Serverless computing, with its promise of scalability and cost-efficiency, has revolutionized application development. However, integrating databases into serverless architectures presents unique challenges. This exploration delves into the intricacies of managing database connections within serverless environments, examining the hurdles that developers face when striving for optimal performance, security, and cost-effectiveness. From the initial cold start to the complexities of network latency, this analysis provides a comprehensive overview of the critical considerations for successful database integration.
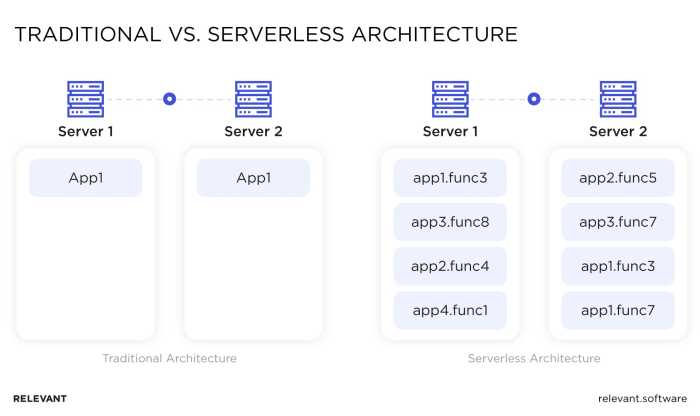
The serverless paradigm introduces a new set of constraints on traditional database interactions. Unlike monolithic applications with persistent connections, serverless functions are often short-lived and stateless. This necessitates a careful approach to connection management, including connection pooling, timeout configurations, and security protocols. This examination will address the implications of these constraints, providing insights into the design and implementation of robust and efficient database connections in serverless applications.
Cold Starts and Connection Initialization

Serverless architectures, while offering scalability and cost-effectiveness, introduce unique challenges related to database connection management. One of the most significant is the impact of cold starts on the initialization of database connections. Understanding and mitigating these effects is crucial for maintaining application performance and responsiveness in serverless environments.
Impact of Cold Starts on Database Connections
Cold starts significantly affect database connection initialization because they necessitate the creation of new connections each time a serverless function is invoked after a period of inactivity. This initialization process involves several steps, including establishing a network connection to the database server, authenticating with the database, and potentially initializing the database connection pool. These operations can be time-consuming, leading to increased latency for the initial request that triggers the cold start.
The delay can be substantial, especially for functions that require complex connection setups or are connecting to geographically distant database servers. The duration of a cold start varies depending on factors such as function size, runtime, database server location, and the complexity of the connection setup.
Strategies to Mitigate Cold Start Effects
Several strategies can be employed to mitigate the negative effects of cold starts on database connections. These strategies aim to either reduce the frequency of cold starts or optimize the connection initialization process.
- Function Warm-up: Regularly invoking the serverless function to keep it “warm” and prevent it from entering an idle state. This can be achieved through scheduled events or “ping” mechanisms that proactively trigger function executions.
- Connection Pooling: Implementing connection pooling is a key strategy to reduce connection overhead. Connection pooling involves maintaining a pool of pre-established database connections that can be quickly reused by subsequent function invocations, thereby bypassing the need to establish new connections from scratch.
- Database Connection Optimization: Optimizing the connection initialization code can also help. This includes minimizing the number of database calls during initialization, using connection parameters that promote faster connection establishment, and ensuring that the connection is configured for optimal performance.
- Provisioned Concurrency: Utilizing provisioned concurrency in some serverless platforms allows for the allocation of a specific number of pre-warmed function instances. This guarantees a minimum level of function availability and significantly reduces the likelihood of cold starts. However, it comes with associated costs, as resources are continuously provisioned even when the function is not actively handling requests.
Advantages and Disadvantages of Connection Pooling in Serverless Functions
Connection pooling is a widely adopted technique for managing database connections, offering several advantages in serverless environments, while also presenting some disadvantages.
- Advantages:
- Reduced Latency: Connection pooling dramatically reduces the latency associated with database connection establishment, especially during cold starts, as connections are pre-established and readily available.
- Improved Resource Utilization: By reusing existing connections, connection pooling minimizes the overhead of creating and tearing down connections, which can be resource-intensive.
- Enhanced Scalability: Connection pooling can help improve the scalability of serverless functions by allowing them to efficiently handle a larger number of concurrent requests.
- Disadvantages:
- Complexity: Implementing and managing connection pooling can add complexity to the application code. It requires careful configuration and tuning to ensure optimal performance and prevent issues like connection leaks.
- Potential for Connection Exhaustion: If the connection pool is not properly sized or managed, it can lead to connection exhaustion, where all connections in the pool are in use, and new requests are forced to wait, which can lead to performance degradation.
- Increased Memory Consumption: Maintaining a connection pool consumes memory resources, which can be a concern in serverless environments with limited resources.
- Requires Careful Configuration: Misconfigured connection pools can lead to performance bottlenecks and connection issues. For example, setting the pool size too small can lead to connection starvation, while setting it too large can consume excessive resources.
Connection Management and Scalability
Managing database connections effectively is paramount for serverless applications, especially as traffic scales. Serverless functions, by their ephemeral nature and rapid instantiation, present unique challenges to maintaining persistent database connections. Without proper management, connection limits imposed by databases can quickly be exhausted, leading to performance bottlenecks, request failures, and ultimately, a degraded user experience. The inherent scalability of serverless necessitates a scalable connection strategy to match the dynamic demands of the application.
Challenges of Managing Database Connections at Scale
The scalability of serverless applications introduces several challenges in database connection management. Serverless functions, triggered by events, can spawn numerous concurrent instances, each potentially requiring a database connection. This can rapidly deplete connection pools, leading to connection errors. Furthermore, the short-lived nature of these functions can make it difficult to efficiently reuse existing connections, as connections might be closed before they can be utilized again.
Methods for Efficiently Scaling Database Connections
To efficiently scale database connections, several strategies can be employed to mitigate the challenges presented by serverless architectures. These methods aim to optimize connection usage, minimize connection overhead, and ensure database resources are used effectively.
- Connection Pooling: Implementing connection pooling is crucial. Connection pools maintain a set of active connections, allowing serverless functions to quickly acquire and release connections without the overhead of establishing new connections for each request. Popular connection pooling libraries, such as HikariCP (Java), pg-promise (Node.js), and SQLAlchemy (Python), offer features like connection validation, idle connection eviction, and connection limit control. The choice of library should be based on the language used.
For example, in a Node.js environment, the `pg` library can be configured with a connection pool to manage database connections efficiently.
- Connection Reuse: Where possible, connections should be reused across function invocations. This can be achieved by caching connection objects within the function’s execution environment or by using persistent connections. Caching connections within the function’s scope reduces the frequency of connection establishment.
- Database Proxy: Utilizing a database proxy, such as AWS Database Proxy or a similar service, can significantly improve connection management. These proxies act as intermediaries between the serverless functions and the database, managing connection pooling, connection limits, and connection timeouts. They can also provide features like connection multiplexing, which allows multiple function instances to share a smaller number of database connections.
This reduces the load on the database and improves overall performance.
- Optimizing Database Queries: Optimizing database queries can indirectly improve connection scalability. Efficient queries reduce the time connections are held open, freeing up resources for other function instances. Using indexes, rewriting complex queries, and avoiding unnecessary data retrieval can significantly improve performance and connection utilization.
- Connection Limits and Monitoring: Carefully configure database connection limits to prevent resource exhaustion. Implement monitoring to track connection usage and identify potential bottlenecks. Monitoring tools can alert when connection usage approaches the database’s capacity, allowing proactive adjustments to be made, such as scaling the database or adjusting connection pool settings. Tools like Prometheus and Grafana can be used for this purpose.
Solution for Addressing Connection Limits in Serverless Functions
To address connection limits imposed by databases in serverless functions, a comprehensive solution should incorporate multiple strategies. This solution aims to minimize the number of active connections, efficiently reuse existing connections, and prevent connection exhaustion.
- Implement a Connection Pool: Integrate a connection pooling library within each serverless function. Configure the pool with appropriate connection limits, idle timeout settings, and connection validation mechanisms. For instance, in a Python function using `psycopg2`, a connection pool can be initialized at the global scope, ensuring that connections are reused across function invocations within the same execution environment.
- Use a Database Proxy: Deploy a database proxy service, such as AWS Database Proxy, in front of the database. Configure the proxy to manage connection pooling, connection limits, and connection timeouts. This offloads connection management from the serverless functions and provides a centralized point for monitoring and control.
- Implement Connection Health Checks: Include regular health checks within the serverless functions to validate the database connection’s status. This can involve executing a simple query to verify the connection’s availability. If a connection is found to be unhealthy, it should be closed and re-established.
- Optimize Query Execution Time: Optimize the SQL queries used by the serverless functions to reduce the time each connection is held open. This involves using indexes, rewriting complex queries, and avoiding unnecessary data retrieval.
- Monitor Connection Usage: Implement robust monitoring to track connection usage, including the number of active connections, connection pool utilization, and connection errors. Use monitoring tools, such as CloudWatch, Prometheus, and Grafana, to visualize connection metrics and set up alerts to notify when connection usage approaches the database’s limits.
- Implement Connection Timeout: Set connection timeouts to automatically close idle connections after a specified period. This helps to prevent connections from remaining open indefinitely and consuming database resources. Configure the timeout values in both the connection pool and the database proxy (if used).
- Implement Exponential Backoff and Retry: Incorporate exponential backoff and retry mechanisms in the serverless functions to handle transient connection errors. If a connection attempt fails, the function should wait for a progressively increasing amount of time before retrying. This can prevent cascading failures and provide resilience against temporary database issues.
Timeout Issues and Connection Lifespan
Serverless functions, designed for short-lived execution, face unique challenges regarding database connection timeouts and their management. These timeouts, if not correctly handled, can lead to application failures and performance degradation. Understanding the causes, implementing best practices, and properly managing connection lifecycles are crucial for building resilient serverless applications that interact with databases.
Common Causes of Connection Timeouts
Connection timeouts in serverless environments can arise from several factors related to the ephemeral nature of functions and the underlying database infrastructure. These causes typically involve insufficient resource allocation, network latency, or improper connection management within the function code.
- Function Execution Time Exceeds Timeout Threshold: Serverless functions have a maximum execution time limit set by the cloud provider. If a database query or operation takes longer than this limit, the function will be terminated, and a timeout error will occur. This is often exacerbated by complex queries, large datasets, or inefficient database indexing.
- Network Latency and Database Availability: Network delays between the serverless function and the database, or database unavailability, can lead to timeouts. Factors such as geographical distance between the function and the database, network congestion, and database server load contribute to latency. Database server issues, like high CPU usage or insufficient memory, can also lead to connection failures.
- Connection Pool Exhaustion: Serverless functions often utilize connection pools to optimize database interactions. If the pool is exhausted (e.g., due to many concurrent function invocations or long-lived connections), new connection requests will wait, potentially exceeding the timeout threshold.
- Incorrectly Configured Timeout Settings: Improperly configured timeout settings in the database client library or within the database server itself can cause timeouts. For instance, if the client-side connection timeout is set too low, connections might be terminated prematurely. Similarly, if the database server has a low idle connection timeout, connections may be closed before they can be reused.
- Resource Constraints: Serverless functions may experience timeouts if they run out of allocated resources, such as memory or CPU. This can happen if the function is processing a large amount of data or running complex computations, leading to slow query execution times and connection timeouts.
Best Practices for Setting Appropriate Connection Timeouts
Establishing appropriate connection timeouts is critical for serverless functions to avoid failures and maintain performance. The ideal timeout values depend on various factors, including the database type, the complexity of the queries, and the network conditions.
- Understand Database Characteristics: Different databases have varying default connection timeout settings. Review the documentation for your specific database (e.g., PostgreSQL, MySQL, MongoDB) to understand its default behavior and any recommended settings for serverless environments.
- Set Client-Side Timeouts: Configure the connection timeout in your database client library (e.g., `psycopg2` for Python, `mysql2` for Node.js). This timeout specifies the maximum time the client will wait for a connection to be established. It should be set to a value that is long enough to accommodate typical connection establishment times but short enough to prevent indefinite blocking in case of issues.
- Monitor Query Execution Times: Regularly monitor the execution times of your database queries. Use tools like database performance dashboards or query analyzers to identify slow queries that might be contributing to timeouts. Optimize these queries through indexing, query rewriting, or other performance enhancements.
- Implement Circuit Breakers: Consider implementing a circuit breaker pattern to automatically stop sending requests to a database if it’s consistently failing. This can prevent cascading failures and allow the system to recover gracefully.
- Configure Database Server Timeouts: Review and adjust the timeout settings on the database server. This includes idle connection timeouts, which determine how long an inactive connection is kept open before being closed.
- Test and Tune: Conduct thorough testing under various load conditions to evaluate your timeout settings. Simulate high traffic and database stress to identify potential bottlenecks and adjust the timeouts accordingly. A/B testing can be employed to evaluate the impact of different timeout configurations on performance.
Handling Database Connection Lifespan in Serverless Functions
Managing the lifespan of database connections in serverless functions requires careful consideration to balance performance, resource usage, and resilience. Here’s an example demonstrating how to handle database connection lifespans, including connection closures, within a serverless function written in Python.
- Connection Initialization (Outside the Handler): Establish the database connection outside the main handler function. This reduces the overhead of repeatedly creating connections for each function invocation. This practice also makes use of connection pooling.
- Connection Reuse (Within the Handler): Reuse the established connection for multiple database operations within a single function invocation. Avoid opening and closing the connection for each query.
- Connection Closure (Explicit or Implicit): Ensure that the connection is properly closed when the function completes, either explicitly (e.g., using `conn.close()`) or implicitly through context management (e.g., using a `with` statement).
- Example Code (Python):
import psycopg2 import os # Database connection parameters (retrieved from environment variables) DB_HOST = os.environ.get("DB_HOST") DB_NAME = os.environ.get("DB_NAME") DB_USER = os.environ.get("DB_USER") DB_PASSWORD = os.environ.get("DB_PASSWORD") # Establish the database connection outside the handler try: conn = psycopg2.connect( host=DB_HOST, database=DB_NAME, user=DB_USER, password=DB_PASSWORD ) print("Database connection established successfully.") except psycopg2.Error as e: print(f"Error connecting to the database: e") conn = None # Set to None to indicate connection failure def lambda_handler(event, context): if conn is None: return 'statusCode': 500, 'body': 'Database connection failed.' try: with conn.cursor() as cur: # Perform database operations using the cursor cur.execute("SELECT version();") db_version = cur.fetchone() print(f"Database version: db_version") conn.commit() # Commit the transaction return 'statusCode': 200, 'body': f"Database version: db_version" except psycopg2.Error as e: conn.rollback() # Rollback the transaction on error print(f"Error during database operation: e") return 'statusCode': 500, 'body': f"Database operation failed: e" # Connection is automatically closed when the function exits or the 'with' statement finishes.
Database Selection and Compatibility
Choosing the right database is critical for the success of serverless applications. The inherent characteristics of serverless architectures, such as ephemeral compute instances and auto-scaling, necessitate careful consideration of database compatibility and performance characteristics. The selection process must align with the application’s data model, read/write patterns, and scalability requirements to avoid bottlenecks and maximize efficiency.
Compatibility of Database Types
The compatibility of different database types with serverless architectures varies significantly, primarily due to their architectural designs and connection models. The optimal choice depends heavily on the specific application’s needs and the trade-offs involved.
SQL databases, such as PostgreSQL, MySQL, and Microsoft SQL Server, are traditionally designed for long-lived connections and often require connection pooling to manage resources efficiently. While serverless functions can connect to these databases, the connection management overhead can be significant. The short-lived nature of serverless functions means connections are frequently opened and closed, potentially leading to connection exhaustion and performance degradation.
However, some managed SQL database services, like Amazon Aurora Serverless, are specifically designed to address these challenges by automatically scaling compute resources and managing connections.
NoSQL databases, including document stores (e.g., MongoDB), key-value stores (e.g., Redis, DynamoDB), and wide-column stores (e.g., Cassandra), often offer better compatibility with serverless. Their flexible schemas and typically more lightweight connection models can be advantageous. NoSQL databases are often designed with horizontal scalability in mind, aligning well with the auto-scaling capabilities of serverless platforms. Many NoSQL services provide fully managed solutions that abstract away the complexities of database management, making them easier to integrate into serverless applications.
Databases Suited for Serverless Applications
Several database options are particularly well-suited for serverless environments, offering a balance of performance, scalability, and ease of integration. These databases often provide managed services that handle much of the operational overhead, allowing developers to focus on application logic.
- Amazon DynamoDB: This fully managed NoSQL database service from AWS is a popular choice for serverless applications. It offers high performance, automatic scaling, and pay-per-request pricing. DynamoDB is particularly well-suited for applications with unpredictable workloads and high read/write rates. Its integration with AWS Lambda is seamless, and it supports features like global tables for multi-region deployments.
- Amazon Aurora Serverless: Aurora Serverless is an on-demand, auto-scaling version of the Amazon Aurora relational database. It supports MySQL and PostgreSQL compatibility. Aurora Serverless automatically starts up, shuts down, and scales capacity based on application demand. This makes it a good fit for applications with intermittent or unpredictable workloads, such as development, testing, or infrequent web applications.
- Google Cloud Firestore: Firestore is a NoSQL document database from Google Cloud Platform. It offers real-time data synchronization, offline support, and automatic scaling. Firestore is well-suited for mobile and web applications requiring flexible data models and global reach.
- Azure Cosmos DB: Azure Cosmos DB is a globally distributed, multi-model database service from Microsoft Azure. It supports various data models, including document, graph, key-value, and column-family. Cosmos DB provides high availability, low latency, and automatic scaling. It’s a good choice for applications requiring global distribution and flexible data models.
- FaunaDB: FaunaDB is a globally distributed, serverless database built for modern applications. It provides ACID transactions, flexible data modeling, and automatic scaling. FaunaDB is particularly well-suited for applications with complex data relationships and high concurrency requirements.
Optimizing Database Queries
Optimizing database queries is crucial for maximizing performance within a serverless environment. Serverless functions often have short execution times, and any inefficiency in database interactions can significantly impact overall application latency and cost. Several strategies can be employed to optimize queries and improve database performance.
- Indexing: Proper indexing of database tables is fundamental to query optimization. Indexes speed up data retrieval by allowing the database to quickly locate relevant data without scanning the entire table. Identifying frequently queried fields and creating appropriate indexes can significantly reduce query execution times.
- Query Optimization: Analyzing and optimizing SQL queries is essential. Avoid using `SELECT
-` statements, as they retrieve unnecessary data. Instead, specify only the required columns. Use `WHERE` clauses to filter data efficiently. Review query execution plans to identify performance bottlenecks and optimize query structure. - Connection Pooling (for SQL databases): Although serverless functions have short lifespans, connection pooling can mitigate the overhead of repeatedly opening and closing connections to SQL databases. Using a connection pooler, such as Amazon RDS Proxy or a third-party library, allows serverless functions to reuse existing database connections, reducing latency.
- Data Modeling: The way data is structured within the database can greatly impact query performance. Carefully consider the data model, choosing appropriate data types and relationships. For NoSQL databases, design the data model to match the application’s query patterns, optimizing for the most common access patterns.
- Caching: Implementing caching can reduce the load on the database by storing frequently accessed data in a cache, such as Redis or Memcached. When a request for data is received, the application first checks the cache. If the data is found in the cache (a “cache hit”), it is served directly from the cache, avoiding a database query. If the data is not in the cache (a “cache miss”), the application retrieves it from the database, stores it in the cache, and then serves it to the client.
- Batch Operations: Whenever possible, perform database operations in batches. For example, instead of making multiple individual `INSERT` statements, combine them into a single batch insert. This reduces the number of round trips to the database and can significantly improve performance.
- Prepared Statements: Using prepared statements can improve performance and security. Prepared statements precompile the SQL query, which the database can then reuse with different parameters. This reduces the overhead of parsing and optimizing the query each time it is executed. Prepared statements also help prevent SQL injection vulnerabilities.
Security Considerations for Database Connections

Serverless architectures, while offering significant advantages in terms of scalability and cost-effectiveness, introduce unique security challenges when it comes to database connections. The ephemeral nature of serverless functions and the distributed nature of the infrastructure necessitate a careful approach to security, ensuring that database credentials, access, and data are protected from unauthorized access and potential vulnerabilities. Failing to address these considerations can expose sensitive data and lead to significant security breaches.
Security Risks Associated with Database Connections in Serverless Environments
The dynamic nature of serverless functions introduces several security risks. The potential for compromised credentials, the attack surface exposed by the distributed environment, and the need for robust access control mechanisms are key concerns.
- Credential Exposure: Hardcoding database credentials directly within serverless function code is a critical vulnerability. This exposes credentials to potential attackers who could gain access to the codebase. Furthermore, if the code is stored in a public repository, the risk is amplified.
- Lack of Network Isolation: Without proper configuration, serverless functions may have broad network access, increasing the attack surface. This means that if a function is compromised, an attacker could potentially access other resources within the same network, including the database.
- Insufficient Access Control: Improperly configured access control mechanisms can lead to unauthorized data access. For example, if a function has overly permissive permissions, it could potentially modify or delete data it shouldn’t have access to.
- Vulnerability to Injection Attacks: Serverless functions that do not properly sanitize user input are susceptible to SQL injection and other injection attacks. These attacks can be used to manipulate database queries and gain unauthorized access to data.
- Data Breach Risks: Data breaches can occur due to any of the above-mentioned vulnerabilities. Compromised credentials, insufficient access control, or successful injection attacks can all lead to the unauthorized disclosure, modification, or deletion of sensitive data stored in the database.
Procedures for Securing Database Credentials and Access in Serverless Functions
Securing database credentials and access in serverless functions requires a multi-layered approach. This includes using secure storage for credentials, implementing robust authentication and authorization mechanisms, and employing network security best practices.
- Use of Secrets Management Services: Instead of hardcoding credentials, use secrets management services such as AWS Secrets Manager, Azure Key Vault, or Google Cloud Secret Manager. These services allow you to securely store and retrieve credentials. This ensures that the credentials are not exposed in the function code and that they can be rotated easily without redeploying the function.
- Least Privilege Principle: Grant serverless functions only the minimum permissions required to perform their tasks. This reduces the impact of a potential security breach. For example, if a function only needs to read data from a table, it should not be granted permissions to modify or delete data.
- Network Security: Implement network security measures to restrict access to the database. This includes using virtual private clouds (VPCs) to isolate the function and database, and configuring security groups to control inbound and outbound traffic. Consider using private endpoints to avoid exposing the database to the public internet.
- Input Validation and Sanitization: Implement input validation and sanitization to prevent injection attacks. Validate all user input before using it in database queries. Use parameterized queries or prepared statements to prevent SQL injection.
- Regular Security Audits: Conduct regular security audits to identify and address vulnerabilities. This includes reviewing function code, access control policies, and network configurations. Employing automated security scanning tools can help identify potential issues early.
Security Best Practices for Database Connections in Serverless
Implementing security best practices is critical to mitigating risks. This involves securing all aspects of the connection, from authentication to monitoring. The following table summarizes the key security best practices:
| Area | Best Practice | Implementation Details | Example |
|---|---|---|---|
| Authentication | Use IAM roles or service accounts | Assign IAM roles to serverless functions that grant access to database resources. For service accounts, configure authentication through the database provider (e.g., PostgreSQL users). | An AWS Lambda function accessing an RDS database should assume an IAM role with permissions to connect to the database and execute specific SQL queries. |
| Authorization | Implement least privilege access control | Grant only the necessary permissions to functions and database users. Regularly review and update permissions. | A function that only reads data from a table should be granted the `SELECT` privilege and nothing more. Avoid using wildcard permissions. |
| Encryption | Encrypt data in transit and at rest | Use TLS/SSL to encrypt connections to the database. Enable encryption at rest for database storage (e.g., using KMS keys). | Configure database connections to use TLS 1.2 or higher. Enable encryption for the database volumes using the cloud provider’s encryption services. |
| Monitoring | Implement logging and monitoring | Log all database connection attempts, queries, and errors. Monitor for unusual activity, such as failed login attempts or excessive data access. | Use cloud provider’s logging and monitoring services (e.g., AWS CloudWatch, Azure Monitor, Google Cloud Operations) to track database activity. Set up alerts for suspicious events. |
Network Latency and Performance Bottlenecks
Network latency represents a significant challenge in serverless database interactions, as it directly impacts the responsiveness and efficiency of applications. Serverless functions, by their nature, are distributed and often require accessing databases located in different regions or availability zones. This distributed architecture can exacerbate the effects of network delays, leading to increased execution times and a degraded user experience. Understanding and mitigating network latency is therefore crucial for optimizing the performance of serverless applications that rely on database connectivity.
Impact of Network Latency on Database Performance
Network latency, defined as the time it takes for a data packet to travel from one point to another, can significantly affect database performance in serverless environments. Every database interaction, from establishing a connection to executing a query and receiving the results, is subject to this delay.
- Increased Execution Time: Higher latency translates to longer execution times for serverless functions. Each database request experiences a delay, and these delays accumulate, especially in applications with frequent database interactions. For example, a simple query that takes 10 milliseconds to execute locally might take 50 milliseconds or more in a serverless environment due to network latency.
- Reduced Throughput: Network latency limits the number of requests a serverless function can handle within a given timeframe. This is because each request ties up the function while waiting for a response from the database. High latency can significantly reduce the overall throughput of the application, especially during periods of high traffic.
- Impact on User Experience: Users perceive latency directly as delays in application responsiveness. Slow database interactions result in sluggish performance, leading to a poor user experience. This is particularly noticeable in applications that require real-time data updates or rapid responses to user actions.
- Resource Consumption: Prolonged execution times due to network latency can lead to increased resource consumption. Serverless functions might consume more compute time and memory while waiting for database responses, increasing operational costs. This is a critical consideration for applications with a high volume of database interactions.
Tools and Techniques for Measuring and Diagnosing Network-Related Performance Bottlenecks
Identifying and addressing network-related performance bottlenecks requires a methodical approach. Several tools and techniques can be employed to measure latency and diagnose the underlying causes of performance issues.
- Ping and Traceroute: These are fundamental network diagnostic tools. Ping measures the round-trip time (RTT) between a serverless function and the database, providing a basic latency measurement. Traceroute identifies the path data packets take and the latency at each hop along that path, helping to pinpoint where delays are occurring. These tools are readily available on most operating systems and can be used from within the serverless function’s execution environment or from a separate monitoring instance.
- Network Monitoring Tools: Tools like Wireshark or tcpdump can capture and analyze network traffic. These tools provide detailed insights into the data packets, including latency, packet loss, and retransmissions. Analyzing this data can reveal specific issues, such as slow DNS resolution or network congestion, contributing to latency.
- Cloud Provider Monitoring Services: Cloud providers offer comprehensive monitoring services that provide insights into network performance. These services often include metrics such as connection times, request latencies, and error rates. For example, AWS CloudWatch, Azure Monitor, and Google Cloud Monitoring can provide valuable data for diagnosing network-related performance issues in serverless environments. These services can be configured to collect and visualize network metrics automatically.
- Distributed Tracing: Distributed tracing tools, such as Jaeger or Zipkin, can trace requests as they flow through a distributed system. They provide insights into the latency of each component, including database interactions. These tools allow for the identification of slow database queries and other network-related bottlenecks that contribute to overall latency.
- Database-Specific Monitoring: Most database systems provide monitoring tools that track query performance and connection metrics. These tools can identify slow queries and provide insights into database-related bottlenecks that might be affected by network latency. Examining the query execution plans and connection statistics can help identify areas for optimization.
- Synthetic Monitoring: Synthetic monitoring involves simulating user interactions to measure the performance of specific application workflows. By simulating database requests from various locations, synthetic monitoring can help identify network-related performance issues from the user’s perspective.
Illustration of Network Flow Between a Serverless Function and a Database
The following illustration describes the network flow between a serverless function and a database, highlighting potential latency points.
Illustration: A diagram depicts the network flow between a serverless function and a database, illustrating potential latency points. The diagram features a serverless function icon, a network cloud icon, and a database icon, interconnected by labeled arrows representing the data flow.
Detailed Descriptive Text:
- Serverless Function: Located in a specific availability zone within a cloud provider’s infrastructure. The serverless function is the entry point for requests.
- Network Cloud: Represents the network infrastructure, including routers, switches, and other network devices, that connects the serverless function to the database.
- Database: Resides in a separate availability zone, potentially in a different region. The database is the target of the requests.
- Network Flow and Latency Points: The diagram illustrates the following steps with associated latency points:
- Request Initiation (Function to Network): An arrow indicates the request from the serverless function to the network. The initial latency involves the time taken for the function to format and transmit the request.
- Network Routing (Network): The request traverses the network, potentially passing through multiple routers and switches. Each hop contributes to the overall latency. Latency at this stage depends on the network congestion and the physical distance between the function and the database.
- Database Connection (Network to Database): The request reaches the database, where a connection is established (if not already present). The connection establishment process itself can introduce latency.
- Query Execution (Database): The database processes the query. This involves parsing, optimizing, and executing the query, which contributes to the overall latency.
- Response Transmission (Database to Network): The database sends the response back to the network. This includes the time taken to format the response and transmit it over the network.
- Response Reception (Network to Function): The response travels back through the network to the serverless function. This mirrors the forward path and introduces similar latency.
- Function Processing (Function): The serverless function receives the response and processes it. This is the time taken for the function to handle the result and complete its execution.
- Latency Factors: Each stage introduces latency, which can be affected by:
- Physical Distance: The geographical distance between the serverless function and the database significantly impacts latency. Longer distances result in higher latency due to the time it takes for data to travel.
- Network Congestion: Congestion on the network paths can increase latency as data packets are delayed.
- Network Device Performance: The performance of routers, switches, and other network devices can impact latency.
- Database Load: High database load can lead to increased query execution times and contribute to overall latency.
Monitoring and Logging for Database Connections
Effective monitoring and logging are critical for maintaining the health and performance of database connections within serverless applications. Serverless environments, by their ephemeral nature, present unique challenges in observability. Without robust monitoring, developers struggle to identify and resolve connection-related issues, leading to degraded application performance, increased latency, and potential data loss. Proactive monitoring allows for early detection of problems, enabling timely intervention and preventing cascading failures.
Importance of Monitoring Database Connections
Monitoring database connections is paramount in serverless architectures due to their dynamic and often short-lived nature. The ability to observe connection behavior is essential for troubleshooting, performance optimization, and ensuring the reliability of applications. This includes tracking connection establishment, lifecycle events, resource utilization, and error occurrences.
- Proactive Issue Detection: Monitoring provides real-time insights into connection health, allowing for the early identification of bottlenecks, connection leaks, and other performance issues before they impact users. For instance, by tracking the number of active connections, developers can detect sudden spikes or sustained high connection counts, potentially indicating a problem with connection pooling or inefficient database queries.
- Performance Optimization: Detailed monitoring data helps pinpoint areas for optimization. By analyzing connection latency, query execution times, and resource consumption, developers can identify inefficient database interactions and optimize code or database configurations. For example, monitoring can reveal slow query execution times, prompting developers to optimize database indexes or rewrite queries.
- Capacity Planning: Monitoring connection usage provides valuable data for capacity planning. Understanding connection patterns and resource consumption helps developers scale their serverless functions and database resources appropriately to meet demand. Monitoring can reveal that connection pools are frequently exhausted during peak traffic periods, indicating the need to increase pool sizes or scale database resources.
- Security and Compliance: Monitoring connection activity is crucial for security and compliance purposes. It allows for the detection of unauthorized access attempts, unusual connection patterns, and potential data breaches. By logging connection events, including IP addresses, user credentials, and access times, organizations can maintain an audit trail and comply with regulatory requirements.
- Improved Debugging and Troubleshooting: Comprehensive monitoring data significantly simplifies debugging and troubleshooting. When issues arise, developers can use monitoring tools to quickly identify the root cause by correlating connection events with application logs and performance metrics. For example, if a function fails to connect to the database, monitoring data can help pinpoint whether the problem lies with the database, network connectivity, or the function’s configuration.
Methods for Implementing Logging and Tracing for Database Interactions
Implementing effective logging and tracing for database interactions involves capturing detailed information about connection events, query execution, and error occurrences. This data should be collected, stored, and analyzed to provide insights into connection behavior and performance. The choice of logging and tracing methods depends on the specific serverless platform and database technology used.
- Structured Logging: Utilize structured logging formats like JSON to facilitate efficient data analysis. This enables the easy filtering and querying of log data. Each log entry should include relevant context, such as function name, request ID, connection details, and error information. For example:
"timestamp": "2024-07-26T10:00:00Z",
"function_name": "my-function",
"request_id": "abc123",
"connection_id": "conn-123",
"query": "SELECT
- FROM users WHERE id = 1",
"duration_ms": 10,
"status": "success" - Database-Specific Logging: Leverage database-specific logging features to capture detailed information about query execution, connection events, and errors. Most databases offer logging capabilities that can be configured to capture slow queries, connection attempts, and other relevant events. For instance, PostgreSQL’s `log_statement` and `log_min_duration_statement` parameters allow for logging of all statements and slow queries.
- Distributed Tracing: Implement distributed tracing to track requests as they traverse multiple services and components. This helps to identify bottlenecks and understand the end-to-end performance of database interactions. Tools like AWS X-Ray, Jaeger, and Zipkin can be integrated with serverless functions and database clients to capture trace data. This allows for visualization of the flow of a request, showing latency at each stage, including database queries.
- Connection Pooling Monitoring: Monitor the performance of connection pools, which are often used to manage database connections in serverless environments. Track metrics such as connection pool size, active connections, idle connections, and connection acquisition/release times. Tools and libraries often provide built-in metrics and logging for connection pools. For example, the `HikariCP` connection pool library in Java provides detailed metrics on connection usage.
- Error Handling and Alerting: Implement robust error handling and alerting mechanisms to promptly notify developers of connection-related issues. Capture and log all database connection errors, including connection timeouts, authentication failures, and query errors. Integrate these errors with alerting systems to automatically notify the development team. For example, set up alerts in cloud monitoring services like AWS CloudWatch or Google Cloud Monitoring to trigger notifications when database connection errors exceed a defined threshold.
Process for Setting Up Alerts for Database Connection Issues
Setting up alerts for database connection issues involves defining specific metrics, setting thresholds, and configuring notification channels. This proactive approach ensures that developers are promptly notified of any connection problems, enabling rapid response and minimizing downtime.
- Define Key Metrics: Identify the critical metrics to monitor for database connection health. This should include metrics like:
- Connection errors (e.g., connection timeouts, authentication failures).
- Number of active connections.
- Connection pool exhaustion.
- Query execution times (e.g., slow queries).
- Database latency.
- Establish Thresholds: Determine appropriate thresholds for each metric based on the application’s performance requirements and the database’s capacity. For example:
- Alert when connection errors exceed a certain rate (e.g., more than 5 errors per minute).
- Alert when the number of active connections reaches a predefined limit (e.g., 90% of the maximum connection pool size).
- Alert when query execution times exceed a specific duration (e.g., queries taking longer than 1 second).
- Configure Alerting Systems: Set up alerts using a cloud monitoring service or a dedicated alerting platform. Configure the alerts to trigger notifications when metrics exceed the defined thresholds. Popular cloud monitoring services include AWS CloudWatch, Google Cloud Monitoring, and Azure Monitor.
- Specify the alert conditions (e.g., metric name, operator, threshold).
- Define the notification channels (e.g., email, Slack, PagerDuty).
- Configure notification recipients (e.g., development team, on-call engineers).
- Test Alerts: Verify that the alerts are functioning correctly by simulating connection issues or triggering events that would violate the thresholds. This can be achieved by:
- Intentionally causing database connection errors (e.g., by providing incorrect credentials or simulating network issues).
- Running slow queries to trigger the slow query alert.
- Verifying that notifications are received through the configured channels.
- Refine and Iterate: Continuously monitor the performance of the alerting system and refine the metrics, thresholds, and notification channels as needed. Review the alert history to identify any false positives or false negatives.
- Adjust thresholds based on observed performance patterns.
- Add or remove metrics based on the application’s evolving needs.
- Optimize notification channels to ensure timely and effective communication.
Cost Optimization for Database Connections
Serverless architectures offer significant cost advantages, but database connections can become a major expense if not managed efficiently. Optimizing these connections requires a multi-faceted approach, considering connection pooling, query optimization, and the overall design of the serverless application. This section will explore strategies to minimize costs associated with database connections in serverless functions.
Strategies to Minimize Database Connection Costs
Several strategies can be employed to reduce database connection costs in serverless environments. These focus on efficient resource utilization and minimizing the duration and frequency of database interactions.
- Connection Pooling: Implementing connection pooling allows serverless functions to reuse existing database connections instead of establishing new ones for each invocation. This reduces the overhead of connection initialization, authentication, and teardown, leading to cost savings. Libraries and services like AWS RDS Proxy can facilitate connection pooling for various database systems.
- Connection Lifecycle Management: Efficiently managing the lifecycle of database connections is crucial. Connections should be opened only when needed and closed promptly after use. Using connection objects within the scope of the function execution helps ensure that connections are released efficiently.
- Query Optimization: Optimizing database queries can significantly reduce costs. This includes writing efficient SQL queries, using indexes appropriately, and avoiding unnecessary data retrieval. Profiling database queries to identify performance bottlenecks is essential.
- Data Caching: Implementing caching mechanisms, such as using in-memory caches or caching services like Redis, can reduce the number of database queries. This is particularly effective for frequently accessed data that does not change often.
- Database Selection: Choosing the right database service for the workload is essential. For example, serverless database options like Amazon Aurora Serverless v2 or Google Cloud SQL Autoscale can automatically scale resources, minimizing costs during periods of low activity.
- Resource Allocation: Right-sizing the resources allocated to serverless functions is crucial. Functions should be configured with the appropriate memory and CPU allocation to ensure efficient query execution and avoid unnecessary resource consumption.
- Monitoring and Alerting: Implementing comprehensive monitoring and alerting can help identify cost anomalies and performance bottlenecks related to database connections. This allows for proactive optimization and prevents unexpected cost overruns.
Optimizing Database Query Costs
Optimizing database query costs is a key component of overall cost reduction. This involves careful design and execution of database queries to minimize resource consumption.
- Efficient SQL Queries: Writing efficient SQL queries is fundamental. This includes using appropriate `WHERE` clauses to filter data, avoiding `SELECT
-` to retrieve only necessary columns, and using `JOIN` operations efficiently. - Index Utilization: Proper indexing can dramatically improve query performance. Indexes should be created on columns frequently used in `WHERE` clauses and `JOIN` operations. However, over-indexing can negatively impact write performance, so careful consideration is required.
- Query Profiling: Profiling database queries helps identify performance bottlenecks. Tools like `EXPLAIN` in MySQL or PostgreSQL can provide insights into query execution plans, highlighting areas for optimization.
- Batch Operations: When possible, batching multiple database operations into a single transaction can reduce the overhead of individual queries. This is particularly effective for insert, update, and delete operations.
- Data Retrieval Strategies: Consider the data retrieval strategy. For example, using pagination to retrieve large datasets in chunks can prevent timeouts and reduce resource consumption compared to retrieving the entire dataset at once.
- Stored Procedures: Utilizing stored procedures for complex database operations can sometimes improve performance by pre-compiling and optimizing the query execution plan.
Managing Database Connection Costs Based on Function Invocation Frequency: An Example
The frequency of function invocations significantly impacts database connection costs. The following example illustrates how to manage these costs based on invocation frequency.
- Low Invocation Frequency (e.g., < 100 invocations/day): For functions invoked infrequently, the primary concern is to minimize the per-invocation overhead. This might involve:
- Opening and closing connections within each function invocation.
- Using connection pooling libraries, but with a small pool size to minimize resource consumption when the function is idle.
- Optimizing queries to reduce the execution time of each query, thus minimizing the duration of the connection.
- Moderate Invocation Frequency (e.g., 100-1000 invocations/day): As the invocation frequency increases, connection pooling becomes more critical. This approach would involve:
- Implementing robust connection pooling with a moderate pool size, allowing for reuse of existing connections.
- Monitoring connection pool utilization to ensure optimal sizing and prevent connection exhaustion.
- Caching frequently accessed data to reduce the number of database queries.
- High Invocation Frequency (e.g., > 1000 invocations/day): At high invocation frequencies, scaling database connections becomes paramount. This might require:
- Utilizing a dedicated connection pool service like AWS RDS Proxy or a similar service provided by the database provider.
- Scaling the database resources to handle the increased load.
- Implementing aggressive caching strategies to reduce database load.
- Optimizing queries and database schema to ensure efficient performance under heavy load.
Database Connection Libraries and Frameworks
The selection of appropriate database connection libraries and frameworks significantly impacts the performance, scalability, and maintainability of serverless functions interacting with databases. Different libraries offer varying levels of abstraction, connection pooling strategies, and support for different database systems. Choosing the right one involves balancing ease of use, performance considerations, and the specific requirements of the serverless application. This section delves into the comparison of popular libraries and frameworks, provides practical examples, and offers a step-by-step guide for implementing a specific library.
Comparison of Database Connection Libraries and Frameworks
Different database connection libraries and frameworks cater to various needs in serverless environments. Their capabilities can be broadly categorized by their abstraction level, performance characteristics, and supported database systems.
- Abstraction Level: Libraries range from low-level drivers, which provide direct access to database protocols, to high-level ORMs (Object-Relational Mappers) that abstract away much of the database interaction complexity.
- Low-level drivers (e.g., `psycopg2` for PostgreSQL, `mysql.connector` for MySQL) offer the most control over connection management and query optimization but require more manual coding. They are generally preferred for fine-grained control over database interactions.
- ORMs (e.g., SQLAlchemy, Prisma, Django ORM) provide a higher level of abstraction, allowing developers to interact with the database using object-oriented paradigms. This can simplify development and improve code readability, but may introduce performance overhead due to the abstraction layer.
- Performance: Connection pooling is a crucial factor in serverless environments to mitigate the impact of cold starts. Libraries with built-in connection pooling or those that can be easily integrated with connection pooling mechanisms (e.g., using a proxy like PgBouncer) are generally preferred. Performance also depends on the efficiency of query execution and the overhead of the library itself.
- Supported Database Systems: Libraries often support a specific set of database systems. For example, `psycopg2` is specifically for PostgreSQL, while SQLAlchemy supports multiple databases through different dialect drivers. The choice of library should align with the database system being used.
Integration of Popular Libraries with Serverless Platforms
Integrating popular database connection libraries like SQLAlchemy and Prisma with serverless platforms involves configuring the library to work within the constraints of the serverless environment, such as connection management and cold start optimization.
- SQLAlchemy: SQLAlchemy is a powerful Python SQL toolkit and ORM that supports various database systems. Integrating SQLAlchemy with a serverless function typically involves:
- Configuring a database connection string that includes the necessary credentials and database endpoint.
- Managing connection pooling to reuse connections and minimize the impact of cold starts. The `sqlalchemy.pool.QueuePool` or the use of connection proxies (e.g., PgBouncer) can be beneficial.
- Handling connection errors and retries to ensure resilience.
- Prisma: Prisma is a modern ORM for Node.js and TypeScript that provides a type-safe database access layer. Integration with serverless functions typically involves:
- Installing the Prisma client and configuring the Prisma schema to define the database model.
- Initializing the Prisma client at the beginning of the function execution. The client is designed to be initialized once and reused across multiple function invocations within a single container instance to improve performance.
- Managing the Prisma client’s lifecycle, ensuring it is properly closed when the function completes.
Step-by-Step Guide: Implementing SQLAlchemy in a Serverless Function
Implementing SQLAlchemy in a serverless function requires careful consideration of connection management and cold start optimization. The following steps provide a detailed guide.
- Step 1: Install SQLAlchemy and the Database Driver
Install SQLAlchemy and the appropriate database driver for your chosen database system (e.g., `psycopg2` for PostgreSQL, `mysqlclient` for MySQL). This is typically done using a package manager like pip.
pip install sqlalchemy psycopg2-binary - Step 2: Configure the Database Connection String
Create a database connection string that includes the database type, host, port, database name, username, and password. Store the connection string securely (e.g., as an environment variable) and retrieve it within your serverless function code.
import os DATABASE_URL = os.environ.get("DATABASE_URL") - Step 3: Establish a Connection and Define a Session
Use SQLAlchemy’s `create_engine` function to establish a connection to the database. For serverless environments, consider using a connection pool (e.g., `QueuePool`) to reuse connections. Create a session using `Session = sessionmaker(bind=engine)`.
from sqlalchemy import create_engine from sqlalchemy.orm import sessionmaker engine = create_engine(DATABASE_URL, pool_size=10, max_overflow=20) # Example using a QueuePool Session = sessionmaker(bind=engine) - Step 4: Execute Queries
Within your serverless function, use the session to execute database queries. Example: query a table named ‘users’.
from sqlalchemy import Column, Integer, String from sqlalchemy.ext.declarative import declarative_base Base = declarative_base() class User(Base): __tablename__ = 'users' id = Column(Integer, primary_key=True) name = Column(String) def lambda_handler(event, context): session = Session() try: user = session.query(User).filter_by(id=1).first() if user: return 'statusCode': 200, 'body': f"User name: user.name" else: return 'statusCode': 404, 'body': "User not found" except Exception as e: print(f"Error: e") return 'statusCode': 500, 'body': "Internal Server Error" finally: session.close() # Ensure the session is closed. - Step 5: Close the Connection
Ensure the database connection is closed after each function invocation, either by closing the session within a `finally` block or by using a context manager (e.g., `with session:`) to handle the session’s lifecycle automatically. This prevents connection leaks and frees up database resources.
# Example using a context manager def lambda_handler(event, context): with Session() as session: try: # Perform database operations pass except Exception as e: print(f"Error: e") return 'statusCode': 500, 'body': "Internal Server Error"
Conclusion
In conclusion, navigating the challenges of database connections in serverless requires a multifaceted approach. Addressing cold starts, scaling connections, managing timeouts, and ensuring robust security are paramount. Furthermore, optimizing network performance, implementing effective monitoring, and considering cost implications are critical for realizing the full potential of serverless architectures. By understanding these complexities and implementing best practices, developers can build scalable, performant, and secure applications that leverage the benefits of both serverless computing and relational or non-relational databases.
Question Bank
What is the impact of cold starts on database connections?
Cold starts can significantly increase the latency of database interactions. Each function invocation might require re-establishing a connection, leading to delays, especially with complex initialization procedures.
How does connection pooling help mitigate cold start issues?
Connection pooling pre-establishes a set of database connections, allowing serverless functions to quickly reuse them, bypassing the overhead of creating a new connection on each invocation, and improving response times.
What are the security risks associated with database credentials in serverless?
Exposing database credentials directly in the code or environment variables can lead to vulnerabilities. Compromised credentials can grant unauthorized access to sensitive data. Best practices include using secrets management services and least privilege principles.
How can I monitor database connection performance in a serverless environment?
Implement monitoring tools to track connection metrics like connection time, query execution time, and error rates. Logging and tracing are essential for diagnosing issues and optimizing performance.
What database types are best suited for serverless applications?
NoSQL databases, like DynamoDB, are often a good fit due to their scalability and ease of integration. However, SQL databases can also be used effectively with proper connection management and optimization techniques.