Resource allocation strategies for serverless data analytics are fundamentally reshaping the landscape of data processing. This shift, driven by the need for scalable, cost-effective, and agile solutions, necessitates a deep understanding of how to optimize resource utilization within serverless architectures. The inherent characteristics of serverless computing, such as pay-per-use models and automatic scaling, present both opportunities and challenges for data professionals.
Effective resource allocation is not merely about cost savings; it is critical for ensuring optimal performance, minimizing latency, and maximizing the efficiency of data pipelines.
This discussion will explore the core principles of serverless data analytics, covering everything from the fundamentals of serverless computing to advanced techniques for cost optimization, security, and monitoring. We will dissect the nuances of resource consumption, analyze strategies for optimizing compute resources, and examine how to choose the right data storage and retrieval solutions. Furthermore, we will delve into the practical aspects of implementing event-driven architectures, scaling serverless workloads, and securing sensitive data within these dynamic environments.
The ultimate goal is to equip readers with the knowledge and practical insights needed to build robust, scalable, and cost-efficient serverless data analytics solutions.
Serverless Data Analytics Fundamentals
Serverless data analytics represents a paradigm shift in how data processing workloads are designed, deployed, and managed. This approach leverages cloud-based services to execute code without the need for server provisioning or management. This allows developers to focus on writing code and analyzing data, rather than dealing with the underlying infrastructure. The core tenets of serverless computing, when applied to data analytics, provide significant advantages in terms of scalability, cost-efficiency, and developer productivity.
Core Principles of Serverless Computing in Data Processing
Serverless computing in the context of data processing revolves around several key principles that distinguish it from traditional infrastructure models. These principles contribute to its agility, scalability, and cost-effectiveness.* Event-Driven Architecture: Serverless functions are typically triggered by events. These events can include data uploads, database updates, scheduled timers, or API requests. This event-driven nature allows for highly responsive and scalable data processing pipelines.* Function-as-a-Service (FaaS): At its core, serverless is about FaaS.
This model allows developers to deploy individual functions that execute in response to events. The cloud provider manages the underlying infrastructure, including server provisioning, scaling, and patching.* Automatic Scaling: Serverless platforms automatically scale the resources allocated to functions based on demand. This eliminates the need for manual scaling, ensuring that data processing workloads can handle fluctuating data volumes and user traffic.* Pay-per-Use Pricing: Serverless providers typically charge based on the actual execution time and resources consumed by functions.
This pay-per-use model can significantly reduce costs compared to traditional infrastructure, especially for workloads with variable or spiky traffic patterns.* Stateless Functions: Serverless functions are generally designed to be stateless. This means that each function invocation is independent and does not rely on the state of previous invocations. This stateless design simplifies scaling and fault tolerance.
Serverless Architecture versus Traditional Infrastructure for Data Analytics Workloads
The choice between serverless architecture and traditional infrastructure for data analytics workloads depends on various factors, including the nature of the workload, budget constraints, and the desired level of operational overhead. Comparing these architectures highlights their respective strengths and weaknesses.
| Feature | Serverless Architecture | Traditional Infrastructure |
|---|---|---|
| Infrastructure Management | Managed by the cloud provider. | Requires manual provisioning, configuration, and maintenance of servers. |
| Scalability | Automatic and elastic scaling based on demand. | Requires manual scaling, potentially leading to over-provisioning or under-provisioning. |
| Cost | Pay-per-use pricing, potentially lower costs for variable workloads. | Fixed costs for infrastructure, regardless of usage. |
| Deployment | Simplified deployment of individual functions. | More complex deployment processes involving server configuration and application deployment. |
| Operational Overhead | Reduced operational overhead due to automated infrastructure management. | Higher operational overhead due to server management tasks. |
| Development Time | Faster development cycles due to simplified deployment and management. | Slower development cycles due to infrastructure setup and management. |
For instance, consider a scenario where a company processes data from IoT devices. With serverless, the data ingestion and processing pipelines can automatically scale to handle spikes in data volume during peak hours without requiring manual intervention. Conversely, in a traditional infrastructure setup, the company would need to pre-provision resources to accommodate peak loads, leading to potential over-provisioning and wasted resources during off-peak hours.
Advantages of Using Serverless Functions for ETL Processes
Serverless functions offer several advantages when implementing ETL (Extract, Transform, Load) processes, making them a compelling choice for modern data pipelines.* Scalability and Elasticity: Serverless functions automatically scale to handle varying data volumes and processing demands. This is particularly beneficial for ETL processes that need to handle large datasets or experience unpredictable data ingestion rates.* Cost Efficiency: Pay-per-use pricing models in serverless environments can significantly reduce costs, especially for ETL pipelines that are not continuously running.
Costs are incurred only when the functions are actively processing data.* Simplified Deployment and Management: Serverless functions simplify the deployment and management of ETL workflows. Developers can focus on writing code and defining data transformation logic without worrying about server provisioning, configuration, or maintenance.* Improved Agility and Time-to-Market: Serverless architectures enable faster development cycles and quicker time-to-market for data-driven applications.
The simplified deployment process and automated scaling capabilities allow for rapid iteration and deployment of ETL pipelines.* Event-Driven Triggering: Serverless functions can be triggered by various events, such as new data uploads, database changes, or scheduled tasks. This event-driven nature allows for real-time or near-real-time data processing, enabling timely insights and decision-making.For example, a retail company can use serverless functions to build an ETL pipeline that extracts sales data from various sources (e.g., point-of-sale systems, e-commerce platforms), transforms the data (e.g., cleaning, aggregating, and enriching), and loads it into a data warehouse for analysis.
The serverless architecture automatically scales to handle peak sales periods, ensuring that the data warehouse is up-to-date and providing accurate insights.
Understanding Resource Consumption in Serverless Environments
Serverless data analytics offers significant advantages in terms of scalability and cost-effectiveness. However, a thorough understanding of resource consumption is crucial for optimizing performance and managing expenses. This section delves into the mechanics of resource measurement and billing within serverless platforms, examines the factors that impact costs, and provides a practical scenario for monitoring resource usage.
Resource Measurement and Billing
Serverless platforms employ a pay-per-use model, where resource consumption is precisely measured and billed. This approach contrasts with traditional infrastructure, where resources are provisioned and paid for regardless of actual utilization. The core metrics for resource consumption typically include compute time, memory allocation, and network I/O.
- Compute Time: This represents the duration for which a serverless function executes. It is typically measured in milliseconds (ms) or seconds (s). The billing is often based on the total compute time consumed during a function invocation, including the time spent initializing the function environment (cold starts) and the actual execution time.
- Memory Allocation: Serverless functions are allocated a specific amount of memory. The billing reflects the amount of memory provisioned for the function during its execution. The cost is determined by the memory allocated per second or millisecond, depending on the platform’s pricing model.
- Network I/O: Data transfer operations, such as retrieving data from a storage service or sending results to a client, incur network charges. These charges are based on the volume of data transferred (in GB or TB) and the direction of the transfer (inbound or outbound).
- Requests: The number of function invocations or requests also affects the cost. Some platforms charge a small fee per request, in addition to the compute time and memory usage.
Factors Influencing Cost
Several factors can significantly influence the cost of running serverless data analytics jobs. Optimizing these factors is essential for cost management.
- Function Execution Time: Reducing the execution time of a function directly translates to lower costs. Optimizations such as efficient code, optimized libraries, and proper data access patterns can minimize execution time.
- Memory Allocation: Allocating the optimal amount of memory is crucial. Over-provisioning memory leads to unnecessary costs, while under-provisioning can result in performance degradation. Careful monitoring and testing are required to determine the appropriate memory allocation.
- Cold Starts: Cold starts, where the function environment needs to be initialized, can increase execution time and thus costs. Techniques like function pre-warming or utilizing provisioned concurrency can mitigate the impact of cold starts.
- Data Transfer Costs: Transferring large volumes of data in and out of the function environment can be expensive. Optimizing data storage, compression, and data transfer patterns can reduce these costs. For example, using efficient data formats (e.g., Parquet) and compressing data before transferring it can significantly reduce storage and transfer costs.
- Concurrency: The number of concurrent function instances running simultaneously can affect costs. Managing concurrency, especially during peak load, is essential for cost optimization.
- Platform-Specific Pricing: Different serverless platforms (e.g., AWS Lambda, Azure Functions, Google Cloud Functions) have different pricing models. The pricing can vary based on factors such as the region where the function is deployed, the specific services used, and the volume of data processed. Choosing the most cost-effective platform and region is crucial.
Monitoring Resource Consumption Scenario
Consider a scenario where a serverless data pipeline processes clickstream data. The pipeline comprises several serverless functions:
- Ingest Function: Ingests raw clickstream data from an API endpoint and stores it in a data lake (e.g., Amazon S3, Azure Data Lake Storage, Google Cloud Storage).
- Transform Function: Cleans, transforms, and enriches the data (e.g., data aggregation, filtering, and joining with other datasets).
- Analyze Function: Performs analytical queries and generates reports.
The following steps Artikel how to monitor resource consumption:
- Platform-Specific Monitoring Tools: Utilize the monitoring tools provided by the serverless platform (e.g., AWS CloudWatch, Azure Monitor, Google Cloud Operations). These tools provide detailed metrics on function execution time, memory usage, network I/O, and the number of invocations.
- Custom Metrics: Implement custom metrics within the functions to track specific aspects of the data processing, such as the size of the input data, the size of the output data, and the time spent on specific operations.
- Dashboard Creation: Create a dashboard to visualize the key metrics. This dashboard should include graphs for function execution time, memory usage, the number of invocations, and cost estimates.
- Alerting: Set up alerts to be notified when resource consumption exceeds predefined thresholds. This can help to identify and address potential cost spikes or performance issues.
- Testing and Optimization: Continuously test the functions with different datasets and workloads to identify bottlenecks and optimize resource usage. Regularly review the monitoring data to identify areas for improvement.
An example table showing hypothetical monitoring data for the Transform Function might look like this:
| Metric | Value | Unit | Notes |
|---|---|---|---|
| Execution Time | 500 | ms | Average execution time per invocation. |
| Memory Usage | 256 | MB | Allocated memory during function execution. |
| Invocations | 1000 | Count | Number of times the function was invoked. |
| Data Input Size | 10 | MB | Average size of input data per invocation. |
| Data Output Size | 5 | MB | Average size of output data per invocation. |
This table provides a snapshot of the Transform Function’s performance. By analyzing these metrics, developers can identify potential areas for optimization. For example, if the execution time is consistently high, they might consider optimizing the code or increasing the allocated memory. If the data input size is large, they might investigate data compression techniques. The cost can be estimated using the platform’s pricing model based on these metrics.
This data-driven approach ensures that resource consumption is monitored effectively, and costs are optimized.
Strategies for Optimizing Compute Resources
Optimizing compute resources is crucial for cost-effective and performant serverless data analytics. Efficient resource utilization directly translates to lower operational expenses and improved query execution times. This section explores practical strategies for maximizing the efficiency of serverless functions in the context of data analytics workloads.
Right-Sizing Serverless Function Memory Allocation
Appropriately allocating memory to serverless functions is a key factor in optimizing performance and cost. Over-provisioning leads to unnecessary expense, while under-provisioning can severely impact performance and potentially lead to function failures.To determine the optimal memory allocation, several factors must be considered:
- Workload Characteristics: The computational demands of the function, including data processing complexity, the size of the input data, and the number of operations performed. Functions that involve complex calculations or large datasets will generally require more memory.
- Execution Time: Longer execution times often indicate a need for more memory. Monitoring function duration can help identify memory-related bottlenecks.
- Error Rate: High error rates, especially memory-related errors, suggest that the function is likely under-provisioned.
- Concurrency: The number of concurrent function invocations can influence memory requirements. A higher concurrency level might necessitate increased memory allocation.
Monitoring and analyzing function performance metrics are essential for right-sizing. Cloud providers typically offer tools for monitoring memory usage, execution time, and error rates. These metrics can be used to iteratively adjust memory allocation until the function achieves optimal performance and cost efficiency.Consider this example: A serverless function processes CSV files containing sales data. Initially, the function is allocated 128MB of memory and consistently times out on larger files.
Monitoring reveals that the function consistently utilizes over 128MB. Increasing the memory allocation to 256MB reduces the execution time and eliminates timeouts, without a significant increase in cost. Further monitoring could determine if even higher memory allocations offer diminishing returns.
Minimizing Function Cold Start Times
Cold starts, the initial latency incurred when a serverless function is invoked after a period of inactivity, can significantly impact the performance of data analytics pipelines. Minimizing these cold start times is essential for ensuring responsiveness and maintaining a positive user experience. Several techniques can be employed to mitigate this issue:
- Increase Memory Allocation: Allocating more memory can improve cold start times by providing more resources for function initialization.
- Optimize Code: Efficient code is crucial. Reduce dependencies, streamline initialization processes, and minimize the size of the deployment package.
- Use Warm Containers (if available): Some serverless platforms offer “warm container” features, where instances of the function are kept active for a certain period. This can dramatically reduce cold start times for subsequent invocations.
- Provisioned Concurrency: Platforms like AWS Lambda offer provisioned concurrency, where a specific number of function instances are pre-initialized and ready to serve requests. This guarantees low latency.
- Reduce Dependencies: Minimize the number and size of external dependencies. Large dependencies take longer to load during function initialization.
- Choose the Right Runtime: Different runtimes (e.g., Python, Node.js, Java) have varying cold start characteristics. Selecting the appropriate runtime for the workload can impact startup times.
Consider a data pipeline where a serverless function is triggered by new data arriving in an object storage bucket. If cold starts are frequent, the overall pipeline latency will be impacted. Implementing techniques such as increasing memory allocation or using provisioned concurrency can significantly improve the pipeline’s responsiveness. For instance, a function using a provisioned concurrency setting of 100 can ensure that 100 function instances are always available, ready to process requests immediately, without incurring the cold start penalty.
Leveraging Concurrency Controls to Manage Resource Usage
Concurrency controls provide a mechanism for managing the number of concurrent function invocations, thereby controlling resource usage and preventing overload. Properly configuring concurrency limits is critical for maintaining system stability, preventing unexpected costs, and optimizing performance.Concurrency controls can be implemented in several ways:
- Platform-Specific Limits: Serverless platforms typically provide default concurrency limits. These limits can often be adjusted to meet specific workload requirements.
- Provisioned Concurrency: As mentioned previously, this approach pre-provisions function instances, offering a guaranteed level of concurrency.
- Queueing Systems: Using a queueing system (e.g., Amazon SQS, Google Cloud Pub/Sub) can decouple the function invocation from the trigger event. This allows for smoothing out bursts of requests and managing concurrency effectively.
- Rate Limiting: Implementing rate limiting mechanisms can control the number of requests that are processed within a given time frame. This helps to prevent overloading the function and underlying resources.
The choice of concurrency control strategy depends on the specific requirements of the data analytics workload. For example, a high-volume data ingestion pipeline might benefit from using a queueing system to buffer incoming data and manage concurrency. A reporting function with unpredictable load might benefit from rate limiting to prevent runaway costs.Consider a serverless function processing log files. If a sudden surge in log data overwhelms the function, it can lead to timeouts and data loss.
By setting a concurrency limit, the system can throttle the number of concurrent function invocations, preventing overload and ensuring that all data is processed, even if at a slightly slower rate. If the function’s average execution time is known and the desired processing time is defined, the concurrency limit can be calculated to match those constraints. For example, if the average execution time is 1 second and a processing time of 10 seconds is desirable, a concurrency limit of 10 would be sufficient.
Data Storage and Retrieval Optimization

Efficient data storage and retrieval are critical components of serverless data analytics, directly impacting query performance, cost, and scalability. The selection of appropriate storage solutions and the implementation of optimized access patterns are crucial for realizing the benefits of serverless architectures, such as automatic scaling and pay-per-use pricing. This section explores strategies for optimizing data storage and retrieval within the context of serverless data analytics.
Choosing the Right Data Storage Solutions
Selecting the appropriate data storage solution is fundamental to serverless data analytics performance. The choice depends on several factors, including data volume, access patterns, query complexity, and cost considerations. Different storage solutions offer varying trade-offs in terms of performance, scalability, and cost-effectiveness.
- Object Storage: Object storage, such as Amazon S3, Google Cloud Storage, or Azure Blob Storage, is well-suited for storing large volumes of unstructured or semi-structured data, such as log files, images, and raw data dumps. It offers high durability, scalability, and cost-effectiveness for storing large datasets. It is particularly beneficial for data lakes and archival purposes.
- Databases: Databases provide structured data storage and are optimized for specific query patterns.
- Relational Databases (RDBMS): RDBMS, like Amazon RDS (with options for PostgreSQL, MySQL, etc.), Google Cloud SQL, or Azure Database for PostgreSQL, are suitable for structured data with complex relationships and ACID (Atomicity, Consistency, Isolation, Durability) properties. They excel in scenarios requiring strong data consistency and transactional integrity. Serverless offerings, such as Amazon Aurora Serverless, provide auto-scaling capabilities.
- NoSQL Databases: NoSQL databases, such as Amazon DynamoDB, Google Cloud Datastore (Firestore), or Azure Cosmos DB, offer flexible data models and are designed for scalability and high availability. They are well-suited for handling large volumes of semi-structured data and can accommodate evolving data schemas. Document databases, key-value stores, and graph databases are common NoSQL types.
- Data Warehouses: Data warehouses, like Amazon Redshift, Google BigQuery, or Azure Synapse Analytics, are optimized for analytical workloads, including complex queries and aggregations. They offer features like columnar storage, parallel processing, and optimized query engines to improve performance. They are suitable for business intelligence and reporting.
Techniques for Optimizing Data Access Patterns
Optimizing data access patterns is crucial for improving query performance in serverless data analytics. This involves designing efficient query strategies, leveraging data indexing, and minimizing data transfer costs.
- Query Optimization: Query optimization involves rewriting queries to improve their efficiency.
- Query Planning: Serverless data analytics platforms often use query optimizers to analyze and plan query execution. Understanding how these optimizers work is crucial.
- Predicate Pushdown: Applying filtering conditions (predicates) as early as possible in the query execution plan can significantly reduce the amount of data processed. This minimizes data transfer and processing costs.
- Avoid SELECT
– : Specify only the required columns in your SELECT statements. This reduces the amount of data that needs to be read and processed.
- Data Indexing: Indexing creates data structures that speed up data retrieval by allowing the database to quickly locate specific data rows.
- Choosing the Right Indexes: The choice of indexes depends on the query patterns. B-tree indexes are suitable for range queries and equality searches, while hash indexes are optimized for equality searches.
- Index Maintenance: Regularly review and maintain indexes to ensure they remain effective. Over-indexing can slow down write operations.
- Data Locality and Partitioning: Organizing data to optimize data access patterns is vital.
- Colocation: Store related data together to minimize data transfer between storage and compute resources.
- Partitioning: Partitioning divides data into smaller, more manageable chunks, often based on time, location, or other relevant attributes. This allows for parallel processing and reduces the amount of data that needs to be scanned.
Implementing Data Partitioning and Sharding Strategies
Data partitioning and sharding are advanced techniques for scaling data storage and improving query performance. These strategies divide data across multiple storage units, enabling parallel processing and improving overall system throughput.
- Partitioning Strategies: Partitioning involves dividing data into smaller, logical units.
- Range Partitioning: Data is partitioned based on a range of values, such as dates or numerical identifiers. This is suitable for time-series data, where data is frequently queried based on time intervals.
- List Partitioning: Data is partitioned based on a predefined list of values. This is useful for partitioning data based on categorical attributes, such as geographic regions or product categories.
- Hash Partitioning: Data is partitioned using a hash function applied to a partitioning key. This distributes data evenly across partitions, improving load balancing.
- Sharding Strategies: Sharding involves distributing data across multiple physical storage units, or shards.
- Key-Based Sharding: Data is sharded based on a hash function applied to a primary key. This distributes data evenly across shards. The choice of hash function is critical for even data distribution.
- Directory-Based Sharding: A directory service maps data to specific shards. This provides flexibility but introduces an additional lookup step.
- Implementation Process: Implementing data partitioning and sharding involves several steps.
- Data Analysis: Analyze data access patterns and identify suitable partitioning keys.
- Partitioning Scheme Design: Design the partitioning or sharding scheme based on data characteristics and query patterns.
- Data Migration: Migrate existing data to the new partitioning or sharding scheme. This may involve data transformation and redistribution.
- Query Routing: Implement query routing mechanisms to direct queries to the appropriate partitions or shards.
- Monitoring and Optimization: Monitor query performance and data distribution to identify areas for optimization. Adjust the partitioning or sharding scheme as needed.
Event-Driven Architectures for Serverless Data Pipelines
Event-driven architectures are fundamental to building scalable and responsive serverless data pipelines. These architectures leverage event triggers to initiate data processing workflows, enabling near real-time data ingestion and transformation. This approach allows for decoupling of components, improved fault tolerance, and efficient resource utilization.
Role of Event Triggers in Serverless Data Pipelines
Event triggers act as the catalysts in serverless data pipelines, initiating functions in response to specific events. These events can originate from various sources, including object creation in cloud storage, messages arriving in message queues, or scheduled events based on a predefined schedule.The key aspects of event triggers are:
- Object Creation: When a new object (e.g., an image, a CSV file) is uploaded to cloud storage, a trigger can initiate a function to process the object. For example, an image upload can trigger a function to resize and optimize the image.
- Message Queues: Message queues, such as Amazon SQS or Azure Queue Storage, act as intermediaries, decoupling producers and consumers of data. When a message arrives in a queue, a trigger activates a function to process the message. This is useful for handling asynchronous tasks, like processing user requests.
- Scheduled Events: Timed events, often defined using a scheduler like AWS CloudWatch Events or Azure Logic Apps, can trigger functions at predefined intervals. These events are useful for tasks like data aggregation, report generation, or periodic data validation.
Comparison of Event-Driven Architectures for Data Ingestion and Processing
Several event-driven architectures can be employed for data ingestion and processing, each with its strengths and weaknesses. The choice of architecture depends on the specific requirements of the data pipeline, including data volume, latency requirements, and processing complexity.
- Simple Event-Driven Pipeline: This is the most basic architecture, where a single event trigger directly invokes a function. For example, when a file is uploaded to cloud storage, a function is triggered to process the file. This is suitable for simple tasks.
- Fan-Out Architecture: In this architecture, a single event triggers multiple functions, allowing for parallel processing of data. For example, a new order event could trigger functions to update the inventory, send a confirmation email, and update the sales report simultaneously.
- Complex Event Processing (CEP) Architecture: This architecture involves a stream processing engine that analyzes a continuous stream of events and identifies complex patterns. For example, it can be used to detect fraud by analyzing financial transactions in real time.
- Event-Driven with Orchestration: In this architecture, an orchestration service (e.g., AWS Step Functions, Azure Durable Functions) manages the execution of multiple functions triggered by events. This allows for creating complex workflows with error handling, retries, and conditional logic.
Example of a Serverless Data Pipeline Using Event Triggers and Functions
Consider a serverless data pipeline designed to process clickstream data from a website. This pipeline will ingest raw clickstream data, transform it, and store the processed data for analysis.The pipeline components are:
- Event Trigger: An object creation trigger on an Amazon S3 bucket. When a new log file is uploaded to the bucket, the trigger is activated.
- Function 1 (Ingestion): A Lambda function triggered by the S3 object creation event. This function reads the raw clickstream data from the log file.
- Function 2 (Transformation): Another Lambda function, triggered by Function 1. This function parses the raw data, extracts relevant information (e.g., user ID, timestamp, page visited), and transforms it into a structured format (e.g., JSON).
- Function 3 (Storage): A Lambda function, triggered by Function 2. This function stores the transformed data in a data store such as Amazon DynamoDB or Amazon Redshift.
Pipeline Operation:
- A web server generates clickstream logs and uploads them to an Amazon S3 bucket.
- The S3 object creation event triggers Function 1.
- Function 1 reads the log file from S3.
- Function 1 invokes Function 2, passing the raw data.
- Function 2 transforms the raw data into a structured format.
- Function 2 invokes Function 3, passing the transformed data.
- Function 3 stores the data in a database.
This architecture allows for near real-time data processing and scalability. The use of serverless functions enables automatic scaling based on the volume of incoming data. Furthermore, the decoupling of components makes the pipeline easier to maintain and update. For instance, if the data transformation logic needs to be updated, only Function 2 needs to be modified without impacting other parts of the pipeline.
Scaling Serverless Workloads
Scaling serverless workloads is a critical aspect of serverless data analytics, enabling systems to handle fluctuating data volumes and computational demands efficiently. Effective scaling ensures optimal performance, cost-effectiveness, and responsiveness. This section delves into strategies for automatic scaling, procedures for configuration, and techniques for managing data pipelines handling large datasets.
Strategies for Automatically Scaling Serverless Functions Based on Demand
Serverless functions are inherently designed for automatic scaling, but understanding the underlying mechanisms is crucial for effective implementation. Several strategies can be employed to ensure that functions scale appropriately to meet the demands of incoming data or user requests.
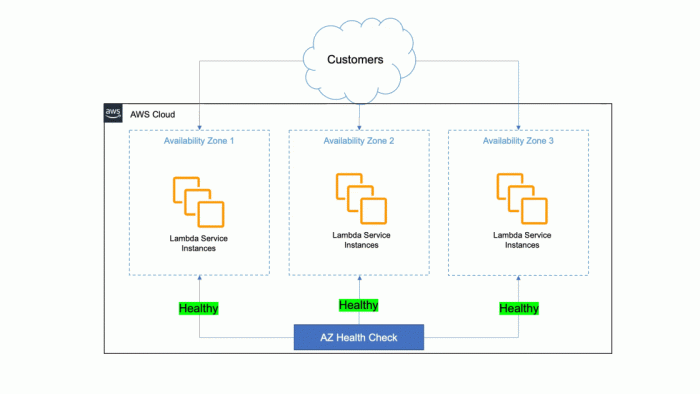
- Concurrency Control: Serverless platforms typically manage the number of concurrent function instances. This concurrency limit can be adjusted based on observed performance metrics such as latency and error rates. For instance, if a function’s average execution time increases beyond an acceptable threshold, the platform can automatically increase the number of concurrent instances to handle the increased load. The precise mechanism varies by platform, but the principle remains consistent: monitor, assess, and scale.
- Trigger-Based Scaling: Serverless functions are often triggered by events such as HTTP requests, messages in a queue, or changes in a database. The scaling behavior is directly linked to the rate of these events. For example, an increase in the number of incoming HTTP requests to an API Gateway triggers the automatic scaling of the associated serverless function. Similarly, a sudden surge in messages within a message queue like Amazon SQS or Azure Service Bus will automatically scale the consumers (serverless functions) processing those messages.
- Metric-Driven Scaling: Monitoring key performance indicators (KPIs) is essential for proactive scaling. Platforms offer metrics such as function invocation count, execution duration, memory usage, and error rates. These metrics can be used to configure autoscaling policies. For instance, if the average execution time of a function consistently exceeds a predefined threshold, the platform can automatically increase the number of concurrent instances.
A high error rate might trigger a scale-out to handle potential retry attempts, while low memory usage could suggest opportunities for optimization.
- Predictive Scaling: Some platforms support predictive scaling, which uses historical data and machine learning models to anticipate future demand. This approach allows the platform to proactively provision resources before the actual load increase, reducing latency and ensuring consistent performance. For example, if a data analytics function typically experiences a peak load every day at a specific time, the system can scale up the function instances in anticipation of that peak.
Procedure for Configuring Autoscaling for Data Processing Functions
Configuring autoscaling for data processing functions involves several key steps, ensuring the function can adapt to varying workloads. The specific steps may vary depending on the serverless platform, but the core principles remain consistent.
- Define Metrics: Identify the critical metrics that reflect the function’s performance and resource utilization. Common metrics include invocation count, execution duration, memory usage, and error rates. Selecting the appropriate metrics is crucial for effective autoscaling.
- Set Thresholds: Define thresholds for each metric. These thresholds trigger scaling actions. For example, you might set a threshold for the average execution time, such that if the function’s execution time consistently exceeds a certain value, the platform will scale out the function.
- Configure Scaling Policies: Configure the scaling policies based on the defined metrics and thresholds. This includes specifying the minimum and maximum number of function instances, the scaling increment (how many instances to add or remove at a time), and the cooldown period (the time the system waits before making further scaling decisions).
- Monitor and Refine: Continuously monitor the function’s performance and resource utilization. Review the scaling metrics and adjust the thresholds and policies as needed. The initial configuration may require fine-tuning to optimize performance and cost-effectiveness. For example, if the function is frequently scaling up and down rapidly, the thresholds might need adjustment to reduce the frequency of scaling events.
- Testing and Validation: Test the autoscaling configuration under different load conditions. Simulate various scenarios, such as a sudden surge in data volume or a sustained increase in request rate, to validate the autoscaling behavior. This ensures the function scales appropriately under different conditions.
Techniques for Managing and Scaling Data Pipelines Handling Large Datasets
Managing and scaling data pipelines that handle large datasets requires specialized techniques. These techniques focus on optimizing data ingestion, processing, and storage to ensure efficient performance and cost-effectiveness.
- Data Partitioning: Partitioning the data into smaller, manageable chunks is essential for parallel processing. This can be done based on time (e.g., daily or hourly partitions), geographic location, or other relevant criteria. Partitioning enables the pipeline to process data in parallel, significantly improving throughput. For example, a data pipeline processing clickstream data might partition the data by date, allowing each partition to be processed independently.
- Data Compression: Compressing the data before storage and during processing can reduce storage costs and improve data transfer speeds. Common compression algorithms include GZIP, Snappy, and Zstandard. Compression can also reduce the amount of data that needs to be processed, leading to faster execution times.
- Parallel Processing: Leverage the inherent parallelism of serverless functions to process data concurrently. This involves designing the data pipeline to distribute the workload across multiple function instances. For example, when processing data from a large file, the file can be split into smaller chunks, and each chunk can be processed by a separate function instance.
- Efficient Data Storage: Choose data storage solutions that are optimized for large datasets. Object storage services like Amazon S3, Azure Blob Storage, and Google Cloud Storage are well-suited for storing large volumes of data. Using the appropriate storage class (e.g., standard, infrequent access, archive) can further optimize costs.
- Stream Processing: For real-time or near-real-time data processing, use stream processing technologies like Apache Kafka, Amazon Kinesis, or Azure Event Hubs. These technologies enable the continuous ingestion and processing of data streams, allowing for immediate insights and actions.
- Resource Optimization: Optimize the function’s code and configuration for resource efficiency. This includes minimizing memory usage, optimizing CPU utilization, and reducing the execution duration. Code profiling and performance testing can help identify bottlenecks and areas for improvement. For instance, optimizing the data transformation logic within a function can significantly reduce its execution time and memory consumption.
- Idempotent Operations: Design the data pipeline to handle potential failures gracefully. Ensure that operations are idempotent, meaning that they can be safely executed multiple times without causing unintended side effects. This is particularly important in serverless environments, where functions can be retried automatically in case of failures.
Cost Optimization Techniques

Serverless data analytics, while offering significant advantages in scalability and agility, necessitates careful attention to cost management. The “pay-per-use” model inherent in serverless architectures requires a proactive approach to avoid unexpected expenses. This section Artikels strategies for estimating, controlling, and optimizing the costs associated with serverless data analytics projects.
Estimating and Controlling Costs
Accurate cost estimation is crucial for budgeting and resource allocation in serverless environments. Without proper forecasting, project costs can quickly escalate. Effective cost control involves a combination of upfront planning, continuous monitoring, and proactive adjustments.To effectively estimate and control costs, consider the following factors:
- Workload Characteristics: Analyze the data volume, processing complexity, and frequency of data ingestion and analysis. High data volumes, complex transformations, and frequent job executions directly impact resource consumption and cost.
- Service Pricing Models: Understand the pricing models of each serverless service used (e.g., AWS Lambda, Amazon S3, Azure Functions, Google Cloud Functions, Google Cloud Storage, etc.). Pricing can vary based on factors like compute time, memory allocation, data transfer, and storage capacity.
- Resource Consumption Metrics: Monitor key metrics such as function execution time, memory usage, data transfer rates, and storage capacity utilization. These metrics provide insights into resource consumption patterns and potential cost optimization opportunities.
- Cost Calculation Tools: Utilize cost calculators and estimation tools provided by cloud providers. These tools allow you to model different scenarios and estimate costs based on various input parameters.
- Budgeting and Alerts: Set up budgets and alerts to monitor spending and receive notifications when costs exceed predefined thresholds. This proactive approach helps prevent unexpected cost overruns.
Implementing Cost-Saving Measures
Several cost-saving measures can be implemented to reduce expenses in serverless data analytics projects. The choice of specific measures depends on the specific workload and the services used.Examples of cost-saving measures include:
- Right-sizing Compute Resources: Carefully select the appropriate memory allocation for serverless functions. Over-provisioning memory leads to unnecessary costs. Monitoring function execution times and memory usage can help determine the optimal memory configuration.
- Optimizing Function Code: Efficient code execution minimizes function execution time, thereby reducing compute costs. Code optimization techniques include using efficient algorithms, minimizing dependencies, and optimizing data access patterns.
- Data Storage Optimization: Choose the appropriate storage class for data based on access frequency and durability requirements. For example, infrequently accessed data can be stored in cheaper storage classes like Amazon S3 Glacier.
- Spot Instances: Leverage spot instances (or similar offerings from other cloud providers) for fault-tolerant, non-critical workloads. Spot instances offer significant cost savings compared to on-demand instances, but they can be terminated if the spot price exceeds the bid price. This is most applicable to batch processing and data transformation tasks where interruptions can be handled.
- Data Compression: Compress data before storing it and transmitting it. Compression reduces storage costs and data transfer costs. Common compression algorithms include GZIP and Snappy.
- Caching: Implement caching mechanisms to reduce the need to repeatedly process or retrieve data. Caching can significantly reduce compute and data retrieval costs.
Spot instances, for example, offer substantial discounts compared to on-demand instances. Consider the following scenario: A data analytics pipeline processes log files using AWS Lambda functions. If the pipeline can tolerate occasional interruptions, the Lambda functions can be triggered by events that process data from spot instances for data transformation tasks. The potential cost savings can be significant, often up to 70-90% compared to on-demand pricing.
However, it’s crucial to design the pipeline to be resilient to potential spot instance terminations.
Best Practices for Monitoring and Optimizing Costs
Continuous monitoring and optimization are essential for maintaining cost efficiency in serverless data analytics environments. Implementing a set of best practices ensures that costs remain under control and that resources are used effectively.These best practices include:
- Regular Cost Analysis: Conduct regular cost analysis to identify cost drivers and areas for optimization. This involves reviewing cost reports, analyzing resource utilization, and identifying any unexpected cost spikes.
- Implement Cost-Aware Design: Design serverless applications with cost efficiency in mind. Consider the cost implications of each design decision, such as function memory allocation, data storage choices, and data transfer patterns.
- Automated Monitoring and Alerting: Set up automated monitoring and alerting to track key metrics and receive notifications when costs exceed predefined thresholds or when resource utilization deviates from expected patterns.
- Resource Tagging: Tag resources with relevant metadata (e.g., project name, department, cost center). This allows for granular cost allocation and reporting.
- Version Control and Infrastructure as Code: Use version control and infrastructure-as-code (IaC) to manage infrastructure configurations. This facilitates cost-effective experimentation and rollback capabilities, minimizing the impact of misconfigurations.
- Performance Testing and Optimization: Conduct performance testing to identify bottlenecks and optimize function performance. Optimized functions consume fewer resources and reduce costs.
- Regular Code Reviews: Conduct regular code reviews to ensure that code is efficient and cost-effective. This can help identify opportunities for optimization and prevent costly mistakes.
Monitoring and Logging for Serverless Data Analytics
Effective monitoring and logging are indispensable for operating serverless data analytics pipelines. Serverless architectures, by their nature, abstract away much of the underlying infrastructure, making traditional monitoring approaches less effective. Comprehensive monitoring and logging practices are critical for understanding application behavior, identifying performance bottlenecks, diagnosing errors, and optimizing resource utilization, thereby enabling cost-effective and reliable data processing.
Importance of Monitoring and Logging in Serverless Environments
The ephemeral nature of serverless functions necessitates a shift in monitoring and logging strategies. Unlike traditional infrastructure where persistent servers provide continuous visibility, serverless functions execute briefly and may be scaled dynamically.
- Visibility into Function Execution: Monitoring provides insights into function invocations, durations, memory usage, and error rates. This allows for understanding the overall health and performance of the serverless data analytics pipeline. For example, monitoring can reveal if a function is consistently exceeding its allocated memory, indicating a need for optimization.
- Performance Bottleneck Identification: By analyzing metrics like execution time and cold start times, performance bottlenecks can be identified. Long execution times or frequent cold starts can significantly impact the overall performance of a data pipeline.
- Error Diagnosis and Debugging: Detailed logging is essential for diagnosing and debugging errors. Serverless functions often execute in isolated environments, making it difficult to reproduce issues. Comprehensive logging, including error messages, stack traces, and context information, facilitates rapid problem resolution.
- Resource Optimization: Monitoring resource usage, such as memory and CPU, allows for optimizing function configurations and scaling strategies. This helps in avoiding over-provisioning and ensures cost-effectiveness.
- Cost Management: Monitoring function invocations and resource consumption provides insights into the costs associated with the data analytics pipeline. This information enables cost optimization by identifying inefficient functions or unnecessary resource usage.
Setting Up Monitoring Dashboards
Creating effective monitoring dashboards involves collecting, aggregating, and visualizing key metrics from serverless functions. These dashboards provide a real-time view of the health and performance of the data analytics pipeline.
Setting up a monitoring dashboard typically involves the following steps:
- Choose a Monitoring Service: Several cloud providers offer native monitoring services, such as AWS CloudWatch, Google Cloud Monitoring (formerly Stackdriver), and Azure Monitor. Third-party solutions, like Datadog and New Relic, also provide comprehensive monitoring capabilities. The choice depends on the specific cloud provider and the desired features.
- Instrument Functions with Logging Statements: Add logging statements within the serverless functions to capture relevant information. This includes timestamps, function invocation IDs, input parameters, output results, and any relevant context. For example, in Python, using the `logging` module is a standard practice.
- Configure Metrics Collection: Configure the monitoring service to collect metrics from the serverless functions. This often involves configuring the cloud provider’s service to automatically collect metrics or using a custom solution to push metrics to the monitoring service. For instance, in AWS, CloudWatch automatically collects metrics like function invocations, errors, and duration.
- Create Custom Metrics: Define and create custom metrics that are specific to the application’s requirements. For instance, track the number of records processed per function invocation or the time taken to process a specific data transformation.
- Build Dashboards: Design and build dashboards to visualize the collected metrics. Dashboards should include graphs, charts, and tables that display key performance indicators (KPIs) such as function invocation counts, error rates, average execution times, and resource utilization.
- Establish Alerts: Configure alerts to be triggered based on predefined thresholds. For example, set an alert if the error rate exceeds a certain percentage or if the average execution time exceeds a specified duration.
Example: An AWS CloudWatch dashboard might include the following:
- Function Invocation Count: A line graph showing the number of function invocations over time.
- Error Rate: A line graph showing the percentage of failed function invocations.
- Average Execution Time: A line graph showing the average duration of function executions.
- Memory Utilization: A graph showing the memory usage of the function.
Creating a System for Logging and Alerting
A robust logging and alerting system is essential for proactive monitoring and incident response in serverless data analytics pipelines. This system should collect, store, analyze, and alert on critical events.
Building a system for logging and alerting typically involves the following components:
- Centralized Logging: Aggregate logs from all serverless functions into a centralized logging service. This enables easier searching, analysis, and correlation of events across the entire data pipeline. Common logging services include AWS CloudWatch Logs, Google Cloud Logging, and Azure Monitor Logs.
- Structured Logging: Use structured logging formats, such as JSON, to facilitate parsing and analysis of log data. Structured logs make it easier to extract specific fields and attributes from log entries. For example, include fields like `timestamp`, `function_name`, `request_id`, `level`, and `message`.
- Log Analysis and Filtering: Implement log analysis and filtering to identify critical events and patterns. This may involve using log analysis tools or custom scripts to search for specific error messages, performance bottlenecks, or unusual activity.
- Alerting Rules: Define alerting rules based on specific criteria, such as error rates, latency thresholds, or resource utilization levels. These rules trigger alerts when predefined conditions are met.
- Notification Channels: Configure notification channels to deliver alerts to the appropriate stakeholders. This may include email, SMS, Slack, or other communication platforms.
- Incident Response: Establish a clear incident response process to handle alerts. This should include procedures for investigating issues, escalating incidents, and implementing corrective actions.
Example: A practical application of this might be a data pipeline that processes financial transactions. If the system detects an unusually high error rate related to data validation functions, it could trigger an alert to the operations team. The alert could include a link to the relevant logs, which provide the stack traces, input data, and any related context to facilitate rapid problem diagnosis.
The team can then investigate, identify the root cause (e.g., a bug in the validation logic), and implement a fix, minimizing the impact on transaction processing.
Security Considerations in Serverless Data Analytics
Serverless data analytics, while offering significant benefits in terms of scalability and cost-effectiveness, introduces unique security challenges. The distributed nature of serverless architectures necessitates a proactive and comprehensive approach to security. Implementing robust security measures is crucial to protect sensitive data, maintain data integrity, and ensure the overall resilience of serverless data analytics pipelines. This section details best practices and methodologies for securing serverless functions, data storage, and the broader serverless environment.
Securing Serverless Functions and Data Storage
Securing serverless functions and the data they interact with is paramount in maintaining the integrity and confidentiality of a serverless data analytics system. This involves hardening the functions themselves, protecting the data at rest and in transit, and implementing strong access control mechanisms.
- Function Hardening: Serverless functions should be treated as potential attack vectors. Minimizing the attack surface involves several key practices.
- Least Privilege: Grant functions only the necessary permissions to access resources. This principle limits the potential damage from a compromised function. For example, if a function only needs to read from a specific data store, it should not have write access or broader permissions.
- Input Validation: Validate all inputs to prevent injection attacks (e.g., SQL injection, cross-site scripting). Use parameterized queries to prevent SQL injection. Implement strict input validation to ensure that data conforms to expected formats and ranges.
- Code Signing and Integrity Checks: Implement mechanisms to ensure the integrity of function code. This can involve code signing to verify the origin and authenticity of the code, along with checksums to detect unauthorized modifications.
- Regular Security Audits and Vulnerability Scanning: Regularly scan function code for vulnerabilities and perform security audits to identify potential weaknesses. Automate these processes as much as possible.
- Dependency Management: Carefully manage function dependencies. Regularly update dependencies to patch known vulnerabilities. Employ dependency scanning tools to identify and mitigate risks associated with third-party libraries.
- Data Encryption: Data encryption is essential to protect data at rest and in transit.
- Encryption at Rest: Encrypt data stored in data stores (e.g., object storage, databases) using encryption keys managed by the cloud provider or a dedicated key management service.
- Encryption in Transit: Enforce the use of HTTPS/TLS for all data transfers between functions and other services. This ensures that data is encrypted during transit.
- Key Management: Securely manage encryption keys. Use a key management service (KMS) to store, rotate, and manage encryption keys. Restrict access to KMS to authorized personnel only.
- Data Storage Security: Protect data stores themselves.
- Access Control Lists (ACLs) and Policies: Implement strict access control lists and policies to restrict access to data stores. Only authorized functions and users should have access.
- Data Retention Policies: Implement data retention policies to minimize the risk of data breaches. Regularly review and delete data that is no longer needed.
- Monitoring and Auditing: Implement monitoring and auditing to detect suspicious activity and potential data breaches. Log all access attempts and data modifications.
Implementing Access Control and Authentication Mechanisms
Robust access control and authentication are critical for preventing unauthorized access to serverless resources and data. Implementing these mechanisms ensures that only authorized users and functions can interact with the data analytics pipeline.
- Authentication: Verify the identity of users and services.
- Identity Providers: Integrate with identity providers (e.g., AWS IAM, Azure Active Directory, Google Cloud Identity) to authenticate users and services.
- Multi-Factor Authentication (MFA): Enforce MFA for all users with access to serverless resources. This adds an extra layer of security by requiring a second factor of authentication.
- Service Accounts and Roles: Use service accounts and roles to grant functions and services the necessary permissions. Avoid using long-lived access keys.
- Authorization: Control what authenticated users and services can access.
- Role-Based Access Control (RBAC): Implement RBAC to grant permissions based on user roles. Define roles with specific permissions and assign users to these roles.
- Resource-Based Policies: Use resource-based policies to control access to specific resources. This allows for fine-grained control over access to data and other resources.
- Principle of Least Privilege: Grant users and functions only the minimum permissions required to perform their tasks. This limits the potential damage from a security breach.
- API Gateway Security: Secure API endpoints.
- API Keys and Authentication: Use API keys and authentication mechanisms (e.g., OAuth, JWT) to authenticate API requests.
- Rate Limiting and Throttling: Implement rate limiting and throttling to protect against denial-of-service (DoS) attacks.
- Input Validation and Request Filtering: Validate and filter API requests to prevent malicious input.
Protecting Data in Transit and at Rest
Protecting data in transit and at rest is a cornerstone of serverless data analytics security. This involves encrypting data, implementing secure communication protocols, and using robust key management practices.
- Data in Transit: Secure data during its movement between components.
- HTTPS/TLS Encryption: Enforce HTTPS/TLS for all communication between functions, data stores, and other services. This ensures that data is encrypted during transit.
- Mutual TLS (mTLS): Implement mTLS for critical communications to verify the identity of both the client and the server.
- Virtual Private Cloud (VPC) and Private Endpoints: Utilize VPCs and private endpoints to isolate serverless resources and limit exposure to the public internet.
- Data at Rest: Secure data when it is stored.
- Encryption at Rest: Encrypt data stored in data stores using encryption keys managed by a KMS. This protects data from unauthorized access if the storage is compromised.
- Key Management Service (KMS): Use a KMS to securely manage encryption keys. Rotate keys regularly and restrict access to the KMS to authorized personnel.
- Data Masking and Anonymization: Implement data masking and anonymization techniques to protect sensitive data. This can involve replacing sensitive data with pseudonyms or removing it entirely.
- Compliance and Regulatory Requirements: Adhere to relevant compliance and regulatory requirements.
- Compliance Frameworks: Implement security controls that align with industry-specific compliance frameworks (e.g., HIPAA, GDPR, PCI DSS).
- Regular Audits and Assessments: Conduct regular security audits and assessments to ensure compliance and identify any security gaps.
- Documentation and Reporting: Maintain comprehensive documentation and reporting on security controls and compliance efforts.
Choosing the Right Serverless Data Analytics Services
Selecting the appropriate serverless data analytics service is critical for optimizing performance, controlling costs, and ensuring scalability. The choice depends on various factors, including the type of data, the complexity of the analysis, the expected workload, and the specific requirements of the application. A thorough understanding of the available services and their characteristics is essential for making informed decisions.
Comparing Serverless Data Analytics Services
Cloud providers offer a range of serverless data analytics services, each with distinct strengths and weaknesses. These services typically handle compute, storage, and data processing, allowing users to focus on their analytical tasks rather than infrastructure management. Understanding the nuances of each service is crucial for aligning the chosen service with the project’s needs.
- AWS: Amazon Web Services provides several serverless options, including Amazon Athena, Amazon EMR Serverless, and AWS Glue. Athena is well-suited for ad-hoc querying of data stored in S3, while EMR Serverless offers a managed Spark environment for more complex processing. AWS Glue provides data cataloging, ETL (Extract, Transform, Load) capabilities, and serverless data pipelines.
- Google Cloud: Google Cloud Platform (GCP) offers services like BigQuery, Cloud Functions, and Cloud Dataflow. BigQuery is a fully managed, petabyte-scale data warehouse for interactive analysis. Cloud Functions provides a serverless compute environment for event-driven processing, and Cloud Dataflow is a managed service for stream and batch data processing using Apache Beam.
- Microsoft Azure: Microsoft Azure’s serverless data analytics offerings include Azure Synapse Analytics (serverless SQL pool), Azure Functions, and Azure Data Factory. The serverless SQL pool in Azure Synapse Analytics allows for querying data in Azure Data Lake Storage Gen2 without needing to manage a dedicated SQL server. Azure Functions offers a serverless compute platform, and Azure Data Factory provides ETL and data integration capabilities.
Strengths and Weaknesses of Each Service
Each serverless data analytics service possesses inherent strengths and weaknesses that influence its suitability for specific use cases. These considerations encompass performance characteristics, cost implications, ease of use, and the range of supported functionalities. Careful evaluation of these factors is essential for selecting the optimal service.
- Amazon Athena:
- Strengths: Cost-effective for ad-hoc queries; integrates seamlessly with S3; serverless, eliminating infrastructure management; supports various data formats.
- Weaknesses: Performance can be slower for complex queries; limited support for data transformations; not ideal for real-time analytics.
- Amazon EMR Serverless:
- Strengths: Managed Spark environment; supports various open-source frameworks; good for large-scale data processing; pay-per-use pricing.
- Weaknesses: Can be more complex to configure than simpler services; not as cost-effective for small workloads; requires Spark knowledge.
- AWS Glue:
- Strengths: Provides ETL capabilities; data cataloging; integrates with other AWS services; serverless; supports both batch and streaming data.
- Weaknesses: ETL jobs can be resource-intensive; may require some configuration and tuning; can be less flexible than custom ETL solutions.
- Google BigQuery:
- Strengths: Petabyte-scale data warehouse; fast query performance; serverless; integrates well with other Google Cloud services; supports SQL.
- Weaknesses: Pricing can be expensive for large data volumes; data must be stored in BigQuery or linked from Cloud Storage; limited support for custom code.
- Google Cloud Functions:
- Strengths: Event-driven processing; integrates with other GCP services; serverless; scales automatically; pay-per-use pricing.
- Weaknesses: Limited execution time; suitable for short-running tasks; cold starts can affect performance.
- Google Cloud Dataflow:
- Strengths: Stream and batch data processing; supports Apache Beam; fully managed; scales automatically; integrates with other GCP services.
- Weaknesses: Can be complex to configure and manage; steeper learning curve; pricing can be higher than alternatives for small workloads.
- Azure Synapse Analytics (serverless SQL pool):
- Strengths: Query data in Azure Data Lake Storage Gen2; serverless; pay-per-query pricing; supports standard SQL; integrates with other Azure services.
- Weaknesses: Performance can be dependent on data layout and query complexity; may require some tuning for optimal performance.
- Azure Functions:
- Strengths: Event-driven processing; integrates with other Azure services; serverless; scales automatically; pay-per-use pricing.
- Weaknesses: Limited execution time; suitable for short-running tasks; cold starts can affect performance.
- Azure Data Factory:
- Strengths: ETL and data integration capabilities; serverless; supports a wide range of data sources and sinks; integrates with other Azure services.
- Weaknesses: Can be complex to configure; pricing can be higher than alternatives for simple workloads; may require some tuning for optimal performance.
Key Features and Pricing Models
A concise summary of key features and pricing models enables a quick comparison of serverless data analytics services. This table provides a snapshot of the essential characteristics, allowing for an informed initial assessment before deeper investigation.
| Service | Provider | Key Features | Pricing Model |
|---|---|---|---|
| Amazon Athena | AWS | Ad-hoc querying of data in S3, supports various data formats, serverless. | Pay-per-query (based on data scanned). |
| Amazon EMR Serverless | AWS | Managed Spark environment, supports various open-source frameworks, large-scale data processing. | Pay-per-use (based on vCPU and memory usage). |
| AWS Glue | AWS | ETL capabilities, data cataloging, supports both batch and streaming data. | Pay-per-use (based on Data Processing Units – DPUs). |
| Google BigQuery | Google Cloud | Petabyte-scale data warehouse, fast query performance, supports SQL. | Pay-per-query (based on data scanned) and storage. |
| Google Cloud Functions | Google Cloud | Event-driven processing, integrates with other GCP services, scales automatically. | Pay-per-use (based on execution time and resources). |
| Google Cloud Dataflow | Google Cloud | Stream and batch data processing, supports Apache Beam, fully managed. | Pay-per-use (based on vCPU and memory usage). |
| Azure Synapse Analytics (serverless SQL pool) | Microsoft Azure | Query data in Azure Data Lake Storage Gen2, supports standard SQL. | Pay-per-query (based on data processed). |
| Azure Functions | Microsoft Azure | Event-driven processing, integrates with other Azure services, scales automatically. | Pay-per-use (based on execution time and resources). |
| Azure Data Factory | Microsoft Azure | ETL and data integration capabilities, supports a wide range of data sources and sinks. | Pay-per-use (based on data pipeline execution). |
Implementing Resource Allocation Strategies
Implementing resource allocation strategies is crucial for achieving optimal performance, cost-effectiveness, and scalability in serverless data analytics. This section Artikels a systematic approach to implementing these strategies, focusing on a specific use case to illustrate the process, potential challenges, and mitigation techniques. The goal is to provide a practical guide for deploying and managing resource allocation in serverless environments.
Use Case: Real-time Fraud Detection
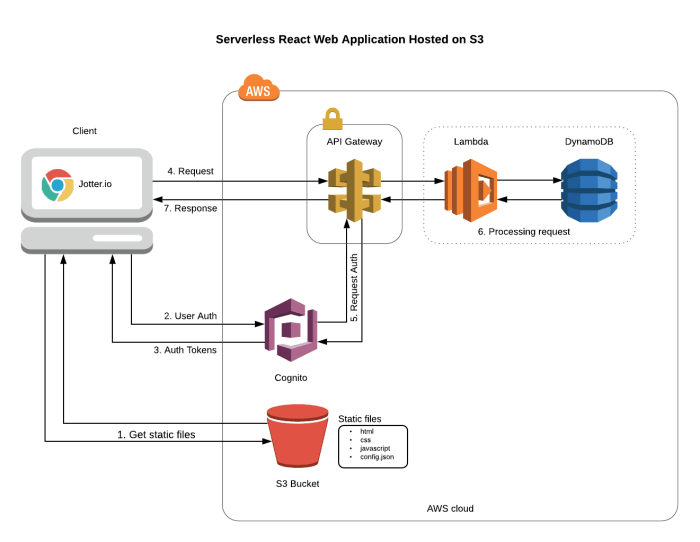
The selected use case is a real-time fraud detection system. This system analyzes incoming financial transactions to identify potentially fraudulent activities. The serverless architecture leverages several services, including an event source (e.g., a message queue like Amazon SQS or Azure Service Bus), a compute service (e.g., AWS Lambda or Azure Functions), and a data store (e.g., Amazon DynamoDB or Azure Cosmos DB).
Step-by-Step Procedure
Implementing resource allocation strategies involves a structured, iterative process. The following steps provide a detailed procedure for the fraud detection system:
- Define Performance Requirements: Establish clear performance metrics for the system. This includes:
- Latency: The maximum acceptable time to process a transaction and flag potential fraud (e.g., under 100 milliseconds).
- Throughput: The number of transactions the system must handle per second (e.g., 10,000 transactions per second during peak load).
- Error Rate: The acceptable percentage of transactions that fail to be processed (e.g., less than 0.1%).
- Design the Serverless Architecture: Design the architecture, mapping business logic to serverless components. This includes defining the event source, the compute functions, the data store, and any necessary integration services. The architecture should be designed to scale horizontally to meet the defined throughput requirements.
For example, the fraud detection system could use a message queue to receive transaction events, a Lambda function to process each event, and a DynamoDB table to store transaction data and fraud scores. - Resource Provisioning and Configuration: Configure the serverless functions and data stores with initial resource allocations.
- Compute Resources: Set the memory allocation and timeout for each Lambda function. Start with conservative values and monitor performance.
- Data Store Resources: Provision the data store with appropriate read/write capacity units (RCUs/WCUs) or request units (RUs).
- Concurrency Limits: Set the concurrency limits for Lambda functions to control the number of concurrent function invocations.
- Implement Monitoring and Logging: Implement comprehensive monitoring and logging. This is crucial for identifying performance bottlenecks and resource consumption patterns.
- Metrics Collection: Use services like AWS CloudWatch or Azure Monitor to collect metrics such as function invocation duration, error rates, and resource utilization.
- Logging: Implement detailed logging to capture events, errors, and performance data. Log messages should include timestamps, transaction IDs, and any relevant context.
- Alerting: Configure alerts based on key performance indicators (KPIs). For instance, set an alert if function invocation duration exceeds a threshold or if the error rate rises above a certain level.
- Performance Testing and Baseline: Conduct performance tests to establish a baseline and validate that the system meets the performance requirements.
- Load Testing: Simulate realistic transaction volumes to test the system’s throughput and latency under different load conditions.
- Stress Testing: Subject the system to extreme load conditions to identify potential bottlenecks and failure points.
- Establish Baseline: Collect performance metrics during the tests to establish a baseline. This baseline will be used for comparison and optimization in subsequent steps.
- Iterative Optimization: Based on the monitoring data and performance test results, iteratively optimize resource allocation.
- Compute Optimization:
- Memory Tuning: Adjust the memory allocation for Lambda functions based on the function’s memory consumption. Increasing memory can improve performance, but it also increases cost.
- Code Optimization: Optimize the function code to improve execution speed and reduce resource consumption.
- Concurrency Adjustments: Adjust concurrency limits based on the load test results and the system’s ability to handle peak loads.
- Data Store Optimization:
- Capacity Planning: Adjust the provisioned capacity units (RCUs/WCUs or RUs) for the data store based on the observed read/write patterns.
- Indexing: Optimize data store indexing to improve query performance.
- Caching: Implement caching mechanisms to reduce the load on the data store and improve response times.
- Compute Optimization:
- Cost Optimization: Continuously monitor and optimize costs.
- Right-sizing Resources: Ensure resources are not over-provisioned, and scale down resources when not needed.
- Reserved Instances/Capacity: Consider using reserved instances or reserved capacity for data stores if the workload is predictable.
- Cost Alerts: Set up cost alerts to be notified if spending exceeds a predefined threshold.
- Automated Scaling: Implement automated scaling to dynamically adjust resources based on demand.
- Auto Scaling for Compute: Configure auto-scaling policies for Lambda functions based on metrics like invocation duration, concurrency, and error rates.
- Auto Scaling for Data Stores: Enable auto-scaling for data stores to automatically adjust the provisioned capacity based on traffic patterns.
- Regular Review and Refinement: Regularly review the system’s performance, cost, and resource allocation strategies. Refine the strategies as needed to adapt to changing requirements and workloads. This should include revisiting the performance metrics, the architecture, and the optimization strategies.
Workflow Components and Interactions
The workflow for the fraud detection system involves several interconnected components:
- Event Source: The system receives financial transaction events from an event source (e.g., SQS). This component publishes messages to the queue.
- Lambda Function (Fraud Detection Engine): A Lambda function is triggered by the events in the queue. It receives the transaction data, performs fraud detection analysis, and determines a fraud score.
- Data Store (DynamoDB): The Lambda function stores transaction data and fraud scores in a DynamoDB table. This data is used for analysis and historical reporting.
- Monitoring and Logging Services (CloudWatch/Azure Monitor): These services collect metrics, logs, and traces from the Lambda function and the data store. This data is used for monitoring performance, identifying issues, and optimizing resource allocation.
- Alerting Service: This service monitors the metrics and logs generated by the monitoring service. If any performance or error thresholds are exceeded, the alerting service triggers notifications.
- Auto-Scaling Service: The auto-scaling service automatically adjusts the resources of the Lambda function and the data store based on demand and performance metrics.
The interaction between these components is as follows:
- The event source publishes transaction events to the queue.
- The Lambda function is triggered by events in the queue.
- The Lambda function retrieves transaction data, performs analysis, and stores the results in DynamoDB.
- Monitoring and logging services collect metrics and logs.
- The alerting service monitors the metrics and logs and triggers notifications when necessary.
- The auto-scaling service dynamically adjusts resources based on performance and demand.
Potential Challenges and Mitigation
Implementing resource allocation strategies in serverless environments can present several challenges.
- Cold Starts: Lambda functions can experience cold starts, which can increase latency.
- Mitigation: Use provisioned concurrency, keep-warm strategies, or optimize code to reduce cold start times.
- Resource Limits: Serverless platforms have resource limits (e.g., memory, execution time).
- Mitigation: Optimize code to reduce resource consumption, adjust memory allocation, and use appropriate timeout settings.
- Monitoring Complexity: Monitoring serverless applications can be complex due to the distributed nature of the architecture.
- Mitigation: Implement comprehensive monitoring, logging, and alerting strategies. Utilize distributed tracing tools to track requests across different components.
- Cost Management: Optimizing cost can be challenging due to the pay-per-use pricing model.
- Mitigation: Monitor resource consumption closely, right-size resources, use cost-optimization techniques, and set up cost alerts.
- Vendor Lock-in: Choosing a specific serverless platform can lead to vendor lock-in.
- Mitigation: Design the architecture with portability in mind. Use open standards and avoid vendor-specific features whenever possible.
- Dependency Management: Managing dependencies in serverless functions can be complex.
- Mitigation: Use a robust dependency management strategy, such as bundling dependencies with the function code or using layers.
Conclusive Thoughts
In summary, the effective management of resource allocation is paramount to the success of serverless data analytics initiatives. By understanding the underlying principles of serverless computing, implementing strategic resource optimization techniques, and prioritizing security and cost efficiency, organizations can unlock the full potential of this transformative technology. From right-sizing function memory to implementing sophisticated cost-saving measures, the discussed strategies provide a robust framework for building and maintaining high-performing, scalable, and economically viable data analytics solutions.
The continued evolution of serverless platforms and the increasing complexity of data workloads will demand ongoing vigilance and adaptation in resource allocation practices, ensuring that data-driven insights are delivered with optimal efficiency and cost-effectiveness.
FAQ Corner
What is the primary advantage of serverless data analytics over traditional infrastructure?
The primary advantage is the elimination of server management, leading to reduced operational overhead and the ability to scale resources automatically based on demand, resulting in significant cost savings and improved agility.
How does serverless computing handle scaling in data analytics?
Serverless platforms automatically scale resources (e.g., compute instances, memory) based on incoming data volume or request frequency, ensuring optimal performance without manual intervention.
What are some common cost optimization strategies in serverless data analytics?
Cost optimization strategies include right-sizing function memory, utilizing spot instances or reserved instances, optimizing data access patterns, and monitoring resource usage closely to identify and eliminate inefficiencies.
What security considerations are unique to serverless data analytics?
Unique security considerations involve securing function code, managing access control to data storage, and protecting data in transit and at rest. This requires implementing robust authentication, authorization, and encryption mechanisms.