The landscape of large-scale data migrations is often fraught with complexity, risk, and the potential for significant disruption. What is a migration factory approach for large scale migrations presents a structured methodology designed to streamline and optimize these complex processes. This approach, inspired by manufacturing principles, leverages automation, standardization, and a focus on repeatable processes to minimize errors, reduce downtime, and improve the overall efficiency of data migration projects.
This analytical exploration will delve into the core tenets of the migration factory approach, examining its architectural components, planning phases, and critical operational strategies. We will dissect the ETL processes, automation techniques, and testing methodologies that underpin a successful migration factory implementation. Furthermore, we will investigate the governance and control mechanisms necessary to maintain data integrity and ensure project success, culminating in real-world case studies that illustrate the practical application and benefits of this transformative approach.
Defining the Migration Factory Approach
The migration factory approach represents a structured and industrialized methodology for executing large-scale data migrations. It moves away from ad-hoc, project-specific approaches and instead adopts a standardized, repeatable, and scalable framework. This approach emphasizes automation, process optimization, and the utilization of specialized teams and tools to improve efficiency, reduce risks, and accelerate the migration process.
Core Principles of the Migration Factory Approach
The migration factory approach is underpinned by several core principles that differentiate it from traditional migration strategies. These principles are crucial for its effectiveness in managing the complexity and scale of large-scale data migrations.
- Standardization: Standardization is a cornerstone, involving the creation of consistent processes, templates, and tools. This ensures uniformity across all migration projects, regardless of the specific data or target systems. This includes standardized data mapping, transformation rules, and validation procedures. The goal is to minimize variations and ensure predictability. For example, a standard template for data profiling reports helps to quickly assess data quality and identify potential issues early in the process.
- Automation: Automation plays a pivotal role in streamlining the migration process and reducing manual effort. Automation encompasses various aspects, including data extraction, transformation, loading (ETL) processes, data validation, and error handling. Automated workflows can significantly reduce the time required for each migration phase, leading to faster project completion. A real-world example is the automated execution of data quality checks after data transformation, triggering alerts for data discrepancies.
- Modularity: The migration factory approach promotes a modular design where the migration process is broken down into discrete, reusable components. These components, such as data connectors, transformation modules, and validation scripts, can be combined and reused across different migration projects. This modularity enables greater flexibility and allows for the rapid adaptation to changing requirements. For instance, a pre-built module for handling specific data types, like dates or currencies, can be readily applied to multiple migration tasks.
- Specialization: The migration factory model emphasizes the formation of specialized teams, each focusing on specific aspects of the migration process. These teams, such as data engineers, data analysts, and migration specialists, possess specialized skills and knowledge. Specialization allows for increased efficiency and expertise within each area, contributing to higher-quality results. An example is a dedicated team for data mapping and transformation, ensuring data integrity during the transition.
- Continuous Improvement: The approach incorporates a feedback loop to continuously monitor, evaluate, and refine the migration process. This includes tracking key performance indicators (KPIs), analyzing performance metrics, and identifying areas for improvement. Regular assessments and process adjustments contribute to increased efficiency and reduced risks over time. For instance, after each migration wave, a post-migration review identifies bottlenecks and opportunities for optimization in subsequent waves.
Benefits of Using a Migration Factory Approach for Large-Scale Data Migrations
Employing a migration factory approach offers numerous benefits, particularly when dealing with the complexities and scale of large-scale data migrations. These benefits span across various dimensions, from project timelines to resource utilization.
- Reduced Migration Time and Costs: The standardization and automation inherent in the migration factory approach lead to significant reductions in migration time and associated costs. Automated processes and reusable components minimize manual effort and accelerate the overall migration timeline. For example, a company migrating its customer data to a new CRM system can expect a reduction of up to 30% in migration time by using a factory approach, compared to a traditional project-based approach.
- Improved Data Quality and Consistency: Standardized data transformation and validation processes ensure data quality and consistency across the migrated data. Automated data quality checks and validation rules help identify and rectify data discrepancies early in the process, reducing the risk of data corruption or inconsistencies. In a case study, a financial institution improved data accuracy by 20% during a migration project by implementing automated data validation routines.
- Enhanced Scalability and Flexibility: The modular design and standardized processes of the migration factory approach enable greater scalability and flexibility. The ability to reuse components and adapt to changing requirements makes it easier to handle increasing data volumes and evolving business needs. A retail company, for instance, can easily scale its data migration efforts to accommodate new product lines or expansion into new markets.
- Minimized Risks: Standardized processes, rigorous testing, and proactive error handling mechanisms help minimize risks associated with data migrations. Automation reduces the potential for human error, and the modular design allows for easier identification and resolution of issues. For example, implementing a comprehensive testing strategy, including pre-migration data validation and post-migration reconciliation, can reduce data loss risks by up to 15%.
- Increased Resource Efficiency: The migration factory approach optimizes resource utilization by assigning specialized teams and automating repetitive tasks. This allows organizations to make better use of their resources, reduce reliance on specialized expertise, and improve overall project efficiency. For example, by automating the ETL processes, a company can free up its data engineers to focus on more complex tasks.
Common Challenges Addressed by the Migration Factory Approach
The migration factory approach directly addresses several common challenges that organizations face during large-scale data migrations. These challenges, if not properly addressed, can lead to project delays, cost overruns, and data quality issues.
- Complexity of Data Mapping and Transformation: Data mapping and transformation are often the most complex and time-consuming aspects of data migrations. The migration factory approach provides standardized tools and processes to simplify data mapping and transformation. The approach can significantly reduce the effort required to map data from source to target systems. For instance, using pre-built data mapping templates and automated transformation rules can reduce data mapping efforts by up to 40%.
- Data Quality Issues: Poor data quality can severely impact the success of a migration project. The migration factory approach incorporates rigorous data validation and cleansing processes to ensure data quality. Automated data quality checks, such as data profiling and validation rules, can identify and correct data quality issues before they impact the target system. A manufacturing company, by implementing automated data cleansing routines, was able to improve the accuracy of its product data by 25%.
- Lack of Standardization: Without standardization, each migration project becomes a unique undertaking, increasing the risk of errors and delays. The migration factory approach establishes standardized processes, templates, and tools to ensure consistency and repeatability. For example, by implementing a standardized data migration framework, a healthcare organization reduced the time required to migrate patient data from multiple legacy systems.
- Inefficient Resource Utilization: Traditional migration approaches often rely on specialized resources, leading to inefficient resource allocation. The migration factory approach leverages specialized teams and automation to optimize resource utilization. This approach ensures that resources are deployed effectively, reducing the need for highly specialized skills for routine tasks. An insurance company, by forming specialized migration teams, improved resource utilization by 20%, leading to cost savings and faster project completion.
- Inadequate Testing and Validation: Insufficient testing and validation can lead to data integrity issues and system failures. The migration factory approach emphasizes comprehensive testing and validation at each stage of the migration process. Automated testing and validation routines help to ensure data accuracy and system functionality. By incorporating automated testing and validation processes, a telecommunications company reduced data errors during its migration by 30%.
Key Components and Architecture
The migration factory approach, when implemented effectively, transforms the complex and often unpredictable process of large-scale data migrations into a streamlined, repeatable, and scalable operation. This is achieved through a carefully designed architecture that incorporates several key components, each playing a critical role in ensuring the successful transfer of data while minimizing downtime and mitigating risks. The following sections will detail these essential elements and the architectural patterns that govern their interaction.
Essential Components of a Migration Factory Architecture
A well-defined migration factory relies on several core components working in concert. These components facilitate data extraction, transformation, loading, and validation, ensuring data integrity and minimizing disruption to business operations. The architecture must support these functions in a flexible and adaptable manner to accommodate the diverse requirements of different migration projects.
- Data Extraction Component: This component is responsible for extracting data from the source systems. It utilizes connectors and APIs to access various data sources, including databases, file systems, and cloud storage. The extraction process should be designed to minimize the impact on the source system’s performance.
- Data Transformation Component: The transformation component cleans, transforms, and enriches the extracted data. This involves data type conversions, data cleansing (e.g., removing duplicates, correcting inconsistencies), and data enrichment (e.g., adding missing values, standardizing formats). The transformation process is often the most complex and time-consuming aspect of a migration, requiring careful planning and execution.
- Data Loading Component: This component loads the transformed data into the target systems. It utilizes appropriate connectors and APIs to interact with the target systems, ensuring data is loaded efficiently and securely. This includes handling data partitioning, indexing, and other optimization techniques to improve performance.
- Orchestration and Workflow Engine: This central component manages and coordinates the entire migration process. It defines the sequence of tasks, monitors progress, and handles error conditions. The workflow engine provides a framework for automating the migration process, allowing for repeatable and scalable migrations.
- Monitoring and Logging Component: This component tracks the progress of the migration, captures errors, and generates reports. It provides real-time visibility into the migration process, allowing for proactive identification and resolution of issues. Comprehensive logging is crucial for auditing and troubleshooting.
- Data Validation Component: This component verifies the integrity and accuracy of the migrated data. It compares data between the source and target systems, identifies discrepancies, and reports any issues. Data validation is critical for ensuring the migrated data meets the required quality standards.
- Security and Access Control Component: This component secures the data during the migration process, ensuring compliance with data privacy regulations. It manages access control, encrypts data in transit and at rest, and implements other security measures to protect sensitive information.
The Role of Automation in a Migration Factory
Automation is a fundamental principle of the migration factory approach. It enables the creation of repeatable, efficient, and scalable migration processes. Automation streamlines tasks, reduces manual effort, and minimizes the risk of human error. The degree of automation can vary depending on the specific requirements of the migration project, but the overall goal is to automate as much of the process as possible.
- Automated Data Extraction: Automated extraction processes utilize pre-configured connectors and scripts to retrieve data from various source systems. This reduces the need for manual intervention and accelerates the data acquisition phase.
- Automated Data Transformation: Automated transformation processes apply predefined rules and scripts to cleanse, transform, and enrich data. This eliminates the need for manual data manipulation and ensures consistency across the migrated data.
- Automated Data Loading: Automated loading processes use pre-configured connectors and scripts to load transformed data into the target systems. This streamlines the data transfer process and reduces the risk of errors.
- Automated Orchestration and Workflow Management: Automated workflow engines manage the sequence of tasks, monitor progress, and handle error conditions. This allows for the creation of repeatable and scalable migration processes.
- Automated Testing and Validation: Automated testing and validation processes compare data between source and target systems, identify discrepancies, and generate reports. This ensures data integrity and accuracy.
Automation, in essence, allows the migration factory to operate as a well-oiled machine, consistently delivering high-quality results with minimal manual intervention.
Architectural Patterns Used in Migration Factories
Several architectural patterns are commonly employed in migration factories to address specific challenges and optimize performance. These patterns provide a framework for designing and implementing the various components of the migration factory.
- Extract, Transform, Load (ETL): This is the most prevalent pattern, where data is extracted from source systems, transformed, and then loaded into the target system. This pattern can be implemented using various tools and technologies, and the choice of tools depends on factors such as data volume, complexity, and the target system’s capabilities.
- Change Data Capture (CDC): CDC is employed when the source system is continuously updated. CDC identifies and captures only the changes made to the source data since the last migration cycle, enabling incremental migrations and minimizing downtime. This approach is particularly useful for migrating databases and other systems that undergo frequent updates.
- Data Lake Approach: In this pattern, data from various sources is first ingested into a data lake, where it can be stored in its raw format. Then, the data is transformed and loaded into the target system. This approach offers flexibility and scalability, as it allows for the integration of data from multiple sources and the ability to perform complex transformations.
- Microservices Architecture: This architecture decomposes the migration factory into a collection of independent, loosely coupled services. Each service performs a specific function, such as data extraction, transformation, or loading. This pattern promotes scalability, maintainability, and resilience.
- Serverless Architecture: Serverless computing allows the execution of code without managing servers. This approach can be used to implement various components of the migration factory, such as data transformation and data validation, providing scalability and cost efficiency.
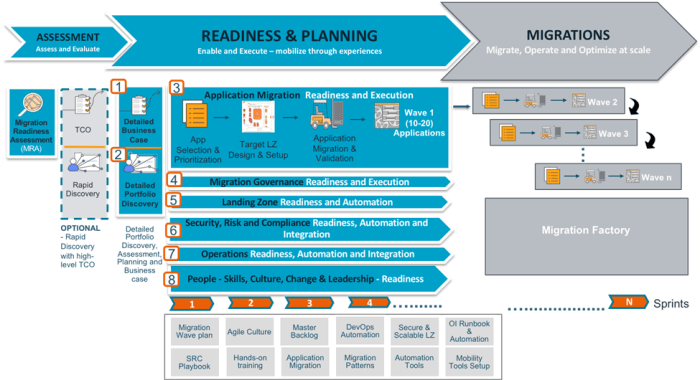
Planning and Preparation Phase

The Planning and Preparation Phase is the foundational stage of a migration factory project. It dictates the overall success of the migration by defining the scope, identifying potential risks, and establishing the necessary resources and procedures. Thorough planning minimizes disruptions, optimizes resource allocation, and ensures a smooth transition to the target environment. This phase is characterized by meticulous analysis, detailed documentation, and proactive risk mitigation strategies.
Steps in the Planning Phase
The planning phase involves several critical steps, each contributing to a comprehensive and well-defined migration strategy.
- Defining Scope and Objectives: This involves clearly articulating the goals of the migration, including which systems, data, and applications are to be migrated. It also requires defining the desired outcomes, such as improved performance, cost reduction, or enhanced security. This step culminates in a detailed scope document that serves as the blueprint for the entire project. A specific example would be migrating a customer relationship management (CRM) system from an on-premises environment to a cloud-based platform, aiming to improve data accessibility and scalability while reducing infrastructure costs.
- Assessing the Current State (Source System Analysis): This involves a comprehensive evaluation of the existing IT infrastructure, including hardware, software, network, and data. This analysis identifies dependencies, potential compatibility issues, and existing data quality problems. This assessment includes a thorough understanding of the source system’s architecture, data models, and business processes. For instance, if migrating a legacy mainframe system, this would involve analyzing the COBOL code, database structure, and associated batch processes.
- Defining the Target State: This step focuses on designing the future-state environment, including the selection of the target platform, the architecture, and the security protocols. It involves determining the optimal configuration for the new environment to meet the project’s objectives. The target state definition considers factors such as scalability, performance, and cost-effectiveness. An example would be selecting a specific cloud provider (e.g., AWS, Azure, or GCP) and defining the virtual machine instances, storage solutions, and network configurations needed to support the migrated applications.
- Developing the Migration Strategy: This crucial step involves creating a detailed plan outlining how the migration will be executed. It includes selecting the appropriate migration approach (e.g., lift and shift, re-platforming, or re-architecting), defining the migration phases, and establishing a timeline. The strategy must address data migration, application migration, and cutover procedures. A phased migration approach, for instance, could involve migrating applications in batches, starting with non-critical systems to minimize disruption and allow for iterative testing and refinement.
- Resource Planning and Budgeting: This step focuses on identifying and securing the necessary resources, including personnel, tools, and infrastructure. It involves creating a detailed budget that covers all aspects of the migration, including labor, software licenses, hardware, and cloud services. A comprehensive budget is critical for ensuring the financial viability of the project.
- Risk Assessment and Mitigation Planning: This involves identifying potential risks that could impact the migration, such as data loss, downtime, security breaches, and project delays. A risk mitigation plan Artikels the steps to be taken to address these risks. For instance, if data corruption is a potential risk, the mitigation plan would include data validation procedures and backup and recovery strategies.
- Developing the Communication Plan: This ensures all stakeholders are informed about the migration progress. It Artikels the communication channels, frequency, and the content to be shared with different audiences. This includes regular updates to project sponsors, end-users, and IT staff.
Checklist for Assessing Source System Readiness
Assessing the readiness of source systems is crucial to identify potential roadblocks and ensure a successful migration. A comprehensive checklist helps to systematically evaluate the source environment.
- Data Analysis and Profiling:
- Conduct a comprehensive data inventory to identify all data sources and their characteristics.
- Perform data profiling to understand data quality, structure, and relationships.
- Analyze data volume, growth rates, and storage requirements.
- Application Assessment:
- Identify all applications and their dependencies.
- Assess application compatibility with the target environment.
- Analyze application performance and resource utilization.
- Infrastructure Assessment:
- Evaluate the hardware and software infrastructure.
- Assess network connectivity and bandwidth.
- Analyze security configurations and compliance requirements.
- Dependency Mapping:
- Identify all dependencies between applications and data sources.
- Map the relationships between different systems and components.
- Analyze the impact of migrating dependent systems.
- Security Assessment:
- Evaluate security vulnerabilities and risks.
- Assess compliance with relevant regulations and standards (e.g., GDPR, HIPAA).
- Implement security controls to protect data during migration.
- Performance Testing:
- Conduct performance tests to establish baseline metrics.
- Simulate migration scenarios to identify performance bottlenecks.
- Optimize performance settings for the target environment.
- Backup and Recovery Planning:
- Develop a comprehensive backup and recovery strategy.
- Test backup and recovery procedures to ensure data integrity.
- Implement disaster recovery mechanisms.
Procedure for Data Profiling and Data Quality Assessment
Data profiling and quality assessment are critical steps in ensuring the accuracy and integrity of migrated data. A structured procedure helps to identify and address data quality issues proactively.
- Data Source Identification and Inventory: The first step is to identify and document all data sources involved in the migration. This includes databases, flat files, APIs, and other data repositories. An inventory should be created that details the location, format, and data types of each source.
- Data Profiling: This involves analyzing the data to understand its characteristics, including data types, value ranges, completeness, and consistency. Data profiling tools can automate this process, providing insights into data quality issues.
- Column Analysis: Examine each column for data types, null values, unique values, and data distributions.
- Value Analysis: Analyze the values within each column for patterns, outliers, and data inconsistencies.
- Relationship Analysis: Identify relationships between tables and columns to ensure data integrity.
- Data Quality Rule Definition: Define a set of data quality rules based on business requirements and data profiling results. These rules specify the criteria for data accuracy, completeness, consistency, and validity. Examples include:
- Ensuring that all required fields are populated.
- Validating data against predefined formats and ranges.
- Checking for duplicate records.
- Data Quality Assessment: Apply the data quality rules to the data to identify and quantify data quality issues. This process involves running data quality checks and generating reports that highlight errors and inconsistencies.
- Data Cleansing and Transformation: Based on the assessment results, implement data cleansing and transformation procedures to correct data quality issues. This may involve:
- Standardizing data formats.
- Correcting spelling errors and inconsistencies.
- Handling missing values.
- Removing duplicate records.
- Data Validation and Verification: After data cleansing and transformation, validate the data to ensure that the quality issues have been resolved. This involves re-running the data quality checks and verifying the results.
- Data Quality Reporting and Monitoring: Generate reports that document the data quality assessment process, including the identified issues, the implemented corrections, and the overall data quality metrics. Establish ongoing monitoring to track data quality over time and identify potential issues.
Data Extraction, Transformation, and Loading (ETL) Processes
The Data Extraction, Transformation, and Loading (ETL) processes are the backbone of any successful migration factory. They ensure data integrity, consistency, and usability throughout the migration lifecycle. Efficient ETL processes are critical for minimizing downtime, reducing risks, and optimizing resource utilization during large-scale migrations. This section delves into the specific ETL methodologies employed within a migration factory, compares various ETL tools, and provides examples of data transformation techniques.
ETL Processes within a Migration Factory
Within a migration factory, ETL processes are highly structured and often automated to handle the volume, velocity, and variety of data encountered. The following stages are typically involved:
- Data Extraction: This phase involves retrieving data from source systems. This requires establishing connections to various databases, applications, and file systems. Data extraction methods include full extraction (extracting all data) and incremental extraction (extracting only changed data). The choice depends on the source system, the volume of data, and the frequency of migrations.
- Data Profiling: Before transformation, data profiling assesses data quality and identifies anomalies. This includes analyzing data types, checking for missing values, and understanding data distributions. Profiling provides insights that inform transformation rules and helps in data cleansing.
- Data Transformation: This is the core of the ETL process, where data is converted into a format suitable for the target system. Transformations involve cleansing, standardizing, enriching, and aggregating data. This may involve data type conversions, format changes, and the application of business rules.
- Data Loading: This stage loads the transformed data into the target system. This process must be optimized to ensure data integrity and minimize downtime. The loading method, such as bulk loading or row-by-row loading, depends on the target system and the size of the dataset.
- Data Validation: Post-loading validation checks the accuracy and completeness of the migrated data. This ensures that the data in the target system matches the data in the source system after transformation and loading. This typically involves data reconciliation and the generation of reports.
Comparison of ETL Tools for Migration Factories
Choosing the right ETL tool is crucial for the success of a migration factory. The following table compares several popular ETL tools, considering their suitability for large-scale migrations.
| Feature | Informatica PowerCenter | AWS Glue | Microsoft SQL Server Integration Services (SSIS) | Apache NiFi |
|---|---|---|---|---|
| Deployment | On-Premise, Cloud, Hybrid | Cloud (AWS) | On-Premise, Cloud (Azure) | On-Premise, Cloud |
| Scalability | Highly scalable, designed for large datasets | Scalable, serverless, automatically scales based on workload | Scalable, can handle moderate to large datasets | Scalable, distributed architecture, suitable for high-volume data streams |
| Ease of Use | Steep learning curve, powerful features | Relatively easy to use, with a visual interface | Moderate learning curve, good integration with Microsoft ecosystem | Steep learning curve, visual data flow based on Apache Kafka |
| Connectivity | Extensive connectivity options to various data sources and targets | Connects to various AWS services, databases, and data lakes | Good connectivity to Microsoft data sources, and others through third-party connectors | Supports a wide variety of protocols and formats, excellent for streaming data |
| Cost | Subscription-based licensing, can be expensive | Pay-as-you-go, cost-effective for cloud-based migrations | Included with SQL Server license, cost-effective for Microsoft-centric environments | Open-source, free to use, but may require investment in infrastructure and expertise |
| Use Cases | Complex data migrations, data warehousing, data integration | Data lake migrations, ETL pipelines for AWS data services | On-premise data migrations, data integration within Microsoft environments | Real-time data streaming, IoT data processing, complex data flows |
Data Transformation Techniques in Large-Scale Migrations
Data transformation is critical for adapting data from source systems to the requirements of the target systems. Several transformation techniques are frequently used in large-scale migrations.
- Data Cleansing: This involves correcting or removing inaccurate, incomplete, or inconsistent data. This can include standardizing address formats, removing duplicate records, and correcting data entry errors.
- Data Standardization: This ensures that data values conform to a consistent format or set of rules. For example, standardizing date formats, currency codes, and naming conventions.
- Data Conversion: This involves changing data types or formats to align with the target system’s requirements. For instance, converting data types such as text to numbers or vice versa.
- Data Enrichment: This adds extra information to the data, such as looking up missing values or appending additional information from external sources. For example, adding customer demographic data based on a customer ID.
- Data Aggregation: This involves summarizing data, for example, calculating the total sales per month from daily sales records. This is often done to optimize the size of the dataset and improve query performance in the target system.
- Data Masking/Anonymization: This is a crucial step to protect sensitive data. It involves replacing sensitive data with fake data to protect privacy and compliance. Examples include replacing names with aliases, obfuscating credit card numbers, or encrypting social security numbers.
Automation and Orchestration Strategies
The successful execution of a migration factory approach hinges on the effective implementation of automation and orchestration. Manual processes, while sometimes necessary for initial setup or exceptional cases, are inherently inefficient, prone to errors, and cannot scale to meet the demands of large-scale migrations. This section delves into the critical role of automation and orchestration in streamlining the migration process, improving efficiency, and reducing risks.
Importance of Automation in a Migration Factory
Automation is a cornerstone of the migration factory model. It allows for repeatable, predictable, and scalable execution of migration tasks. The benefits of automation extend beyond mere efficiency gains, significantly impacting the overall success of the migration.
- Reduced Human Error: Automation minimizes the potential for human error in repetitive tasks, such as data extraction, transformation, and loading. This leads to improved data quality and reduced risk of data corruption. For instance, automated scripts can consistently apply data cleansing rules, whereas manual application is susceptible to inconsistencies.
- Increased Speed and Efficiency: Automated processes can execute tasks much faster than manual methods. This acceleration is particularly crucial in large-scale migrations where time is of the essence. Consider the difference between manually copying files versus using a script to replicate thousands of files simultaneously; the speed differential is exponential.
- Improved Scalability: Automation allows the migration factory to scale its operations to handle increasing volumes of data and more complex migrations. Manual processes struggle to keep pace with growing demands. With automation, resources can be allocated dynamically based on workload.
- Cost Reduction: Automating repetitive tasks frees up human resources to focus on more strategic and complex aspects of the migration, reducing labor costs and improving resource utilization. This shift allows teams to concentrate on exception handling, architecture design, and business rule definition.
- Enhanced Consistency: Automated processes ensure that all migration tasks are performed consistently across the entire dataset. This consistency is critical for maintaining data integrity and ensuring a smooth transition.
- Improved Auditability: Automated processes can be easily tracked and audited, providing a clear record of all migration activities. This enhanced auditability is crucial for compliance and troubleshooting. Every step is logged, creating a complete audit trail.
Strategies for Automating the Migration Process
Several strategies can be employed to automate various stages of the migration process. These strategies should be carefully selected and implemented to optimize the efficiency and effectiveness of the migration factory.
- Scripting: Scripting languages like Python, PowerShell, or Bash can automate repetitive tasks such as data extraction, data transformation, and data loading. Scripts can be designed to perform specific actions, such as data validation, data cleansing, and data mapping.
- Workflow Automation Tools: Tools like Apache Airflow, Jenkins, or Azure Data Factory can orchestrate complex migration workflows. These tools allow for the creation of automated pipelines that manage the sequence of tasks, dependencies, and error handling.
- Configuration Management: Configuration management tools, such as Ansible, Puppet, or Chef, can be used to automate the configuration of servers and environments involved in the migration process. This ensures consistency across all environments.
- API Integration: Utilizing APIs to interact with source and target systems enables automated data transfer and synchronization. This is especially relevant when dealing with cloud-based systems. For example, using the API of a cloud storage service to automate the data upload process.
- Testing Automation: Automated testing is critical to validate the migrated data and ensure its integrity. Tools like Selenium or custom testing scripts can automate data validation and comparison between source and target systems.
- Monitoring and Alerting: Implementing automated monitoring and alerting systems is essential for detecting and responding to issues during the migration process. Monitoring tools can track the progress of migration tasks and alert administrators to potential problems.
Integration of Orchestration Tools into a Migration Factory Workflow
Orchestration tools play a vital role in managing the complexities of a migration factory workflow. They provide a centralized platform for defining, scheduling, monitoring, and managing the various tasks involved in the migration process.
- Workflow Definition: Orchestration tools allow for the definition of complex workflows that represent the entire migration process. These workflows can be visualized and managed in a graphical user interface.
- Task Scheduling: Tasks within the workflow can be scheduled to run automatically at specific times or based on triggers. This ensures that tasks are executed in the correct order and at the appropriate time.
- Dependency Management: Orchestration tools handle dependencies between tasks, ensuring that tasks are executed in the correct order. This prevents errors and ensures that all prerequisites are met before a task begins.
- Error Handling and Recovery: Orchestration tools provide mechanisms for handling errors and automatically recovering from failures. This minimizes downtime and ensures that the migration process continues smoothly.
- Monitoring and Logging: Orchestration tools provide comprehensive monitoring and logging capabilities, allowing for the tracking of the progress of each task and the identification of any issues.
- Integration with Other Tools: Orchestration tools can integrate with other automation tools, such as scripting languages and configuration management tools, to create a fully automated migration factory workflow.
Testing and Validation Procedures
Testing and validation are critical phases in the migration factory approach, ensuring the integrity and accuracy of the migrated data. Rigorous testing minimizes the risk of data loss, corruption, or inconsistencies, which could lead to operational disruptions and compromised decision-making. A well-defined testing strategy, incorporating various validation techniques, is essential for a successful migration.
Testing Procedures for Validating Migrated Data
The validation of migrated data involves a multi-faceted approach, encompassing different testing levels to ensure data quality and system functionality. This includes unit testing, integration testing, system testing, and user acceptance testing (UAT).
- Unit Testing: Focuses on individual components or modules of the migration process, such as data extraction scripts, transformation logic, and data loading routines. This testing validates that each component functions correctly in isolation. For example, a unit test might verify that a specific data transformation function correctly converts a date format from `YYYY-MM-DD` to `MM/DD/YYYY`.
- Integration Testing: Evaluates the interaction between different components of the migration pipeline. It ensures that data flows seamlessly between the extraction, transformation, and loading stages. For instance, integration tests would check that the output of a data extraction script is correctly passed as input to a transformation script.
- System Testing: Assesses the entire migration system as a whole, simulating real-world scenarios and data volumes. It validates the end-to-end migration process, including performance, scalability, and security. System testing would involve migrating a representative dataset and verifying that the data is accurately loaded into the target system within the expected time frame and resource constraints.
- User Acceptance Testing (UAT): Conducted by business users to validate that the migrated data meets their specific requirements and that the target system functions as expected. UAT involves users performing their daily tasks using the migrated data and providing feedback on its accuracy, completeness, and usability. For example, users would verify that reports generated from the migrated data are accurate and that the system supports their business processes.
Data Reconciliation Techniques
Data reconciliation is a critical process for verifying the accuracy and completeness of migrated data. It involves comparing data between the source and target systems to identify discrepancies. Various techniques can be employed for effective data reconciliation.
- Data Profiling: Involves analyzing the source data to understand its structure, quality, and characteristics. This information is then used to define validation rules and identify potential data quality issues. Data profiling can reveal inconsistencies in data types, missing values, and format errors. For instance, profiling might reveal that a `phone number` field in the source system contains invalid characters or missing values.
- Data Comparison: Comparing data between the source and target systems at different levels of granularity, such as record counts, aggregate values (e.g., sums, averages), and individual data points. This can be achieved through SQL queries, data comparison tools, or custom scripts. For example, a data comparison might verify that the total number of customer records in the source system matches the total number of customer records in the target system.
- Checksum Verification: Calculating checksums or hash values for data sets or individual records in both the source and target systems. These checksums are then compared to ensure data integrity. This technique is particularly useful for detecting data corruption during the migration process. A common checksum algorithm is MD5 or SHA-256.
- Sampling and Auditing: Selecting a random sample of records and manually comparing their values in the source and target systems. This can be combined with automated auditing processes to track data changes and identify potential issues. For example, a sample of customer records could be manually reviewed to verify that all relevant fields, such as name, address, and contact information, have been migrated accurately.
- Data Lineage Tracking: Maintaining a record of the data’s journey through the migration pipeline, from source to target. This helps to trace data transformations and identify the root cause of any discrepancies. Data lineage can be tracked using metadata management tools or custom logging mechanisms.
Procedure for Establishing a Robust Testing and Validation Framework
Establishing a robust testing and validation framework requires a systematic approach, encompassing planning, execution, and continuous improvement. The following procedure Artikels the key steps.
- Define Testing Objectives and Scope: Clearly define the objectives of the testing and validation process, including the specific data elements, data quality rules, and system functionalities to be tested. Determine the scope of the testing, including the data volumes, test environments, and timelines.
- Develop a Test Plan: Create a detailed test plan that Artikels the testing strategy, test cases, test data, and expected results. The test plan should specify the different testing levels (unit, integration, system, UAT), the testing methodologies, and the roles and responsibilities of the testing team.
- Design Test Cases: Design comprehensive test cases that cover various scenarios, including positive and negative test cases. Test cases should be based on the data quality rules, business requirements, and system functionalities. Test cases should include clear input data, expected outputs, and pass/fail criteria.
- Prepare Test Data: Prepare realistic and representative test data that covers all data types, data ranges, and data quality scenarios. Test data should include both valid and invalid data to test the system’s ability to handle different data conditions. Consider using anonymized or masked data for sensitive information.
- Execute Test Cases: Execute the test cases in the designated test environments, following the test plan. Document the test results, including any defects or discrepancies found. Use automated testing tools to streamline the testing process and improve efficiency.
- Analyze Test Results and Report Defects: Analyze the test results to identify any data quality issues, system errors, or functional defects. Report any defects to the development team for resolution. Provide detailed information about the defects, including the steps to reproduce them, the expected results, and the actual results.
- Remediate Defects and Retest: The development team resolves the reported defects. Retest the affected components or systems to ensure that the defects have been fixed and that the fixes have not introduced any new issues.
- Perform Data Reconciliation: Conduct data reconciliation activities to verify the accuracy and completeness of the migrated data. Compare data between the source and target systems using the techniques described above.
- Obtain User Acceptance: Obtain user acceptance of the migrated data and system functionality. Conduct UAT with business users to ensure that the migrated data meets their requirements and that the system supports their business processes.
- Monitor and Improve: Continuously monitor the data quality and system performance after the migration. Use the feedback from users and the results of data reconciliation to identify areas for improvement. Refine the testing and validation framework based on the lessons learned from the migration.
Governance and Control Mechanisms
The success of a migration factory hinges not only on technical proficiency but also on robust governance and control mechanisms. These mechanisms are essential for maintaining project integrity, ensuring compliance, mitigating risks, and providing auditable trails throughout the migration lifecycle. Effective governance fosters transparency, accountability, and consistency, leading to more predictable and successful outcomes.
Identifying Governance and Control Mechanisms
Establishing effective governance requires a multi-faceted approach, encompassing various controls to manage different aspects of the migration process. These controls are not isolated; they interrelate and reinforce each other, creating a comprehensive framework.
- Project Management Office (PMO) Oversight: A central PMO provides overall direction, sets standards, and monitors progress. The PMO is responsible for:
- Defining and enforcing project methodologies (e.g., Agile, Waterfall).
- Tracking key performance indicators (KPIs) such as migration speed, data accuracy, and cost efficiency.
- Managing risks and issues, ensuring timely resolution and escalation when necessary.
- Change Management Procedures: Formal change management processes are crucial for controlling modifications to the migration factory, the data, and the target systems. All changes, from code updates to configuration adjustments, must be:
- Documented with clear justification.
- Assessed for impact on existing processes and data.
- Approved by authorized personnel.
- Thoroughly tested before implementation.
- Data Governance Framework: A data governance framework defines data ownership, data quality standards, and data access controls. This framework ensures:
- Data integrity and consistency throughout the migration.
- Compliance with relevant regulations (e.g., GDPR, HIPAA).
- Secure handling and protection of sensitive data.
- Access Control and Authorization: Implementing strict access controls is vital to prevent unauthorized access to migration tools, data, and systems. This involves:
- Role-Based Access Control (RBAC) to restrict user permissions based on their roles and responsibilities.
- Regular reviews of user access to ensure appropriateness.
- Multi-factor authentication (MFA) to enhance security.
- Configuration Management: Maintaining a well-defined configuration management process is essential to track and control the different versions of all configuration items, including software, hardware, and documentation. This process should include:
- Configuration identification and documentation.
- Version control of all configuration items.
- Configuration audits to ensure compliance with standards.
- Compliance and Regulatory Adherence: Migration projects must adhere to all relevant industry regulations and compliance standards. This includes:
- Performing risk assessments to identify and mitigate compliance risks.
- Implementing controls to protect sensitive data.
- Regular audits to ensure compliance.
Elaborating on Version Control and Change Management
Version control and change management are intrinsically linked and form the backbone of a controlled migration environment. They enable teams to track changes, revert to previous states if necessary, and ensure that all modifications are authorized and properly tested. This structured approach minimizes risks and facilitates collaboration.
- Version Control Systems: Version control systems (VCS), such as Git, are essential for managing code, configuration files, and documentation. Key benefits include:
- Tracking Changes: VCS meticulously records every modification made to files, along with who made the change and when.
- Collaboration: Multiple developers can work concurrently on different aspects of the migration factory without conflicting with each other.
- Branching and Merging: Features like branching allow developers to experiment with changes in isolated environments and merge them back into the main codebase when ready.
- Rollback Capabilities: Should a change introduce errors, the system allows for easy reversion to a previous, stable version.
Example: Consider a migration project where a transformation script is modified. Using Git, developers can create a new branch for the changes, test them thoroughly, and then merge the tested version back into the main branch. This approach reduces the risk of impacting the running migration processes.
- Change Management Process: A formal change management process ensures that all changes are properly reviewed, approved, and tested. This process typically involves:
- Change Request Submission: Initiated by a user or team to document the required change.
- Impact Assessment: Analyzing the potential effects of the change on the migration process, data, and systems.
- Approval: Authorization from relevant stakeholders, such as project managers, data owners, and security teams.
- Implementation: Executing the change in a controlled manner.
- Testing: Rigorous testing to ensure the change functions as intended and does not introduce regressions.
- Documentation: Updating relevant documentation to reflect the changes.
Example: If a new data source is added, the change management process would involve a request for the new data source, impact analysis, approvals, testing of the new source and its integration, and updates to documentation that describe the new data source and its integration within the factory.
Implementing Audit Trails and Logging
Comprehensive audit trails and logging are fundamental to ensuring accountability, enabling troubleshooting, and supporting compliance requirements. They provide a chronological record of all activities within the migration factory, including user actions, system events, and data transformations.
- Logging Infrastructure: A centralized logging infrastructure collects and stores logs from various sources, including:
- Application Logs: Capturing events from migration tools, ETL processes, and other applications. These logs typically record errors, warnings, and informational messages.
- System Logs: Recording system-level events such as server starts and stops, resource usage, and security events.
- Database Logs: Tracking database activities, including data modifications, queries, and user connections.
Example: Using a centralized logging platform like the ELK stack (Elasticsearch, Logstash, Kibana) or Splunk allows for efficient collection, indexing, and analysis of logs from all components of the migration factory.
- Audit Trails: Audit trails provide a detailed record of actions performed by users, including:
- User Authentication and Authorization: Recording user logins, logouts, and access attempts.
- Data Modifications: Tracking changes to data, including who made the changes, when they were made, and the before/after values.
- Configuration Changes: Recording modifications to system configurations, including the date, time, and user responsible.
Example: For data transformations, audit trails should record the original data, the transformation logic applied, and the resulting data. This enables detailed analysis and validation of the transformation process.
- Security and Access Control: Securing the logs and audit trails is crucial to prevent unauthorized access and tampering.
- Access Control: Restricting access to logs based on user roles and permissions.
- Data Encryption: Encrypting logs to protect sensitive information.
- Integrity Checks: Implementing mechanisms to detect tampering with logs.
Example: Using encryption and secure storage solutions for logs, and implementing intrusion detection systems to monitor for unauthorized access to the logs.
- Log Analysis and Reporting: Regularly analyzing logs and generating reports is essential for identifying issues, monitoring performance, and ensuring compliance. This involves:
- Anomaly Detection: Identifying unusual patterns or events that may indicate security breaches or performance problems.
- Performance Monitoring: Analyzing logs to track the performance of migration processes, such as data throughput and processing times.
- Compliance Reporting: Generating reports to demonstrate compliance with relevant regulations and standards.
Example: Monitoring log data to identify performance bottlenecks in ETL processes or detecting failed data migrations. These insights can be used to optimize the migration processes and proactively address potential issues.
Team Roles and Responsibilities
A successful migration factory relies on a well-defined team structure, with each role contributing specialized skills and responsibilities. This organized approach ensures efficient execution, minimizes risks, and facilitates the successful transfer of data and applications. Clearly delineated roles are crucial for maintaining accountability and driving the migration process forward.
Team Composition and Responsibilities
The migration factory team typically comprises several specialized roles, each with specific responsibilities and required skill sets. These roles collaborate to execute the migration plan, from initial assessment to final validation. The team structure should be adaptable to the scale and complexity of the migration project.
- Migration Factory Lead: This role oversees the entire migration factory operation, providing strategic direction and ensuring alignment with business objectives.
- Responsibilities:
- Developing and maintaining the migration strategy and roadmap.
- Managing the migration budget and resource allocation.
- Monitoring progress and reporting on key performance indicators (KPIs).
- Identifying and mitigating risks.
- Facilitating communication and collaboration among team members and stakeholders.
- Skills Required:
- Strong leadership and project management skills.
- Excellent communication and stakeholder management abilities.
- Deep understanding of the business and its IT landscape.
- Experience with large-scale migration projects.
- Financial acumen and budget management skills.
- Solution Architect: The Solution Architect designs the overall migration architecture, ensuring it meets the technical and business requirements.
- Responsibilities:
- Defining the target state architecture and migration patterns.
- Selecting appropriate migration tools and technologies.
- Ensuring the solution meets performance, security, and compliance requirements.
- Providing technical guidance and support to the migration team.
- Creating and maintaining technical documentation.
- Skills Required:
- Expert-level knowledge of cloud platforms, on-premise infrastructure, and migration technologies.
- Strong architectural design and system integration skills.
- Experience with data migration and application modernization.
- Excellent problem-solving and analytical abilities.
- Ability to translate business requirements into technical solutions.
- Data Migration Engineer: This role focuses on the extraction, transformation, and loading (ETL) of data, ensuring data integrity and consistency throughout the migration process.
- Responsibilities:
- Developing and implementing ETL processes.
- Performing data profiling and data quality checks.
- Troubleshooting data migration issues.
- Optimizing ETL performance.
- Creating and maintaining data migration scripts and documentation.
- Skills Required:
- Expertise in ETL tools and techniques (e.g., Informatica, Talend, Apache NiFi).
- Strong understanding of database technologies and data modeling.
- Experience with data quality and data governance principles.
- Proficiency in scripting languages (e.g., Python, SQL).
- Excellent data analysis and problem-solving skills.
- Application Migration Engineer: This role focuses on migrating applications, including code, configurations, and dependencies.
- Responsibilities:
- Assessing application compatibility with the target environment.
- Migrating application code and configurations.
- Testing and validating application functionality.
- Troubleshooting application migration issues.
- Creating and maintaining application migration documentation.
- Skills Required:
- Experience with application migration tools and techniques.
- Strong understanding of application architectures and deployment models.
- Proficiency in scripting languages and automation tools.
- Knowledge of cloud platforms and application modernization strategies.
- Excellent problem-solving and troubleshooting skills.
- Automation Engineer: The Automation Engineer designs and implements automation strategies to streamline the migration process, improve efficiency, and reduce errors.
- Responsibilities:
- Developing and implementing automation scripts and workflows.
- Automating repetitive tasks, such as environment provisioning and testing.
- Monitoring and optimizing automation processes.
- Integrating automation tools with other migration components.
- Creating and maintaining automation documentation.
- Skills Required:
- Proficiency in scripting languages (e.g., Python, PowerShell).
- Experience with automation tools (e.g., Ansible, Terraform, Jenkins).
- Strong understanding of infrastructure-as-code (IaC) principles.
- Knowledge of cloud platforms and automation best practices.
- Excellent problem-solving and analytical skills.
- Testing and Validation Engineer: This role is responsible for testing and validating the migrated data and applications to ensure they meet the required quality standards.
- Responsibilities:
- Developing and executing test plans and test cases.
- Performing data validation and functional testing.
- Identifying and reporting defects.
- Tracking and resolving testing issues.
- Creating and maintaining testing documentation.
- Skills Required:
- Experience with testing methodologies and tools (e.g., Selenium, JUnit).
- Strong understanding of data validation techniques.
- Knowledge of software development life cycle (SDLC) and testing best practices.
- Excellent analytical and problem-solving skills.
- Ability to create and execute test plans.
- Governance and Compliance Officer: This role ensures that the migration process adheres to all relevant regulatory requirements and internal policies.
- Responsibilities:
- Ensuring compliance with data privacy regulations (e.g., GDPR, CCPA).
- Implementing security controls and best practices.
- Managing access controls and data security.
- Conducting regular audits and risk assessments.
- Creating and maintaining governance documentation.
- Skills Required:
- In-depth knowledge of data privacy regulations and security standards.
- Experience with security tools and technologies.
- Strong understanding of risk management principles.
- Excellent communication and documentation skills.
- Ability to ensure compliance and maintain security.
Case Studies and Real-World Examples
The migration factory approach, while theoretically sound, demonstrates its true value through practical application. Examining real-world case studies offers insights into the challenges, solutions, and quantifiable benefits of implementing this methodology. This section presents several examples of successful migration factory implementations, analyzing the specific problems addressed and the strategies employed.
Financial Services Company: Legacy System Modernization
A major financial services institution embarked on a multi-year project to modernize its core banking systems, transitioning from a monolithic mainframe environment to a cloud-based microservices architecture. This initiative involved migrating millions of customer records, financial transactions, and critical business applications.
- Challenge: The legacy system was characterized by complex dependencies, proprietary technologies, and limited documentation. The migration faced significant risks, including data loss, service disruption, and compliance violations. The sheer scale of the data and the intricate nature of the existing system presented a formidable obstacle.
- Migration Factory Solution: A migration factory was established, comprising specialized teams focused on data extraction, transformation, and loading (ETL), application refactoring, and testing.
- Data Migration Strategy: The data migration process involved several key steps:
- Data Profiling and Analysis: Comprehensive data profiling identified data quality issues and mapping complexities.
- ETL Pipeline Development: Automated ETL pipelines were built using industry-standard tools, designed to handle large volumes of data.
- Data Validation and Reconciliation: Rigorous data validation processes ensured data integrity and consistency.
- Application Migration Strategy: Applications were refactored and re-architected to align with the microservices architecture. This involved breaking down monolithic applications into smaller, independently deployable services.
- Automation and Orchestration: Automation tools were used extensively to streamline the migration process, including infrastructure provisioning, code deployment, and testing.
- Testing and Validation: Extensive testing, including unit tests, integration tests, and user acceptance testing (UAT), was conducted to ensure the migrated systems functioned correctly.
- Results: The implementation of the migration factory approach resulted in a significant reduction in migration time and cost. The project was completed within the estimated budget and timeline, with minimal disruption to business operations. The modernized systems offered improved scalability, performance, and agility. The financial institution experienced a 40% reduction in operational costs associated with its legacy systems and a 25% improvement in application deployment frequency.
Retail Company: E-commerce Platform Migration
A large retail company sought to migrate its e-commerce platform to a new, more scalable and feature-rich platform to enhance customer experience and improve business agility. The migration involved moving a vast product catalog, customer data, and order history.
- Challenge: The existing e-commerce platform suffered from performance limitations and lacked the flexibility to support new features and integrations. The migration process had to be executed with minimal downtime to avoid revenue loss. The data volume was substantial, and data consistency was critical for customer satisfaction and order fulfillment.
- Migration Factory Solution: A migration factory was established, focusing on data migration, application refactoring, and platform integration. The migration factory employed a phased approach to minimize risk and ensure business continuity.
- Data Migration Strategy: The data migration process involved:
- Data Extraction: Data was extracted from the existing platform using a combination of custom scripts and third-party tools.
- Data Transformation: Data was transformed to match the schema of the new platform, addressing data quality issues and inconsistencies.
- Data Loading: Data was loaded into the new platform using optimized loading techniques to ensure performance.
- Application Migration Strategy: Applications were refactored to integrate with the new platform’s APIs and services.
- Automation and Orchestration: Automated testing and deployment pipelines were used to accelerate the migration process.
- Testing and Validation: Rigorous testing, including performance testing, security testing, and UAT, was conducted to ensure the migrated platform functioned correctly.
- Results: The implementation of the migration factory approach resulted in a successful platform migration with minimal downtime. The new platform offered improved performance, scalability, and features. The retail company saw a 30% increase in website traffic, a 20% increase in online sales, and a 15% reduction in customer support costs.
Healthcare Provider: Electronic Health Record (EHR) System Migration
A healthcare provider decided to migrate its EHR system to a new platform to improve patient care and streamline administrative processes. The migration involved transferring patient records, medical history, and other sensitive data.
- Challenge: The migration of sensitive patient data required strict adherence to regulatory compliance, including HIPAA. Data security and integrity were paramount concerns. The healthcare provider needed to minimize disruption to patient care.
- Migration Factory Solution: A migration factory was established, with a strong focus on data security, compliance, and data validation.
- Data Migration Strategy:
- Data Encryption: Data was encrypted during transit and at rest to protect patient privacy.
- Data Masking: Sensitive data was masked during testing and development to prevent unauthorized access.
- Data Validation: Comprehensive data validation processes ensured data accuracy and completeness.
- Application Migration Strategy: Application refactoring focused on integrating with the new platform’s APIs and security protocols.
- Automation and Orchestration: Automated testing and deployment pipelines were implemented to ensure data integrity and compliance.
- Testing and Validation: Testing was conducted to validate data accuracy, compliance, and system functionality.
- Results: The implementation of the migration factory approach resulted in a secure and compliant EHR system migration. The healthcare provider experienced improved data access, streamlined workflows, and enhanced patient care. There was a 20% reduction in administrative costs and a 10% improvement in patient satisfaction scores.
Concluding Remarks
In conclusion, the migration factory approach offers a robust and scalable solution for navigating the complexities of large-scale data migrations. By embracing automation, standardization, and a meticulous focus on planning and execution, organizations can significantly mitigate risks, reduce costs, and accelerate the transition to new systems. The insights gained from this examination underscore the transformative potential of the migration factory approach, empowering organizations to approach data migrations with confidence and precision, ensuring a smooth and efficient data transfer process.
User Queries
What are the primary benefits of using a migration factory approach?
The primary benefits include reduced migration time, minimized errors, lower costs through automation, improved data quality, and enhanced scalability for handling large datasets.
How does automation contribute to the success of a migration factory?
Automation streamlines repetitive tasks, reduces manual errors, accelerates the migration process, and allows for consistent execution across multiple data sets, making the overall process more efficient.
What is the role of data profiling in a migration factory?
Data profiling is essential for understanding the source data, identifying data quality issues, and informing the transformation and mapping processes, ensuring data integrity during migration.
How are testing and validation handled in a migration factory?
Testing involves rigorous procedures, including data comparison, reconciliation, and validation against predefined criteria to ensure data accuracy and completeness after migration.