service accounts are usually created within the cloud provider’s IAM service. The process involves defining the scope of the service account (e.g., which resources it can access) and associating it with specific serverless functions or applications.
- Implementing Access Key Security:
- Least Privilege Principle: Grant only the necessary permissions to access keys or service accounts. Avoid granting broad permissions that could compromise security.
- Key Rotation: Regularly rotate access keys to minimize the impact of a compromised key. Most cloud providers offer features to facilitate key rotation.
- Secure Storage: Store access keys securely using secret management services, environment variables, or secure configuration files. Never hardcode access keys in code.
Setting Up Proper Security and Permissions
Security and permissions are critical components of a cloud environment. Proper configuration minimizes the risk of unauthorized access, data breaches, and other security vulnerabilities.
- IAM Policies: IAM (Identity and Access Management) policies define the permissions granted to users, groups, and roles. These policies are written in JSON format and specify which actions are allowed or denied on specific resources.
- Role-Based Access Control (RBAC): RBAC involves assigning roles to users or service accounts, where each role represents a set of permissions. This simplifies permission management and ensures consistency across the organization.
- Principle of Least Privilege: Grant users and service accounts only the minimum permissions necessary to perform their tasks. This reduces the attack surface and limits the potential damage from a security breach.
- Multi-Factor Authentication (MFA): Enable MFA for all user accounts to add an extra layer of security. MFA requires users to provide a second form of authentication, such as a code from a mobile app, in addition to their password.
- Regular Auditing: Regularly audit access logs and permissions to identify and address any security vulnerabilities. Cloud providers offer tools for monitoring and auditing activity within the cloud environment.
- Resource-Specific Permissions: Configure permissions at the resource level. For example, instead of granting a user full access to all S3 buckets, grant access only to specific buckets or objects within those buckets.
- Example: Consider a serverless application that processes image uploads. Instead of granting the Lambda function full access to all S3 buckets, define an IAM policy that allows the function to only read and write to a specific bucket designated for image storage. This limits the scope of potential damage if the function is compromised.
Installing Necessary Tools and SDKs
To effectively develop serverless applications, several tools and software development kits (SDKs) are essential. These components streamline the development process, enabling developers to interact with cloud services, write code, and manage deployments efficiently. The following sections detail the installation of command-line interfaces (CLIs), SDKs, and the integration of these tools within integrated development environments (IDEs).
Installing the Cloud Provider CLI
The command-line interface (CLI) provides a text-based interface for interacting with the cloud provider’s services. This allows developers to manage resources, deploy applications, and monitor performance from the command line. The CLI is a fundamental tool for automating tasks and integrating serverless development into existing workflows.
- AWS CLI Installation: The AWS CLI can be installed using `pip` (Python’s package installer), the `msi` installer (for Windows), or through package managers on Linux and macOS.
For example, using `pip`:
pip install awscli --upgrade --userAfter installation, configure the CLI with your AWS credentials:
aws configureThis will prompt for your AWS Access Key ID, Secret Access Key, default region, and default output format.
- Google Cloud SDK (gcloud) Installation: The Google Cloud SDK provides the `gcloud` CLI. Installation options include using a package manager (e.g., `apt` for Debian/Ubuntu, `yum` for CentOS/RHEL), a dedicated installer, or directly downloading the SDK.
Example installation using `apt`:
sudo apt-get update && sudo apt-get install google-cloud-sdkInitialize the SDK and authenticate with your Google Cloud account:
gcloud initFollow the prompts to log in and select your project.
- Azure CLI Installation: The Azure CLI (`az`) can be installed using package managers, installers, or directly from the Azure website.
Example installation using `apt`:
sudo apt-get update && sudo apt install azure-cliAuthenticate with your Azure account:
az loginThis will open a browser window for authentication.
Installing Required SDKs
SDKs are essential for interacting with the cloud provider’s services programmatically. They provide libraries and tools that abstract away the complexities of the underlying APIs, enabling developers to write code in their preferred programming languages.
- Python SDKs:
Python is a popular language for serverless development.
Install the AWS SDK for Python (Boto3):
pip install boto3Install the Google Cloud Client Libraries:
pip install google-cloud-functionsInstall the Azure SDK for Python:
pip install azure-functions - Node.js SDKs:
Node.js is another common choice for serverless.
Install the AWS SDK for JavaScript (AWS SDK for JavaScript v3):
npm install @aws-sdk/client-lambdaInstall the Google Cloud Client Libraries:
npm install @google-cloud/functions-frameworkInstall the Azure SDK for JavaScript:
npm install @azure/functions - Java SDKs:
Java is a widely used language, especially in enterprise environments.
Install the AWS SDK for Java:
Add the AWS SDK dependencies to your `pom.xml` (Maven) or `build.gradle` (Gradle) file. For example, using Maven:
<dependency> <groupId>com.amazonaws</groupId> <artifactId>aws-lambda-java-core</artifactId> <version>1.2.2</version> </dependency> <dependency> <groupId>com.amazonaws</groupId> <artifactId>aws-lambda-java-events</artifactId> <version>3.11.0</version> </dependency>
Install the Google Cloud Client Libraries:
Add the Google Cloud Functions dependency to your `pom.xml` or `build.gradle` file.
Install the Azure SDK for Java:
Add the Azure Functions dependencies to your `pom.xml` or `build.gradle` file.
IDE Integrations and Plugins
IDE integrations and plugins significantly enhance the serverless development experience. These tools provide features such as code completion, debugging, deployment, and monitoring directly within the IDE, streamlining the development workflow. They reduce the time spent on repetitive tasks and increase developer productivity.
- AWS Toolkit for VS Code: This extension provides a range of features, including:
- Code completion and snippets for AWS services.
- Direct deployment of serverless applications to AWS Lambda.
- Debugging Lambda functions locally and remotely.
- Browsing and managing AWS resources.
- Google Cloud Code for VS Code/IntelliJ: This extension offers:
- Support for creating, deploying, and debugging Cloud Functions.
- Integration with Google Cloud services.
- Code completion and syntax highlighting.
- Azure Tools for VS Code: This extension provides:
- Tools for creating, deploying, and managing Azure Functions.
- Integration with Azure services.
- Debugging capabilities.
Creating and Deploying Serverless Functions
The core of a serverless development environment revolves around the creation and deployment of functions. These functions, the fundamental units of serverless applications, are designed to execute specific tasks in response to triggers, such as HTTP requests or events from other services. This section details the process of crafting, deploying, and configuring serverless functions to illustrate the operational mechanics within a serverless framework.
Writing a “Hello, World!” Serverless Function
A “Hello, World!” function serves as a foundational example for understanding the basic syntax and structure of serverless functions. It demonstrates the minimal code required to perform a simple operation. The specific implementation varies depending on the chosen programming language and cloud provider’s runtime environment, but the underlying principles remain consistent.
For this demonstration, let’s consider a “Hello, World!” function written in Python, targeting the AWS Lambda environment. The function will receive an HTTP request and return a JSON response containing the greeting.
“`python
import json
def lambda_handler(event, context):
“””
Lambda function that returns a “Hello, World!” message.
“””
body =
“message”: “Hello, World!”,
response =
“statusCode”: 200,
“body”: json.dumps(body)
return response
“`
This Python code defines a function named `lambda_handler`. This name is a convention for AWS Lambda functions. When an HTTP request triggers this function, the `event` parameter will contain information about the request (e.g., headers, query parameters, and body). The `context` parameter provides information about the invocation, function, and execution environment. The function constructs a JSON response with a “Hello, World!” message and a 200 status code, then returns this response.
This simple example encapsulates the essential components of a serverless function: input processing, task execution, and output generation. The function’s design emphasizes statelessness, as it does not retain any state between invocations. Each invocation executes independently, making it scalable and resilient.
Deploying a Function Using the CLI
Deploying a serverless function typically involves using a command-line interface (CLI) provided by the cloud provider or a third-party framework. The CLI automates the process of packaging the function code, uploading it to the cloud, and configuring the necessary infrastructure (e.g., execution role, triggers). This process reduces the manual effort required for deployment.
The deployment steps, while varying slightly between providers and frameworks, generally include the following actions:
- Packaging the Code: The function code and any dependencies are packaged into a deployment artifact (e.g., a ZIP file). This artifact is then uploaded to the cloud provider’s storage service.
- Creating the Function: Using the CLI, a new function is created within the serverless platform. This step involves specifying the function’s name, runtime (e.g., Python 3.9), and the deployment artifact’s location.
- Configuring Execution Role: An execution role is created or assigned to the function. This role defines the permissions the function has to access other AWS resources (e.g., S3 buckets, DynamoDB tables).
- Setting Up Triggers: Triggers are configured to activate the function. Common triggers include HTTP endpoints (API Gateway), event queues (SQS), and scheduled events (CloudWatch Events).
Let’s illustrate the deployment process using the AWS CLI, assuming the “Hello, World!” function is saved in a file named `hello_world.py`. The example will deploy the function and create an API Gateway endpoint to trigger it.
1. Package the function:
“`bash
zip function.zip hello_world.py
“`
This command creates a ZIP archive named `function.zip` containing the `hello_world.py` file.
2. Create the function using the AWS CLI:
“`bash
aws lambda create-function \
–function-name hello-world-function \
–runtime python3.9 \
–role arn:aws:iam::YOUR_ACCOUNT_ID:role/lambda-execution-role \
–handler hello_world.lambda_handler \
–zip-file fileb://function.zip
“`
This command creates a Lambda function named `hello-world-function`.
It specifies the Python 3.9 runtime, the IAM role with execution permissions, the handler function (`hello_world.lambda_handler`), and the deployment package. Replace `YOUR_ACCOUNT_ID` with your actual AWS account ID and ensure the specified IAM role exists and has the necessary permissions.
3. Create an API Gateway endpoint:
“`bash
aws apigateway create-rest-api –name hello-world-api
“`
This creates a new API Gateway instance.
“`bash
aws apigateway get-rest-apis
“`
Retrieve the API ID of the created API.
“`bash
aws apigateway create-resource –rest-api-id YOUR_API_ID –parent-id YOUR_ROOT_ID –path-part hello
“`
Create a resource path in the API Gateway.
“`bash
aws apigateway put-method –rest-api-id YOUR_API_ID –resource-id YOUR_RESOURCE_ID –http-method GET –authorization-type NONE
“`
Configure the GET method for the resource.
“`bash
aws apigateway put-integration –rest-api-id YOUR_API_ID –resource-id YOUR_RESOURCE_ID –http-method GET –type AWS_PROXY –integration-http-method POST –uri arn:aws:apigateway:YOUR_REGION:lambda:path/2015-03-31/functions/YOUR_LAMBDA_FUNCTION_ARN/invocations
“`
Integrate the Lambda function with the API Gateway. Replace `YOUR_REGION` with your AWS region and `YOUR_LAMBDA_FUNCTION_ARN` with the ARN of your Lambda function.
“`bash
aws apigateway deploy-api –rest-api-id YOUR_API_ID –stage-name prod
“`
Deploy the API.
“`bash
aws apigateway get-deployment –rest-api-id YOUR_API_ID –deployment-id YOUR_DEPLOYMENT_ID
“`
Retrieve the API endpoint URL.
This detailed process demonstrates how the CLI streamlines the deployment and configuration process, significantly reducing the manual effort and potential for errors. This level of automation is crucial for efficient serverless development and deployment.
Configuring Triggers for a Function
Triggers are essential for activating serverless functions. They define the events that will cause a function to execute. The choice of trigger depends on the application’s requirements. Common trigger types include HTTP endpoints, event queues, and scheduled events.
- HTTP Endpoints: These are typically created using an API Gateway service. When an HTTP request (e.g., GET, POST) is received by the API Gateway, it invokes the associated serverless function. This allows functions to serve as the backend for web applications and APIs.
- Event Queues: Services like Amazon SQS (Simple Queue Service) allow functions to be triggered by messages placed in a queue. This pattern is useful for asynchronous processing and decoupling different parts of an application. When a message arrives in the queue, the function is invoked to process it.
- Scheduled Events: Services like Amazon CloudWatch Events (now EventBridge) allow functions to be triggered based on a schedule. This enables functions to perform periodic tasks, such as data processing, report generation, or maintenance operations.
Consider a scenario where a function needs to process images uploaded to an S3 bucket. In this case, the S3 bucket can be configured as a trigger. When a new image is uploaded to the bucket, an event is generated, triggering the function. The function then processes the image (e.g., resizing, adding watermarks) and stores the processed image in another S3 bucket.
The event-driven architecture allows for scalable and efficient image processing without the need for a continuously running server.
The configuration of triggers is done using the cloud provider’s console or CLI. For example, configuring an S3 trigger on AWS would involve:
1. Navigating to the Lambda function in the AWS console.
2. Selecting the “Configuration” tab.
3.
Choosing “Triggers” and then “Add trigger”.
4. Selecting “S3” as the trigger source.
5. Specifying the S3 bucket and the event types (e.g., “Object Created (All)”).
6. Configuring any optional filters (e.g., file extension).
7. Saving the configuration.
This configuration will automatically invoke the function whenever a new object is created in the specified S3 bucket, allowing for real-time image processing. This automated process highlights how serverless architectures facilitate event-driven workflows and the ability to build highly responsive applications.
Managing Dependencies and Packages
In a serverless environment, the effective management of dependencies and packages is critical for ensuring code portability, maintainability, and efficient execution. Serverless functions often operate within constrained resource environments, making it essential to optimize the inclusion and utilization of external libraries. Proper dependency management minimizes function size, reduces cold start times, and mitigates potential conflicts. This section details the strategies and tools involved in managing dependencies in serverless applications.
Including External Libraries and Packages
Integrating external libraries and packages into serverless function code is a common practice, facilitating the reuse of pre-built functionalities and reducing development time. The approach varies depending on the programming language and the chosen serverless platform, but the core principles remain consistent.
To incorporate external libraries, several steps are generally followed:
- Identifying Dependencies: The initial step involves identifying the necessary libraries for the function’s operations. This includes libraries for data processing, API interactions, utility functions, and any other required functionality.
- Package Declaration: The dependencies are declared in a configuration file, typically a `package.json` for Node.js or a `requirements.txt` for Python. This file specifies the library names and versions.
- Packaging the Code: The function’s code, along with the declared dependencies, must be packaged for deployment. The serverless platform often handles this process automatically, bundling the required libraries along with the function code.
- Deployment: The packaged code is then deployed to the serverless platform. The platform typically extracts and installs the dependencies in the execution environment before the function is invoked.
For example, in a Python serverless function that uses the `requests` library to make HTTP requests, the `requirements.txt` file would include the line `requests==2.28.1` (or the desired version). When deployed, the serverless platform would automatically install this version of the `requests` library in the function’s execution environment. Similarly, in a Node.js function, the `package.json` file would declare `dependencies: “axios”: “^1.0.0” `, and the platform would install `axios`.
Using Package Managers in Serverless Functions
Package managers, such as npm (Node Package Manager) for JavaScript and pip (Pip Installs Packages) for Python, are essential tools for managing dependencies in serverless functions. They streamline the process of installing, updating, and removing external libraries. These tools also ensure that the correct versions of dependencies are used, which is crucial for avoiding compatibility issues.
The utilization of package managers involves the following key aspects:
- Dependency Installation: Package managers are used to install dependencies locally. For instance, in a Node.js project, `npm install axios` installs the `axios` library and adds it to the `package.json` file. In Python, `pip install requests` installs the `requests` library and adds it to the `requirements.txt` file.
- Dependency Resolution: Package managers resolve dependency conflicts. They ensure that all dependencies and their transitive dependencies are compatible with each other. This is particularly important in serverless environments, where multiple functions may share the same dependencies.
- Version Management: Package managers allow specifying the exact versions or version ranges of dependencies. This is vital for ensuring reproducibility and preventing unexpected behavior changes when dependencies are updated. The use of semantic versioning (SemVer) is highly recommended.
- Bundling for Deployment: Package managers, along with serverless frameworks, facilitate the bundling of dependencies with the function code for deployment. The framework ensures that the necessary libraries are included in the deployment package.
A real-world example demonstrates the importance of version control. Consider a serverless function using a specific version of the `aws-sdk` for interacting with AWS services. If the function is deployed without specifying the version, the platform might use the latest version, which could introduce compatibility issues or break existing functionality. Using `npm install [email protected]` (or the relevant version) in the `package.json` ensures that the function uses the correct version, preventing potential problems.
Example of `package.json` (Node.js):
"name": "my-serverless-function", "version": "1.0.0", "dependencies": "axios": "^1.0.0", "aws-sdk": "^2.1356.0"Example of `requirements.txt` (Python):
requests==2.28.1 boto3==1.26.164
Configuring API Gateway or Equivalent
API gateways are critical components in serverless architectures, acting as the primary entry point for client requests and orchestrating the interaction with backend serverless functions. Their role is multifaceted, encompassing request routing, security enforcement, traffic management, and transformation of data formats. This centralized control layer significantly simplifies client-side interactions while enabling robust and scalable serverless applications.
Role of API Gateways in Exposing Serverless Functions
API gateways function as intermediaries, shielding the complexities of serverless infrastructure from the outside world. They provide a stable, well-defined interface for clients, irrespective of the underlying serverless function implementations which can change and evolve.
- Request Routing: API gateways route incoming requests to the appropriate serverless functions based on configured rules. This routing can be based on HTTP methods (GET, POST, PUT, DELETE), URL paths, headers, or query parameters. For example, a request to `/users` with the GET method might be routed to a `getUsers` function, while a POST request to `/users` would trigger a `createUser` function.
- Authentication and Authorization: They handle authentication, verifying the identity of the client (e.g., using API keys, OAuth, or JWTs), and authorization, determining whether the client has permission to access the requested resource. This security layer prevents unauthorized access to serverless functions and protects sensitive data.
- Traffic Management: API gateways provide rate limiting, throttling, and caching capabilities to manage traffic and prevent overload of serverless functions. Rate limiting restricts the number of requests a client can make within a specific timeframe, while throttling limits the number of concurrent requests. Caching stores frequently accessed responses to reduce latency and improve performance.
- Request and Response Transformation: They can transform request and response payloads, adapting them to the needs of both the client and the serverless functions. This includes format conversion (e.g., JSON to XML), data validation, and header manipulation.
- Monitoring and Logging: API gateways provide centralized logging and monitoring capabilities, enabling developers to track request traffic, identify errors, and gain insights into application performance. This data is essential for debugging, performance optimization, and capacity planning.
Setting Up an API Gateway and Configuring Routes
Setting up an API gateway typically involves selecting a cloud provider’s managed service (e.g., AWS API Gateway, Google Cloud API Gateway, Azure API Management) or deploying a self-managed solution (e.g., Kong, Tyk). The setup process generally involves defining API endpoints, associating them with backend serverless functions, and configuring security and traffic management policies.
- API Definition: Define the API’s structure, including the resources (e.g., `/users`, `/products`) and the HTTP methods (GET, POST, PUT, DELETE) supported for each resource. This definition can be expressed using API description languages such as OpenAPI (formerly known as Swagger).
- Route Configuration: Configure routes that map incoming requests to specific serverless functions. This involves specifying the URL path, HTTP method, and the target function’s invocation details (e.g., function ARN in AWS Lambda).
- Integration with Serverless Functions: Integrate the API gateway with the serverless functions. This involves configuring the gateway to invoke the functions when specific requests are received. The integration method depends on the cloud provider, but often involves specifying the function’s endpoint or ARN.
- Security Configuration: Implement security measures, such as API key authentication, OAuth, or JWT-based authentication, to control access to the API. Configure authorization policies to restrict access based on user roles or permissions.
- Deployment and Testing: Deploy the API gateway configuration and test the API endpoints to ensure they are functioning correctly. This includes testing the routing, security, and request/response transformations.
Example using AWS API Gateway:
Assume a serverless function named `getUser` is deployed in AWS Lambda. To expose this function through API Gateway, the following steps are taken:
- Create an API: Create a new API in the AWS API Gateway console.
- Define a Resource: Create a resource `/users/userId`.
- Create a Method: Create a GET method for the `/users/userId` resource.
- Integrate with Lambda: Configure the GET method to integrate with the `getUser` Lambda function.
- Configure Request Mapping (optional): Configure the request mapping to pass the `userId` from the URL path to the Lambda function’s event object.
- Deploy the API: Deploy the API to a specific stage (e.g., `production`). This generates an API endpoint URL.
Demonstrating Handling Request and Response Transformations within the Gateway
API gateways facilitate data transformation, enabling compatibility between client requests and the format expected by the serverless functions. This flexibility is particularly important when integrating diverse client applications or when serverless functions need to handle different data formats.
- Request Transformation: The API gateway can modify the incoming request before it reaches the serverless function. This includes:
- Header Manipulation: Adding, removing, or modifying HTTP headers.
- Payload Transformation: Converting the request payload from one format to another (e.g., XML to JSON).
- Parameter Mapping: Mapping request parameters to the format expected by the serverless function.
- Response Transformation: The API gateway can modify the response from the serverless function before it is returned to the client. This includes:
- Header Manipulation: Adding, removing, or modifying HTTP headers in the response.
- Payload Transformation: Converting the response payload from one format to another (e.g., JSON to XML).
- Data Masking: Redacting sensitive information from the response.
Example:
Consider a scenario where a client sends a request in XML format, but the serverless function expects JSON. The API gateway can transform the XML payload to JSON before forwarding it to the function. Conversely, if the serverless function returns JSON, the API gateway can transform it back to XML before sending it to the client. The transformation is often achieved using mapping templates, which define how the data should be converted.
Example using AWS API Gateway:
Suppose the client sends an XML request to `/convert`. The API Gateway’s configuration can include:
- Request Mapping Template: A template (e.g., using Velocity Template Language – VTL) to transform the XML payload to JSON before passing it to the Lambda function. The VTL could parse the XML and create a JSON structure.
- Response Mapping Template: A template to transform the JSON response from the Lambda function to XML before returning it to the client. The VTL would format the JSON into an XML structure.
This allows the serverless function to operate on JSON data, while the client can communicate in XML, simplifying the client-server interaction and enabling format independence.
Implementing Authentication and Authorization
Authentication and authorization are crucial security components in any serverless application, ensuring that only authorized users and applications can access specific resources and functionalities. Implementing these features correctly is vital for protecting sensitive data and maintaining the integrity of the application. This section delves into various authentication methods, authorization strategies, and integration with identity providers, providing a comprehensive understanding of securing serverless environments.
Authentication Methods for Serverless Applications
Serverless architectures offer various authentication methods, each with its own strengths and weaknesses. The choice of method depends on the specific requirements of the application, including the level of security needed, the user base, and the existing infrastructure.
- API Keys: API keys are unique, secret identifiers used to authenticate requests. They are simple to implement, making them suitable for authenticating machine-to-machine communication or for securing APIs accessed by third-party applications. However, API keys are less secure than other methods because they are often embedded in the client-side code, which makes them vulnerable to exposure.
- OAuth (Open Authorization): OAuth is an open standard for access delegation, enabling users to grant third-party applications access to their resources without sharing their credentials. It involves a process of obtaining authorization from the user and then receiving an access token, which the application uses to make requests on behalf of the user. OAuth is a more secure and flexible option for authenticating users, especially in applications that interact with multiple services or platforms.
The most common OAuth flows are:
- Authorization Code Grant: A server-side flow where the application exchanges an authorization code for an access token.
- Implicit Grant: A client-side flow where the application receives the access token directly.
- Resource Owner Password Credentials Grant: A flow where the application requests the user’s credentials.
- Client Credentials Grant: A flow where the application authenticates with its own credentials.
- JSON Web Tokens (JWTs): JWTs are a standardized way to securely transmit information between parties as a JSON object. They are often used for authentication, where a user’s identity is encoded in a JWT after successful login. The JWT is then included in subsequent requests to authenticate the user. JWTs are stateless, making them well-suited for serverless architectures.
- Custom Authentication: In some cases, applications may require custom authentication methods. This can involve using a database to store user credentials, implementing custom login forms, or integrating with existing authentication systems. Custom authentication provides the most flexibility but also requires more development effort and careful consideration of security best practices.
Implementing Authorization Rules
Authorization determines what authenticated users or applications are allowed to access. It defines the permissions and roles that govern access to specific resources and functions within the serverless application.
- Role-Based Access Control (RBAC): RBAC assigns permissions to roles, and users are then assigned to those roles. This simplifies the management of access control, as changes to permissions only need to be made at the role level.
- Attribute-Based Access Control (ABAC): ABAC allows for more granular control by evaluating attributes of the user, the resource, and the environment to determine access. This provides greater flexibility and control but also increases complexity.
- Policy Enforcement: Authorization policies can be implemented within the serverless functions themselves, or by utilizing dedicated authorization services, like AWS IAM, Google Cloud IAM, or Azure Active Directory. These policies define the rules that govern access to resources.
- Authorization Strategies: Common authorization strategies include:
- Function-Level Authorization: Access control is implemented directly within the serverless function.
- Resource-Level Authorization: Access control is applied to specific resources, such as data in a database or files in a storage bucket.
- API Gateway Authorization: The API gateway can be configured to perform authorization checks before invoking the serverless functions.
Integrating with Identity Providers
Integrating with identity providers (IdPs) simplifies user authentication and authorization by leveraging existing user directories and authentication services. This reduces the development effort and improves security by outsourcing authentication to a trusted provider.
- Popular Identity Providers: Examples of IdPs include:
- AWS Cognito: A fully managed service for user authentication, authorization, and user management.
- Google Identity Platform: Provides authentication and authorization services for web and mobile applications.
- Azure Active Directory B2C: A cloud identity management service for building customer-facing applications.
- Okta: A cloud-based identity and access management platform.
- Auth0: A comprehensive identity platform that offers authentication, authorization, and user management.
- Integration Process: The integration process typically involves the following steps:
- Setting up an account with the IdP: This involves creating an account and configuring the necessary settings.
- Configuring the serverless application: The serverless application needs to be configured to use the IdP for authentication. This may involve configuring API Gateway to use the IdP for authentication.
- Implementing the authentication flow: The application needs to implement the authentication flow, which typically involves redirecting the user to the IdP for authentication and then receiving an access token or JWT.
- Verifying the token: The serverless functions need to verify the access token or JWT to ensure that the user is authenticated.
- Implementing authorization: The serverless functions need to implement authorization rules to control access to resources based on the user’s roles or permissions.
- Benefits of Integration: Integrating with IdPs offers several benefits:
- Simplified authentication: Reduces the need to build and maintain a custom authentication system.
- Improved security: Leverages the security expertise of the IdP.
- Scalability: IdPs are designed to handle large numbers of users and authentication requests.
- User experience: Provides a familiar and user-friendly authentication experience.
Monitoring and Logging
Setting up robust monitoring and logging is crucial for the operational health of a serverless development environment. It enables proactive identification of issues, performance optimization, and informed decision-making. Comprehensive monitoring and logging strategies are essential for debugging, understanding application behavior, and ensuring the reliability and scalability of serverless applications.
Setting Up Monitoring and Logging for Serverless Functions
Properly configuring monitoring and logging involves integrating services provided by the chosen cloud provider. This typically includes services for log aggregation, metric collection, and alerting. The goal is to capture and analyze relevant data points from function executions to gain insights into performance and identify potential problems.
- Cloud Provider-Specific Services: Most cloud providers offer built-in services tailored for serverless applications. For example, AWS provides CloudWatch for logging and monitoring, Google Cloud offers Cloud Logging and Cloud Monitoring, and Azure uses Azure Monitor and Application Insights. These services typically offer automatic integration with serverless function platforms.
- Log Configuration: Serverless functions need to be configured to output logs. This usually involves using the cloud provider’s SDK or logging libraries to write logs to a designated location. Log levels (e.g., INFO, WARNING, ERROR) should be used to categorize log messages.
- Metric Collection: Key metrics, such as function invocation count, execution duration, memory usage, and error rates, are automatically collected by the cloud provider’s monitoring services. Custom metrics can also be defined and emitted from within the function code to track application-specific behavior.
- Alerting Configuration: Alerts can be configured to trigger notifications based on specific conditions, such as exceeding error thresholds or function execution times. These alerts can be sent via email, SMS, or integrated with other notification systems.
- Integration with Third-Party Tools: While cloud provider services are often sufficient, integrations with third-party monitoring and logging tools (e.g., Datadog, New Relic, Splunk) are possible for more advanced features and centralized log management.
Accessing and Analyzing Logs to Debug Issues
Effective debugging relies on the ability to access and analyze logs efficiently. This involves using tools and techniques to filter, search, and correlate log entries to pinpoint the root cause of issues. Analyzing logs is essential for understanding the behavior of functions and identifying performance bottlenecks.
- Log Aggregation and Storage: Logs from serverless functions are typically aggregated and stored in a centralized location, such as a cloud provider’s logging service. The storage duration and retention policies should be configured to meet the application’s needs and compliance requirements.
- Log Search and Filtering: Cloud provider services provide tools for searching and filtering logs based on various criteria, such as timestamps, log levels, function names, and specific s or error messages. Regular expressions can be used for more complex search patterns.
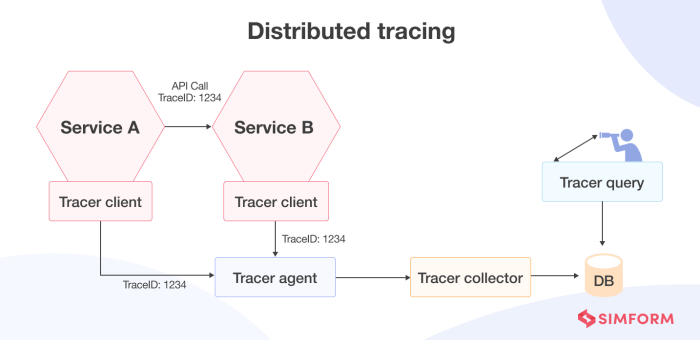
- Log Correlation: Correlating logs across multiple functions and services is essential for tracing the flow of requests and understanding how different components interact. This can be achieved by using unique request IDs or tracing headers that are propagated across function invocations.
- Error Analysis: Detailed error messages and stack traces should be included in log entries to provide information about the cause of errors. Tools for analyzing error patterns and identifying common failure modes are also valuable.
- Log Visualization: Visualizing log data through charts and dashboards can help identify trends and anomalies. Some logging services provide built-in visualization capabilities, while others can integrate with dedicated visualization tools.
Using Monitoring Dashboards to Track Function Performance
Monitoring dashboards provide a visual overview of function performance, allowing for real-time monitoring and proactive issue detection. These dashboards typically display key metrics, such as invocation counts, execution times, error rates, and resource utilization.
- Key Metrics to Track:
- Invocation Count: The number of times a function is executed.
- Execution Duration: The time it takes for a function to complete.
- Error Rate: The percentage of function invocations that result in errors.
- Memory Usage: The amount of memory consumed by a function during execution.
- Cold Start Times: The time it takes for a function to start running when it has not been recently invoked.
- Dashboard Customization: Monitoring dashboards can be customized to display the most relevant metrics for a specific application. This includes selecting the metrics to display, defining thresholds for alerts, and configuring the time range for data analysis.
- Real-time Monitoring: Dashboards provide real-time insights into function performance, allowing for immediate detection of issues. For example, a sudden increase in error rates or execution times can indicate a problem that requires investigation.
- Alerting Integration: Monitoring dashboards are often integrated with alerting systems. When metrics exceed predefined thresholds, alerts can be triggered to notify the appropriate teams.
- Historical Data Analysis: Dashboards provide access to historical performance data, which can be used to identify trends, optimize function configurations, and plan for future capacity.
Version Control and CI/CD for Serverless
Integrating version control and implementing Continuous Integration/Continuous Deployment (CI/CD) pipelines are crucial for managing serverless projects effectively. These practices enhance collaboration, streamline deployments, and enable rapid iteration. This section will delve into the specifics of integrating serverless projects with version control systems, setting up CI/CD pipelines, and utilizing feature flags for testing and releasing new versions.
Integrating with Version Control Systems
Version control systems, such as Git, are essential for tracking changes, managing different versions of code, and facilitating collaboration among developers. Integrating serverless projects with Git provides several benefits.
- Tracking Code Changes: Every modification to the codebase, including function code, infrastructure definitions (e.g., using Infrastructure as Code tools like AWS CloudFormation, Terraform, or Serverless Framework), and configuration files, is tracked. This allows developers to revert to previous versions if necessary and understand the evolution of the project.
- Collaboration: Git enables multiple developers to work concurrently on the same project. Features like branching and merging allow developers to work on isolated features without affecting the main codebase.
- Code Reviews: Using pull requests in platforms like GitHub, GitLab, or Bitbucket enables code reviews, where other developers can examine the code, suggest improvements, and ensure code quality before merging changes into the main branch.
- Version Control for Infrastructure: Serverless projects often involve infrastructure definitions (e.g., API Gateway configurations, database settings). Version controlling these configurations alongside the function code ensures that infrastructure changes are also tracked and managed, preventing inconsistencies.
To integrate a serverless project with Git:
- Initialize a Git Repository: In the root directory of your serverless project, initialize a Git repository using the command:
git init. This creates a hidden.gitdirectory that stores the version history. - Add Files to the Repository: Add all project files, including function code, configuration files, and infrastructure definitions, to the staging area using:
git add .. - Commit Changes: Commit the staged changes with a descriptive message using:
git commit -m "Initial commit: Project setup". Use clear and concise commit messages to describe the changes made. - Create Branches: Create branches for new features or bug fixes using:
git checkout -b feature/new-feature. Work on the feature in this branch. - Commit Changes in Branches: Commit changes related to the new feature within the feature branch.
- Merge Branches: Once the feature is complete and reviewed, merge the feature branch into the main branch (e.g.,
mainormaster) using:git checkout mainand thengit merge feature/new-feature. Resolve any merge conflicts if necessary. - Push to Remote Repository: Push the local repository to a remote repository (e.g., GitHub, GitLab, or Bitbucket) to enable collaboration and backup. Use commands like
git remote add originandgit push -u origin main.
Setting Up a CI/CD Pipeline
A CI/CD pipeline automates the build, test, and deployment processes, enabling faster and more reliable releases. For serverless projects, the pipeline typically involves the following stages:
- Code Commit: Developers commit code changes to the version control system (e.g., Git).
- Trigger: The CI/CD system (e.g., GitHub Actions, GitLab CI, AWS CodePipeline, Azure DevOps) is triggered by a code commit, pull request, or scheduled event.
- Build: The CI/CD system builds the project, which may involve compiling code, installing dependencies, and packaging the function code.
- Test: Automated tests (unit tests, integration tests) are executed to verify the code’s functionality and quality.
- Deploy: If the tests pass, the code is deployed to a serverless environment (e.g., AWS Lambda, Azure Functions, Google Cloud Functions). This typically involves updating the function code, infrastructure configuration, and API Gateway settings.
- Monitoring: After deployment, the pipeline can automatically monitor the deployed functions for errors, performance issues, and other metrics.
Here’s an example of setting up a CI/CD pipeline using GitHub Actions for a serverless function deployed to AWS Lambda.
- Create a GitHub Repository: Create a repository on GitHub and push your serverless project code to it.
- Create an IAM Role: Create an AWS IAM role with the necessary permissions for the CI/CD system to deploy to AWS Lambda and other AWS services. This role needs permissions to create, update, and delete Lambda functions, API Gateway, and other relevant resources. Store the role’s ARN securely.
- Configure GitHub Secrets: In your GitHub repository, go to “Settings” -> “Secrets” -> “Actions”. Create the following secrets:
AWS_ACCESS_KEY_ID: Your AWS access key ID.AWS_SECRET_ACCESS_KEY: Your AWS secret access key.AWS_REGION: The AWS region (e.g.,us-east-1).AWS_ROLE_ARN: The ARN of the IAM role created in step 2.
- Create a Workflow File: Create a YAML file (e.g.,
.github/workflows/deploy.yml) in your repository. This file defines the CI/CD workflow. An example workflow for deploying a Python-based serverless function to AWS Lambda using the Serverless Framework might look like this:name: Deploy Serverless Functionon: push: branches: -mainjobs: deploy: runs-on: ubuntu-latest steps: -name: Checkout code uses: actions/checkout@v3 -name: Configure AWS credentials uses: aws-actions/configure-aws-credentials@v1 with: role-to-assume: $ secrets.AWS_ROLE_ARN aws-region: $ secrets.AWS_REGION -name: Set up Python uses: actions/setup-python@v4 with: python-version: '3.9' -name: Install Serverless Framework run: npm install -g serverless -name: Deploy Serverless Function run: serverless deploy --stage production - Test and Deploy: Push the workflow file to the repository. GitHub Actions will automatically run the workflow, building, testing, and deploying the serverless function to AWS Lambda. The
--stage productionflag specifies the deployment stage. Consider using different stages (e.g., development, staging, production) to manage deployments to different environments.
Using Feature Flags for Testing and Releasing New Versions
Feature flags (also known as feature toggles) are a powerful technique for managing software releases and enabling controlled rollout of new features. They allow developers to deploy code with new features disabled and enable them selectively, based on certain criteria.
- Controlled Rollouts: Feature flags enable a gradual rollout of new features to a subset of users or environments, allowing for monitoring and feedback before a full release.
- A/B Testing: Feature flags can be used to enable different versions of a feature for different user segments, facilitating A/B testing to compare the performance of different implementations.
- Emergency Kill Switch: If a new feature causes issues in production, feature flags provide an “emergency kill switch” to quickly disable the feature without deploying a code rollback.
Implementing feature flags in a serverless environment often involves:
- Feature Flag Management: Use a feature flag management service (e.g., LaunchDarkly, Flagsmith, or custom solutions). These services provide a central place to define, manage, and update feature flags.
- Conditional Logic in Code: Integrate the feature flag management service into your serverless function code. Use conditional statements (e.g.,
if/else) to check the state of a feature flag and execute different code paths based on the flag’s value (enabled or disabled). - Configuration and Targeting: Configure the feature flag management service to control which users or environments have access to the new feature. This can be based on user attributes (e.g., user ID, role, location), environment variables (e.g., deployment stage), or other criteria.
Example using LaunchDarkly and a Python-based AWS Lambda function:
- Sign up for LaunchDarkly: Create an account and obtain your LaunchDarkly SDK key.
- Install the LaunchDarkly SDK: Install the LaunchDarkly Python SDK in your serverless function’s dependencies. For example, using pip:
pip install launchdarkly-server-sdk. - Initialize the LaunchDarkly Client: In your Lambda function’s code, initialize the LaunchDarkly client with your SDK key.
- Check Feature Flag Status: Use the LaunchDarkly client to check the status of a feature flag and execute code accordingly.
import jsonimport boto3from launchdarkly.client import LDClient# Initialize LaunchDarkly clientld_client = LDClient(sdk_key='YOUR_LAUNCHDARKLY_SDK_KEY')def lambda_handler(event, context): # Define a user user = 'key': 'unique-user-id', 'name': 'Test User', # Check the status of the "new-feature" flag new_feature_enabled = ld_client.variation('new-feature', user, False) # Default value is False if flag is not found if new_feature_enabled: # Execute the new feature code message = "New feature is enabled!" else: # Execute the old feature code message = "Old feature is active." ld_client.close() # Close the LaunchDarkly client return 'statusCode': 200, 'body': json.dumps( 'message': message ) - Configure LaunchDarkly: In the LaunchDarkly dashboard, create a feature flag named “new-feature”. Set the flag’s default value (e.g., disabled). Target specific users or environments to enable the feature for testing and rollout.
Testing Serverless Functions
Testing is a critical component of any software development lifecycle, and serverless architectures are no exception. Rigorous testing ensures the reliability, performance, and security of serverless functions, ultimately contributing to a stable and scalable application. Neglecting testing can lead to unexpected behavior, increased debugging time, and potential security vulnerabilities. Comprehensive testing strategies are crucial for validating the various aspects of serverless functions, including their logic, integration with other services, and ability to handle different input scenarios.
Importance of Testing Serverless Functions
The nature of serverless functions, being event-driven and often interacting with various cloud services, necessitates a robust testing approach. Without adequate testing, developers risk deploying functions that malfunction in production, leading to downtime, data loss, and a poor user experience.
- Verification of Functionality: Testing confirms that functions perform their intended tasks correctly, validating their core logic and data processing capabilities. For example, a function designed to process image uploads should be tested to ensure it correctly resizes, stores, and returns the appropriate metadata.
- Performance Evaluation: Testing helps assess the function’s performance under various load conditions. This includes measuring execution time, memory usage, and the ability to handle concurrent requests. For instance, a serverless function that generates thumbnails should be tested to determine its latency under high traffic.
- Security Assurance: Testing is essential for identifying and mitigating security vulnerabilities, such as injection flaws, authentication failures, and unauthorized access. Security testing should include penetration testing and vulnerability scanning to ensure the function is resilient against attacks.
- Integration Validation: Serverless functions often interact with other cloud services like databases, storage buckets, and message queues. Testing ensures these integrations function correctly and that data flows seamlessly between services. For example, testing an API gateway that invokes a serverless function that updates a database requires testing the API gateway’s input handling and the function’s database interaction.
- Cost Optimization: By identifying and resolving performance bottlenecks early in the development cycle, testing helps optimize function execution time and resource usage, leading to cost savings. Monitoring function metrics like execution time and memory consumption helps identify areas for optimization.
Unit Testing Serverless Functions
Unit testing is a fundamental practice for verifying the functionality of individual serverless functions. This involves testing the smallest testable parts of an application, such as a single function or a specific method within a function, in isolation. Unit tests should be designed to cover different scenarios and input conditions to ensure the function behaves as expected.
Key aspects of unit testing serverless functions:
- Test Frameworks: Choose a testing framework compatible with the programming language used for the functions. Popular choices include Jest (JavaScript/Node.js), pytest (Python), and JUnit (Java). These frameworks provide features like test runners, assertion libraries, and mocking capabilities.
- Test Doubles (Mocks, Stubs, Spies): When a function interacts with external dependencies (e.g., databases, APIs), use test doubles to isolate the function under test. Mocks simulate the behavior of these dependencies, allowing you to control the input and output of the dependencies during the test. Stubs provide pre-programmed responses to function calls, and spies track how a function interacts with its dependencies.
- Test Coverage: Aim for high test coverage, ensuring that most of the function’s code is exercised by unit tests. Test coverage metrics help identify areas of the code that are not adequately tested. Tools that generate test coverage reports help developers identify gaps in their testing.
- Arrange-Act-Assert: Structure unit tests using the “Arrange-Act-Assert” pattern:
- Arrange: Set up the test environment, including any necessary data or mocks.
- Act: Execute the function being tested with specific inputs.
- Assert: Verify that the function’s output or behavior matches the expected results.
- Example (Python with pytest): Consider a function that calculates the sum of two numbers. A unit test would arrange the input values, act by calling the function, and assert that the returned sum is correct.
Testing Functions Locally and Remotely
Testing serverless functions can be performed both locally and remotely. Local testing allows for rapid iteration and debugging, while remote testing validates the function’s behavior in a cloud environment.
Local Testing:
- Emulators and Mock Services: Use emulators or mock services to simulate cloud services locally. For example, AWS SAM (Serverless Application Model) CLI provides a local environment for testing functions, API Gateway, and other serverless resources.
- Local Invocation: Invoke the function locally with various input events and check the output. Testing frameworks allow you to simulate different event types, such as HTTP requests, database updates, and message queue events.
- Debugging: Utilize local debugging tools to step through the function’s code, inspect variables, and identify any issues. Integrated development environments (IDEs) often provide built-in debugging capabilities.
- Example (Node.js with AWS SAM CLI): You can use the `sam local invoke` command to invoke a function locally, passing in a JSON event payload. This allows you to test the function without deploying it to the cloud.
Remote Testing:
- Cloud Provider’s Testing Tools: Cloud providers offer tools and services for testing deployed functions. For instance, AWS Lambda provides a test invocation feature within its console.
- API Gateway Testing: Test the function’s interaction with the API gateway, including authentication, authorization, and request/response handling. This can involve sending test requests to the API endpoints and verifying the function’s responses.
- Integration Tests: Perform integration tests to validate the function’s interaction with other cloud services and external APIs. This includes testing data flow, error handling, and overall system behavior.
- Deployment Pipelines: Integrate testing into deployment pipelines (CI/CD) to automate the testing process. This ensures that every code change is tested before deployment to production. Tools like Jenkins, GitLab CI, and GitHub Actions can be used to automate testing.
- Example (AWS Lambda Test Invocation): In the AWS Lambda console, you can configure test events with various input data, and then invoke the function. This allows you to test the function in a real cloud environment.
Last Point
In conclusion, establishing a serverless development environment represents a significant advancement in software engineering, offering substantial benefits in terms of scalability, cost-effectiveness, and developer productivity. This guide has provided a roadmap for navigating the complexities of setting up such an environment, from selecting a cloud provider and configuring access to deploying and monitoring serverless functions. By embracing the principles and practices Artikeld here, developers can unlock the full potential of serverless computing and build more agile, resilient, and innovative applications.
The future of application development is undoubtedly serverless, and the knowledge gained from this guide will serve as a valuable asset in navigating this evolving landscape.
Expert Answers
What is the primary advantage of using a serverless environment?
The primary advantage is the automatic scaling and pay-per-use model, which reduces operational overhead and cost compared to traditional server setups.
How does serverless differ from traditional cloud computing?
Serverless abstracts away the need to manage servers. Developers focus on writing code, while the cloud provider handles infrastructure provisioning, scaling, and maintenance.
What are the common programming languages supported by serverless platforms?
Most platforms support popular languages like Node.js, Python, Java, Go, and .NET. Support can vary by provider.
How do I debug serverless functions?
Debugging involves using cloud provider-specific logging, monitoring tools, and local testing frameworks. These tools provide insights into function execution and potential errors.
Is serverless suitable for all types of applications?
Serverless is well-suited for event-driven applications, APIs, and background tasks. It may not be ideal for applications requiring very long-running processes or constant resource allocation.