What is distributed tracing for serverless applications? It’s the art of following a request’s journey through the intricate web of interconnected serverless functions, like a detective piecing together clues. In the dynamic world of serverless computing, where applications are built from numerous, independently operating functions, understanding how these functions interact is crucial for performance and reliability.
Distributed tracing offers a powerful lens to observe these interactions. It captures the flow of requests across various services, enabling developers to pinpoint bottlenecks, identify performance issues, and gain a deeper understanding of application behavior. By meticulously documenting each step of a request’s lifecycle, distributed tracing transforms the often-opaque nature of serverless applications into a transparent and manageable system.
Defining Distributed Tracing
Distributed tracing is crucial for understanding the behavior of serverless applications, offering a powerful method for debugging and optimizing complex, event-driven architectures. It allows developers to follow the flow of a request as it traverses multiple services and functions, providing a holistic view of the application’s performance.
Fundamental Concept of Distributed Tracing
Distributed tracing, in the context of serverless applications, provides a mechanism to track a single request as it propagates through a distributed system composed of independent, often short-lived, functions. Serverless applications are inherently distributed, meaning that a single user request is likely to trigger a chain of function executions across different cloud providers or within the same provider’s infrastructure. Without distributed tracing, debugging such applications can be incredibly difficult, as errors or performance bottlenecks may be hidden within the interactions between these functions.
Defining a “Trace” and Its Components
A “trace” is a record of the journey of a request as it moves through a distributed system. It captures the sequence of operations performed by different services or functions in response to that request. A trace is composed of several key components:
- Spans: Spans represent individual units of work or operations performed by a service or function. Each span captures information such as the operation’s name, start and end timestamps, any relevant metadata (e.g., function name, request parameters, return codes), and links to parent and child spans. Think of a span as a single function call or a specific operation, like querying a database or calling another API.
- Context Propagation: Context propagation is the mechanism by which tracing information (e.g., trace IDs, span IDs) is passed between different services or functions. This is typically achieved through the use of HTTP headers or other mechanisms that allow the tracing system to correlate spans across service boundaries. This ensures that when a function calls another function, the trace information is automatically passed along.
- Trace ID: The Trace ID uniquely identifies a specific request as it flows through the system. All spans related to a particular request share the same Trace ID, allowing them to be linked together.
- Span ID: Each span within a trace has a unique Span ID. This identifies a specific operation within a service or function.
- Parent Span ID: This field indicates the ID of the span that initiated the current span. It’s how spans are linked together to show the call hierarchy.
Differences from Traditional Application Monitoring
Distributed tracing differs significantly from traditional application monitoring, particularly in its focus on request-level visibility across distributed systems. Traditional monitoring often focuses on aggregate metrics and alerts, such as CPU usage, memory consumption, and error rates. While these metrics are still important, they lack the granularity to pinpoint the root cause of performance issues or errors in a distributed environment.
- Scope of Observation: Traditional monitoring typically observes individual services or components in isolation. Distributed tracing, on the other hand, observes the entire request flow across multiple services and functions.
- Granularity of Data: Traditional monitoring often provides aggregated metrics (e.g., average response time). Distributed tracing provides detailed, per-request information, including the timing of individual operations and the relationships between them.
- Root Cause Analysis: Traditional monitoring can help identify that a problem exists, but it may not provide enough information to quickly determine the root cause. Distributed tracing allows developers to follow a request’s path, identifying the specific service or function that is causing the issue.
- Complexity: Traditional monitoring is often easier to implement in monolithic applications. Distributed tracing requires more sophisticated instrumentation and context propagation mechanisms to track requests across distributed boundaries.
Why is Distributed Tracing Important for Serverless?
Serverless architectures, with their inherent complexity and distributed nature, present unique challenges for monitoring and troubleshooting. Traditional monitoring approaches, often designed for monolithic applications, fall short in providing adequate visibility into the intricate interactions between serverless functions and services. Distributed tracing emerges as a critical tool, offering a comprehensive understanding of request flows and performance characteristics within these dynamic environments.
This enables developers to effectively diagnose issues, optimize application performance, and ensure the reliability of serverless applications.
Challenges of Monitoring Serverless Applications Without Distributed Tracing
Monitoring serverless applications without distributed tracing is significantly hampered by the ephemeral nature of function executions and the distributed nature of service interactions. Traditional monitoring tools, which rely on centralized logging and monitoring, struggle to correlate events across multiple function invocations and services.
- Lack of End-to-End Visibility: Without distributed tracing, it is difficult to track a single request as it traverses multiple serverless functions, APIs, and external services. Each function execution generates its own logs, which are often siloed, making it challenging to reconstruct the complete path of a request and identify bottlenecks or errors. Consider a scenario where a user request triggers several functions: a function to process the request, a function to query a database, and a function to send a notification.
Without tracing, identifying the root cause of a slow response time, for example, requires manually correlating logs from each function, a time-consuming and error-prone process.
- Difficulty in Identifying Root Causes: When issues arise, pinpointing the exact function or service responsible becomes a complex task. Simple logging provides limited context, making it hard to understand the sequence of events leading to a failure. For example, a database query might be slow, but without tracing, it is difficult to determine which function initiated the query and what other operations were happening concurrently.
This lack of visibility leads to longer mean time to resolution (MTTR) and increased operational overhead.
- Challenges in Performance Optimization: Serverless applications often involve complex interactions between functions and external services. Without distributed tracing, identifying performance bottlenecks becomes extremely difficult. Developers may not be able to easily determine which function is taking the longest to execute or which external service is causing delays. This hinders effective performance optimization efforts, leading to inefficient resource utilization and potentially impacting user experience.
For example, if a function is repeatedly invoking an external API that is slow, this can be detected using tracing.
Advantages of Distributed Tracing Over Simple Logging for Troubleshooting Serverless Issues
Distributed tracing offers several advantages over simple logging in troubleshooting serverless applications, providing a more comprehensive and efficient approach to issue resolution. Tracing enables a deeper understanding of request flows, facilitates faster root cause analysis, and supports proactive performance optimization.
- Improved Correlation of Events: Distributed tracing automatically correlates events across multiple functions and services, providing a unified view of a request’s lifecycle. Each function execution, API call, and database interaction is tagged with a trace ID, enabling the tracing system to link related events together. This allows developers to easily reconstruct the path of a request and understand the sequence of events leading to an issue.
- Enhanced Root Cause Analysis: Distributed tracing provides detailed information about each component involved in a request, including execution times, errors, and dependencies. This allows developers to quickly identify the root cause of issues by pinpointing the specific function or service that is experiencing problems. For example, if a request is failing, tracing can show which function is throwing an error and the specific line of code that is causing the problem.
- Reduced Mean Time to Resolution (MTTR): By providing a clear and comprehensive view of request flows and performance metrics, distributed tracing significantly reduces the time required to diagnose and resolve issues. Developers can quickly identify the source of problems, understand the impact of different components, and implement effective solutions. This leads to faster issue resolution and improved application reliability.
- Better Performance Monitoring: Distributed tracing provides insights into the performance of individual functions and services, as well as the overall application. Developers can use tracing data to identify performance bottlenecks, optimize resource utilization, and improve the user experience. For example, tracing can show which functions are taking the longest to execute, which external services are slow, and how different components are interacting.
How Distributed Tracing Improves Debugging and Performance Optimization in Serverless Environments
Distributed tracing significantly enhances debugging and performance optimization in serverless environments by providing a wealth of information about request flows, performance metrics, and dependencies. This enables developers to gain deeper insights into application behavior, identify performance bottlenecks, and implement effective optimizations.
- Detailed Request Flow Visualization: Distributed tracing visualizes the complete path of a request as it traverses multiple functions and services. This allows developers to easily understand the sequence of events, identify dependencies, and pinpoint the specific components involved in a request. The visualization often includes timelines showing the duration of each operation, helping to quickly identify slow functions or external services.
- Performance Bottleneck Identification: Tracing data provides detailed performance metrics for each function and service, including execution times, latency, and resource utilization. This enables developers to easily identify performance bottlenecks, such as slow database queries or inefficient function implementations. For example, tracing can show that a particular function is consistently taking longer than expected, prompting developers to investigate its code or dependencies.
- Code-Level Profiling: Some distributed tracing systems provide code-level profiling capabilities, allowing developers to drill down into the specific lines of code that are causing performance issues. This helps to identify inefficient algorithms, excessive resource consumption, or other code-related problems. This can involve tracing the execution of individual lines of code within a function, providing detailed timing information.
- Dependency Analysis: Distributed tracing helps to understand the dependencies between different functions and services. This allows developers to identify potential risks, such as cascading failures, where a failure in one service can impact other services. By understanding these dependencies, developers can design more resilient and fault-tolerant architectures.
- Example: Optimizing a Serverless E-commerce Application: Imagine an e-commerce application built on serverless functions. A user clicks the “Add to Cart” button, which triggers a series of functions: one to update the cart in the database, another to calculate the total price, and a third to send a confirmation email. Without tracing, debugging a slow “Add to Cart” process would be difficult. With distributed tracing, the developer can see the entire request flow.
If the cart update function is slow, tracing might show that the database query is inefficient. The developer can then optimize the query, significantly improving the user experience.
Key Components of Distributed Tracing Systems

Distributed tracing systems are crucial for understanding and debugging complex serverless applications. These systems provide insights into the flow of requests across multiple services and functions, allowing developers to pinpoint performance bottlenecks and identify errors. The following sections detail the essential components that make up a robust distributed tracing solution.
Essential Components of a Distributed Tracing System
A distributed tracing system comprises several key components that work together to collect, process, and visualize trace data. Understanding each component is vital for effective implementation and utilization.
- Tracers: Tracers are libraries or agents that instrument the code within each service or function. They generate spans, which represent individual units of work. The tracer captures metadata about these operations, such as the start and end times, the service name, and any relevant tags or attributes. Examples of tracers include OpenTelemetry SDKs, Jaeger clients, and Zipkin instrumentation libraries.
These tracers are integrated directly into the application code to capture trace information.
- Collectors: Collectors are responsible for receiving spans from the tracers. They aggregate and process the spans, typically transforming them into traces. The collector also validates and enriches the data, often adding timestamps, service names, and other contextual information. Examples include Jaeger collectors, Zipkin collectors, and OpenTelemetry collectors. The collector’s primary function is to centralize the tracing data.
- Storage: The storage component persists the trace data for later analysis and retrieval. This storage can be a time-series database, a key-value store, or a specialized tracing backend. The choice of storage depends on factors such as the volume of data, the required query performance, and the specific analysis needs. Examples include Cassandra, Elasticsearch, and cloud-based tracing services like AWS X-Ray and Google Cloud Trace.
Storage solutions are designed to handle the high volume of trace data generated.
- User Interface (UI): The UI provides a means for users to visualize and analyze the trace data. It allows developers to search for traces, view service dependencies, and identify performance bottlenecks. The UI typically presents traces as directed acyclic graphs (DAGs), which visually represent the flow of requests across services. Popular UI examples include the Jaeger UI, the Zipkin UI, and the dashboards provided by cloud-based tracing services.
The UI makes the trace data accessible and understandable.
The Role of a Span and its Attributes
A span is the fundamental unit of work in a distributed tracing system. It represents a single operation within a service, such as handling an HTTP request, querying a database, or calling another service. Spans contain a wealth of information that allows developers to understand the behavior of their applications.
- Span Attributes: Spans are characterized by a set of attributes, which provide context about the operation. These attributes can include:
- Start and End Times: Indicate the duration of the operation.
- Service Name: Identifies the service where the span originated.
- Operation Name: Describes the specific operation being performed (e.g., “GET /users”).
- Span ID: A unique identifier for the span.
- Trace ID: A unique identifier for the entire trace, linking all spans related to a single request.
- Parent Span ID: Identifies the parent span, indicating the relationship between spans.
- Tags/Annotations: Key-value pairs that provide additional context, such as HTTP status codes, database queries, and error messages.
- Span Context: Span context is the information that propagates across service boundaries. It typically includes the Trace ID, Span ID, and any relevant baggage (user-defined data). This context enables the correlation of spans across different services. The span context is often propagated via HTTP headers or other mechanisms.
- Span Relationships: Spans are related to each other through parent-child relationships. This relationship forms the trace, which represents the complete flow of a request through the application. The parent span represents the caller, and the child span represents the operation performed by the called service.
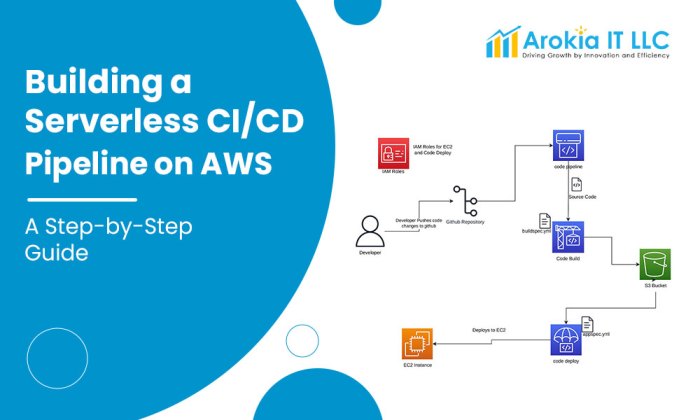
Trace Flow Diagram in a Serverless Application
The following diagram illustrates the flow of a trace through a simplified serverless application. The diagram highlights the key components and how they interact to capture and visualize trace data.
Diagram Description:
The diagram illustrates the flow of a trace through a serverless application comprising three functions: Function A, Function B, and Function C. Each function is represented by a distinct box. Arrows indicate the flow of a request, and the associated spans generated by each function are shown alongside the function’s box.
- User Request: A user initiates a request, triggering Function A.
- Function A: Function A receives the request and, using a tracer, creates a root span. It performs some processing and then calls Function B. The tracer adds span context to the call to Function B (e.g., via HTTP headers).
- Function B: Function B receives the request and, using a tracer, creates a child span, which is linked to the parent span in Function A. Function B then calls Function C. The tracer adds span context to the call to Function C.
- Function C: Function C receives the request and, using a tracer, creates a child span, which is linked to the parent span in Function B. Function C performs its operations and returns a response.
- Span Propagation: Each function propagates the span context (Trace ID, Span ID, and baggage) to the downstream function.
- Data Collection: Each function sends the spans to a collector.
- Collector: The collector receives spans from all functions, aggregates them into traces, and stores the traces in a storage system.
- Storage: The storage system persists the trace data for later retrieval and analysis.
- UI: A user interface (UI) accesses the stored trace data, allowing developers to visualize the trace as a directed acyclic graph (DAG). The DAG visually represents the sequence of events and their durations.
This diagram clearly shows how a single user request generates a trace that spans multiple serverless functions. Each span contains detailed information about the operation performed within each function, allowing developers to understand the performance and behavior of the application.
Implementing Tracing in Serverless Architectures
Implementing distributed tracing in serverless architectures presents unique challenges and opportunities. The ephemeral nature of serverless functions, their distributed execution across various services, and the dynamic scaling capabilities require a tailored approach to ensure effective tracing. This section delves into the practical aspects of integrating tracing into serverless environments, exploring available tools and techniques.
Popular Tracing Tools
The selection of a tracing tool is a critical decision in implementing distributed tracing. Several open-source and commercial options are available, each with its strengths and weaknesses. The choice often depends on factors such as budget, existing infrastructure, and desired features.
- Jaeger: Jaeger is a popular open-source, end-to-end distributed tracing system. It is designed to monitor and troubleshoot microservices-based distributed systems. Jaeger provides features like distributed context propagation, transaction monitoring, root cause analysis, and performance optimization. It supports various storage backends, including Cassandra, Elasticsearch, and memory storage. Jaeger’s architecture consists of a Jaeger Client (instrumentation library), Jaeger Agent (local service that batches and forwards traces), Jaeger Collector (ingests traces), and Jaeger Query (UI for visualizing traces).
Its scalability and ease of use make it a suitable option for many serverless deployments.
- Zipkin: Zipkin is another well-established open-source distributed tracing system. It originated at Twitter and has been widely adopted. Zipkin is designed to help gather timing data needed to troubleshoot latency problems in service architectures. It supports multiple instrumentation libraries and provides a user-friendly UI for trace visualization. Zipkin’s architecture is similar to Jaeger’s, involving a Collector, Storage, and UI.
It is known for its simplicity and ease of integration.
- AWS X-Ray: AWS X-Ray is a fully managed service provided by Amazon Web Services for analyzing and debugging distributed applications. It is designed to trace requests as they travel through your applications. X-Ray integrates seamlessly with various AWS services, including Lambda, API Gateway, and EC2. It offers features such as service maps, error analysis, and performance profiling. X-Ray’s integration with the AWS ecosystem makes it a compelling choice for serverless applications deployed on AWS.
The service automatically collects trace data from instrumented applications and provides tools to view and analyze the data.
- Other Commercial Tools: Several commercial vendors also offer distributed tracing solutions, such as Datadog, New Relic, and Dynatrace. These tools often provide comprehensive monitoring, logging, and tracing capabilities, along with advanced features like machine learning-based anomaly detection and performance optimization recommendations. They typically offer more advanced features and integrations but may come with higher costs.
Instrumenting Serverless Functions
Instrumenting serverless functions is the process of adding tracing code to the function’s logic. This allows the function to generate and emit trace data, which is then collected and analyzed by the tracing system. The specific instrumentation steps vary depending on the chosen tracing tool and the programming language used.
- Using Tracing Libraries: Most tracing tools provide client libraries or SDKs for various programming languages (e.g., Python, Node.js, Java). These libraries offer APIs for creating spans, adding tags and logs, and propagating trace context. Developers typically integrate these libraries into their function code to instrument key operations.
- Automatic Instrumentation: Some tools offer automatic instrumentation capabilities, particularly for specific runtimes and frameworks. For example, AWS X-Ray can automatically instrument Lambda functions using the AWS SDK. This reduces the amount of manual coding required.
- Manual Instrumentation: In cases where automatic instrumentation is not available or insufficient, developers may need to manually instrument their functions. This involves adding code to create spans at the beginning and end of function invocations, and to record relevant data, such as input parameters, output values, and error messages.
- Example (Python with Jaeger): The following Python code snippet demonstrates how to instrument an AWS Lambda function using the Jaeger client library:
from jaeger_client import Config from opentracing.ext import tags from opentracing import tracer import os def initialize_tracer(service_name): config = Config( config= 'sampler': 'type': 'const', 'param': 1, , 'logging': True, 'local_agent': 'reporting_host': os.environ.get('JAEGER_AGENT_HOST', 'localhost'), 'reporting_port': 6831, , , service_name=service_name, validate=True, ) return config.initialize_tracer() tracer = initialize_tracer('my-lambda-function') def lambda_handler(event, context): with tracer.start_span('my-lambda-function') as span: span.set_tag(tags.HTTP_METHOD, 'GET') span.set_tag(tags.HTTP_URL, '/hello') try: # Your function logic here message = "Hello, World!" span.log_kv('event': 'message', 'value': message) return 'statusCode': 200, 'body': message except Exception as e: span.set_tag(tags.ERROR, True) span.log_kv('event': 'error', 'message': str(e)) raise finally: span.finish()In this example, the `initialize_tracer` function initializes the Jaeger tracer.
The `lambda_handler` function then creates a span for the function invocation, sets tags for the HTTP method and URL, logs an event, and handles potential errors. The `span.finish()` call closes the span.
Propagating Trace Context
Trace context propagation is the mechanism by which the tracing system transmits the trace information across service boundaries. This ensures that related events across different services are linked together in a single trace. In serverless architectures, this is particularly important because requests often traverse multiple functions and services.
- Using HTTP Headers: The most common method for propagating trace context is through HTTP headers. When a serverless function calls another service (e.g., another Lambda function, an API Gateway endpoint), it includes the trace context in the HTTP request headers. The receiving service then extracts the trace context from the headers and uses it to create a new span that is linked to the parent span.
- Header Names: Specific header names are used to transmit the trace context. OpenTracing and OpenTelemetry standards define common header names, such as `traceparent` and `uber-trace-id`. AWS X-Ray uses its own header format.
- Code Example (Python with AWS Lambda and X-Ray): This example shows how to propagate trace context when one Lambda function calls another using the AWS SDK for Python (Boto3):
import boto3 import os from aws_xray_sdk.core import xray_recorder def lambda_handler(event, context): # Get the trace ID from the current segment trace_id = xray_recorder.current_segment().trace_id # Create a client for the other Lambda function lambda_client = boto3.client('lambda') # Prepare the payload for the other Lambda function payload = 'message': 'Hello from the first Lambda!', 'trace_id': trace_id # Invoke the other Lambda function response = lambda_client.invoke( FunctionName=os.environ['TARGET_FUNCTION_NAME'], InvocationType='RequestResponse', Payload=bytes(json.dumps(payload), 'utf-8'), LogType='Tail' ) # Process the response response_payload = json.loads(response['Payload'].read().decode('utf-8')) return 'statusCode': 200, 'body': json.dumps(response_payload)In the above example, the first Lambda function retrieves the `trace_id` from the current X-Ray segment and includes it in the payload passed to the second Lambda function.
The second Lambda function can then use this `trace_id` to correlate the traces.
- Example (Python with Jaeger): Here’s a simplified example of how to propagate trace context using the Jaeger client:
from jaeger_client import Config from opentracing.ext import tags from opentracing import tracer import requests import os def initialize_tracer(service_name): config = Config( config= 'sampler': 'type': 'const', 'param': 1, , 'logging': True, 'local_agent': 'reporting_host': os.environ.get('JAEGER_AGENT_HOST', 'localhost'), 'reporting_port': 6831, , , service_name=service_name, validate=True, ) return config.initialize_tracer() tracer = initialize_tracer('service-a') def call_service_b(url, headers): with tracer.start_span('call-service-b') as span: span.set_tag(tags.HTTP_URL, url) try: response = requests.get(url, headers=headers) span.set_tag(tags.HTTP_STATUS_CODE, response.status_code) return response except requests.exceptions.RequestException as e: span.set_tag(tags.ERROR, True) span.log_kv('event': 'error', 'message': str(e)) raise finally: span.finish() def lambda_handler(event, context): with tracer.start_span('service-a-handler') as span: # Extract trace context from event (if available) # Propagate trace context to downstream service headers = tracer.inject( span.context, tracer.FORMAT_HTTP_HEADERS, headers ) response = call_service_b('http://service-b.example.com', headers) return 'statusCode': 200, 'body': response.textIn this example, the `tracer.inject` function injects the current span’s context into the HTTP headers.
These headers are then included in the request to `service-b`, allowing it to continue the trace.
- Context Propagation Libraries: Some libraries simplify trace context propagation. These libraries handle the extraction and injection of trace context across different frameworks and services. OpenTelemetry provides standardized context propagation mechanisms.
- Asynchronous Context Propagation: Serverless applications often use asynchronous communication patterns (e.g., message queues). Propagating trace context in these scenarios requires special handling. The trace context must be propagated along with the message payload.
Trace Context Propagation Methods
Distributed tracing in serverless applications relies heavily on accurately propagating the trace context across various services and function invocations. This context, containing essential information like trace IDs and span IDs, enables the correlation of events and requests across the entire application lifecycle. Several methods exist to ensure this context is transmitted seamlessly, each with its own strengths and weaknesses.
HTTP Header Propagation
HTTP header propagation is a widely adopted method for passing trace context in serverless environments, particularly when services communicate via HTTP requests. This approach involves injecting trace context data into standard HTTP headers.
The primary advantage of HTTP header propagation lies in its simplicity and broad compatibility. It leverages the ubiquitous nature of HTTP, making it readily adaptable to various serverless frameworks and platforms. Most tracing libraries and frameworks natively support HTTP header injection and extraction.
However, HTTP header propagation also presents some challenges.
- Header Size Limitations: HTTP headers have size limitations, which can be a constraint if the trace context grows excessively. While this is less of a concern with modern tracing standards that prioritize efficiency, it remains a consideration.
- Security Considerations: Sensitive information within trace context, such as user identifiers or specific request details, must be carefully handled to prevent security breaches. Proper sanitization and encryption are crucial.
- Asynchronous Operations: Propagating context across asynchronous operations (e.g., message queues) requires additional mechanisms to extract and inject the context into the message payloads.
Message Queue Propagation
Message queue propagation is a common method for propagating trace context when services communicate asynchronously through message queues such as Amazon SQS, Apache Kafka, or RabbitMQ. The trace context is embedded within the message payload or metadata.
The use of message queue propagation offers several benefits.
- Asynchronous Communication: It seamlessly handles asynchronous communication patterns, enabling tracing across decoupled services.
- Scalability: Message queues are designed for scalability, making them suitable for high-volume serverless applications.
- Flexibility: This method supports various message formats, allowing for customization based on specific requirements.
Nevertheless, this method has some disadvantages.
- Implementation Complexity: Implementing message queue propagation often requires custom code to extract and inject the trace context into the message payloads.
- Message Size: Adding trace context increases message size, potentially impacting performance and cost.
- Serialization and Deserialization: The trace context must be serialized and deserialized correctly to maintain its integrity across services.
Configuring Trace Context Propagation in a Specific Serverless Framework (AWS Lambda with AWS X-Ray)
AWS X-Ray, a distributed tracing service for AWS, provides built-in support for trace context propagation in serverless applications using AWS Lambda. When a Lambda function is invoked, X-Ray automatically injects trace context into the incoming request’s headers. Subsequent invocations of other Lambda functions or calls to AWS services will inherit this context.
To configure trace context propagation:
- Enable X-Ray Tracing: Enable X-Ray tracing for your Lambda function. This can be done through the AWS Management Console, AWS CLI, or infrastructure-as-code tools like AWS CloudFormation or Terraform.
- Configure X-Ray SDK: Use the AWS X-Ray SDK in your Lambda function code to record trace segments and spans. The SDK automatically handles the extraction and injection of trace context.
- Propagate Context to Downstream Services: When making HTTP requests to other services, the X-Ray SDK automatically adds the trace context to the request headers. For message queue-based communication, you might need to manually inject the trace context into the message payload using the SDK.
For example, in a Python Lambda function using the `aws-xray-sdk` library:
“`python
from aws_xray_sdk.core import xray_recorder
import requests
def lambda_handler(event, context):
with xray_recorder.capture(‘my_lambda_function’) as segment:
# … your code …
try:
response = requests.get(‘https://example.com’)
# X-Ray SDK automatically propagates trace context in headers
segment.put_metadata(‘http_response_status’, response.status_code)
except requests.exceptions.RequestException as e:
segment.add_exception(e)
# …
return
‘statusCode’: 200,
‘body’: ‘Hello from Lambda!’
“`
In this example, the `xray_recorder.capture()` context manager creates a trace segment, and the X-Ray SDK automatically propagates the trace context when making the HTTP request to `example.com`. This allows you to visualize the complete trace, including the Lambda function and the external service call, in the X-Ray console.
Data Collection and Storage
Effective distributed tracing hinges on the efficient collection and storage of trace data. This involves capturing information from serverless functions and storing it in a manner that facilitates analysis and troubleshooting. The design choices for data collection and storage significantly impact the performance, scalability, and cost-effectiveness of the tracing system.
Data Collection from Serverless Functions
The process of collecting trace data from serverless functions is intrinsically linked to the instrumentation techniques employed. The data collection mechanism must be lightweight to avoid impacting function performance and scalable to handle the potentially high volume of requests in a serverless environment.
- Instrumentation with Tracing Libraries: Tracing libraries, such as OpenTelemetry SDKs, are integrated directly into the serverless function’s code. These libraries automatically capture spans, events, and other relevant data during function execution. The library then exports this data to a tracing backend. For example, in a Python function using OpenTelemetry, the instrumentation might look like this:
from opentelemetry import trace from opentelemetry.sdk.trace import TracerProvider from opentelemetry.sdk.trace.export import ConsoleSpanExporter, SimpleSpanProcessor from opentelemetry.instrumentation.requests import RequestsInstrumentor trace.set_tracer_provider(TracerProvider()) tracer = trace.get_tracer(__name__) # Configure span exporter (e.g., to a console for demonstration) span_processor = SimpleSpanProcessor(ConsoleSpanExporter()) trace.get_tracer_provider().add_span_processor(span_processor) def lambda_handler(event, context): with tracer.start_as_current_span("my-function") as span: # Perform some operation span.set_attribute("event.type", "http_request") # ...function logic ... return "statusCode": 200, "body": "Hello, world!"
- Automatic Instrumentation (Agent-Based): Some platforms or agents can automatically instrument serverless functions without requiring code modifications. This approach typically involves injecting instrumentation code or leveraging platform-specific features to capture trace data. For instance, a cloud provider’s monitoring service might automatically instrument functions when they are deployed.
- Sidecar or Proxy-Based Collection: In more complex architectures, a sidecar or proxy process can intercept and collect trace data. The serverless function sends trace data to the sidecar, which then forwards it to the tracing backend. This pattern can be useful for decoupling tracing concerns from the function’s core logic.
- Sampling: To manage the volume of trace data, sampling is often employed. This involves selectively recording a subset of traces based on predefined criteria, such as a sampling rate or specific request attributes. Sampling helps reduce storage costs and improve query performance.
Storage Options for Trace Data
The selection of a storage solution for trace data is critical for performance, scalability, and query capabilities. The choice often depends on the specific requirements of the application and the volume of data generated.
- Time-Series Databases (TSDBs): TSDBs are optimized for storing time-stamped data, making them a natural fit for trace data. They offer efficient storage, retrieval, and aggregation of metrics and traces. Examples include Prometheus, InfluxDB, and TimescaleDB. TSDBs are particularly well-suited for analyzing performance trends and identifying bottlenecks over time.
- Object Storage: Object storage services, such as Amazon S3, Google Cloud Storage, and Azure Blob Storage, provide highly scalable and cost-effective storage for large volumes of data. Trace data can be stored as JSON or other formats in object storage. This approach is suitable for long-term data retention and batch processing. Queries against object storage are often performed using tools like AWS Athena or Google BigQuery.
- Distributed Tracing Backends: Dedicated tracing backends, such as Jaeger, Zipkin, and Datadog, offer specialized storage and querying capabilities optimized for trace data. These backends typically combine time-series storage with indexing and search features tailored for traces. They often provide pre-built dashboards and visualizations for analyzing trace data.
- Relational Databases: While less common due to the performance characteristics of storing large amounts of trace data, relational databases can be used. They offer strong data consistency and transactional support, but may require careful schema design and optimization to handle the volume and velocity of trace data.
Examples of Queries for Performance Bottlenecks
Analyzing trace data involves querying and visualizing spans to identify performance bottlenecks and understand the flow of requests through a system. The specific queries depend on the chosen storage solution and the capabilities of the tracing backend.
- Identifying Slowest Services:
SELECT service_name, avg(duration) FROM spans WHERE start_time BETWEEN '2024-01-01' AND '2024-01-02' GROUP BY service_name ORDER BY avg(duration) DESC;
This query, suitable for a TSDB or a tracing backend, identifies the services with the longest average duration over a specific time period.
- Detecting Errors and Failures:
SELECT service_name, count(*) FROM spans WHERE status = 'ERROR' AND start_time BETWEEN '2024-01-01' AND '2024-01-02' GROUP BY service_name ORDER BY count(*) DESC;
This query identifies services with the highest number of errors, helping to pinpoint failing components. The ‘status’ attribute would be set during instrumentation.
- Analyzing Latency Distribution:
SELECT histogram(duration, 1000, 100) as duration_buckets, count(*) FROM spans WHERE service_name = 'checkout-service' AND start_time BETWEEN '2024-01-01' AND '2024-01-02' GROUP BY duration_buckets ORDER BY duration_buckets;
This query, utilizing a histogram function available in some TSDBs, provides insight into the distribution of request durations for a specific service.
It helps identify if there are significant outliers or if the majority of requests fall within an acceptable range. The arguments of the `histogram` function define the range and number of buckets.
- Tracing Specific Requests:
SELECT- FROM spans WHERE trace_id = 'your_trace_id' ORDER BY start_time;
This query retrieves all spans associated with a specific trace ID, allowing for a detailed examination of the request’s journey through the system. The `trace_id` is propagated throughout the distributed system.
- Identifying Bottlenecks in a Specific Path:
SELECT span_name, avg(duration) FROM spans WHERE trace_id = 'your_trace_id' GROUP BY span_name ORDER BY avg(duration) DESC;
This query, when executed on a specific trace ID, identifies the slowest spans within a request’s path. It is particularly useful for pinpointing specific function calls or operations that are contributing to overall latency.
The span names are defined during instrumentation.
Analyzing Trace Data for Performance Tuning
Distributed tracing is invaluable for optimizing the performance of serverless applications. By analyzing the data collected from traces, developers can pinpoint inefficiencies and bottlenecks that hinder application responsiveness and resource utilization. This analysis allows for targeted improvements, leading to faster execution times and reduced operational costs.
Identifying Performance Bottlenecks
Trace data reveals performance bottlenecks by highlighting areas where operations take longer than expected. This involves examining the duration of various components within a request, from function invocations to database interactions and external API calls. The goal is to identify the slowest parts of the process, which are the primary targets for optimization.
- Function Invocations: Slow function executions can be identified by examining the span duration associated with each function call. High latency suggests potential issues within the function’s code, such as inefficient algorithms, excessive resource consumption, or I/O-bound operations.
- Database Queries: Traces capture the time spent on database interactions. Long query times indicate database performance problems, potentially due to inefficient query design, inadequate indexing, or database server overload.
- Network Calls: The duration of network calls to external services or APIs is recorded. Slow network calls can be caused by network latency, overloaded external services, or inefficient data transfer methods.
Pinpointing Slow Components
Trace data facilitates pinpointing specific components contributing to latency. This is achieved by examining the spans and their relationships within a trace. The span duration and start/end timestamps provide precise timing information for each operation, enabling the identification of the problematic components.
- Slow Function Invocations: By examining the span for a specific function invocation, developers can determine its execution time. If the duration is unusually high, the function’s code can be analyzed to identify the cause of the slowness. This may involve profiling the code to find performance hotspots or optimizing database queries within the function.
- Slow Database Queries: Database query spans provide information on the time spent executing SQL queries. Slow queries can be identified by examining the span duration and the SQL query itself. Query optimization techniques, such as adding indexes or rewriting the query, can then be applied to improve performance.
- Slow Network Calls: Network call spans indicate the time spent communicating with external services. If the duration of a network call is high, the network connection, the external service’s response time, or the amount of data transferred may be the cause. Optimizing the network connection, caching data, or using a more efficient API can help reduce latency.
Example Latency Analysis Table
The following table provides an example of how trace data can be used to analyze the average latency of different components within a serverless application. This data helps to quickly identify performance bottlenecks and areas for optimization.
| Component | Average Latency (ms) | Percentage of Total Time | Observations |
|---|---|---|---|
| API Gateway Request | 50 | 5% | Minimal latency, indicating efficient routing. |
| Function: `processOrder` | 250 | 25% | Moderate latency; potential optimization in data processing logic. |
| Database Query: `getOrderDetails` | 300 | 30% | Significant latency; requires investigation into query optimization and indexing. |
| Function: `updateInventory` | 150 | 15% | Reasonable latency; check for potential database contention. |
| Network Call: `sendNotification` | 250 | 25% | Moderate latency; evaluate external service response times and network conditions. |
Integration with Monitoring and Alerting Systems
Distributed tracing, while powerful on its own, truly shines when integrated with existing monitoring and alerting systems. This synergy provides a holistic view of application performance and enables proactive identification and resolution of issues. The combined data allows for a deeper understanding of system behavior and the creation of intelligent alerts.
Synergistic Relationship of Tracing, Monitoring, and Alerting
The integration of distributed tracing with monitoring and alerting systems creates a feedback loop that optimizes application performance. Monitoring systems collect metrics such as CPU usage, memory consumption, and network latency. Alerting systems use these metrics, along with predefined thresholds, to trigger notifications when anomalies occur. Distributed tracing provides the detailed context necessary to diagnose the root cause of these anomalies.
By correlating trace data with metrics, developers can pinpoint the exact services and operations responsible for performance bottlenecks and failures.
Alert Creation Based on Trace Data
Alerts can be generated based on various trace data characteristics. This allows for proactive detection of performance issues before they impact users. Several strategies are used for generating these alerts.
- Slow Service Response Times: Define alerts that trigger when the average response time of a service exceeds a certain threshold. For example, an alert could be created if the `checkout-service` takes longer than 500ms to respond to requests. This can be determined by analyzing the span duration within a trace.
- High Error Rates: Set alerts based on the percentage of requests that result in errors within a service. A threshold could be set for the `user-service` to alert when error rates exceed 5% over a five-minute period. This involves analyzing the `status_code` attribute of spans.
- Latency Anomalies: Detect unusual spikes in latency for specific operations or services. This involves comparing current latency against historical data or baseline performance metrics.
- Bottleneck Identification: Create alerts that identify services or operations consistently contributing to overall request latency. This helps pinpoint where optimization efforts are most needed. Analyzing span durations across different services helps identify the slowest components.
Consider a scenario where an e-commerce application experiences a sudden increase in checkout failures. By integrating tracing with an alerting system, an alert can be triggered based on an increase in the error rate within the `checkout-service`. Upon investigation, developers can examine the trace data to identify that a database query within the `payment-processing` service is taking significantly longer than usual.
This detailed information enables rapid identification and resolution of the problem.
Visualization of Trace Data Alongside Other Metrics
Visualizing trace data alongside other relevant metrics provides a comprehensive understanding of application performance. This integration enables developers to correlate performance issues with system resource utilization. Tools often provide dashboards that combine different data sources.
- CPU Usage and Trace Data: Display CPU usage metrics for each service alongside the trace data. This allows for correlation of high CPU utilization with specific service operations. If the `product-catalog-service` is showing both high CPU usage and slow response times, it indicates a potential CPU-bound bottleneck within that service.
- Memory Consumption and Trace Data: Visualize memory consumption metrics for each service alongside trace data. This can help identify memory leaks or inefficient memory usage. For instance, if the `recommendation-service` exhibits increasing memory consumption along with slow response times, a memory leak is a likely cause.
- Network Latency and Trace Data: Display network latency metrics alongside trace data to identify network-related performance issues. This could involve visualizing the time spent in network calls between services. High network latency between the `frontend-service` and the `order-service` could indicate a network congestion issue.
- Error Rates and Trace Data: Correlate error rates with specific service operations. This allows developers to pinpoint the operations contributing most to errors. If the `user-authentication-service` has a high error rate and a specific API endpoint, the trace data would help pinpoint the exact function calls that are failing.
For example, a dashboard might show a time series graph of the average latency of the `order-service`, alongside a graph of the CPU utilization of the servers hosting the `order-service`. A spike in latency coinciding with a spike in CPU usage would strongly suggest a CPU-bound bottleneck within the service. This information allows for targeted optimization efforts, such as optimizing the code or scaling the service horizontally.
Security Considerations in Distributed Tracing
Distributed tracing, while invaluable for monitoring and debugging serverless applications, introduces new security challenges. The very nature of capturing detailed execution information across distributed services creates potential vulnerabilities. Improperly secured tracing systems can expose sensitive data, facilitate malicious activities, and compromise the overall security posture of the application. A thorough understanding of these security implications and the implementation of robust security measures are crucial for leveraging the benefits of distributed tracing without jeopardizing the application’s security.
Security Implications of Trace Data
Trace data, by its comprehensive nature, can inadvertently reveal sensitive information. This information could include personally identifiable information (PII), API keys, database credentials, and other confidential data that, if compromised, could lead to severe security breaches. Moreover, the detailed execution context provided by traces can be exploited by attackers to understand application behavior, identify vulnerabilities, and craft targeted attacks. This is especially critical in serverless environments where the ephemeral nature of functions and the distributed nature of services complicate security management.
Potential Security Vulnerabilities Related to Trace Data
Several vulnerabilities can arise from the mishandling of trace data.
- Data Exposure: Trace data may inadvertently contain sensitive information, such as API keys, passwords, or PII, if proper data masking and redaction are not implemented. For instance, if a function logs the parameters of a database query, a trace might expose the user’s credentials.
- Unauthorized Access: Trace data stores might be vulnerable to unauthorized access, whether due to misconfigured access controls, weak authentication, or compromised credentials. An attacker gaining access to trace data could analyze it to understand the application’s inner workings and identify potential attack vectors.
- Data Tampering: Attackers might attempt to tamper with trace data to hide malicious activity, mislead monitoring systems, or cover their tracks. If trace data integrity is not ensured, it can undermine the reliability of security audits and incident investigations.
- Injection Attacks: If trace data collection mechanisms are not properly sanitized, attackers could inject malicious code into trace data, leading to cross-site scripting (XSS) or other injection vulnerabilities within the monitoring and analysis tools.
- Denial of Service (DoS): Excessive tracing or logging of high-volume events can lead to resource exhaustion, potentially causing a denial of service. This is particularly relevant in serverless environments where resources are dynamically allocated and scaling is based on demand.
Recommendations for Securing Trace Data and Protecting Sensitive Information
Implementing robust security measures is essential to mitigate the risks associated with distributed tracing.
- Data Masking and Redaction: Implement data masking and redaction techniques to remove or obfuscate sensitive data before it is stored in traces. For example, redact credit card numbers, PII, and API keys from request headers, query parameters, and response bodies. Consider using a data loss prevention (DLP) solution integrated with your tracing system.
- Access Control and Authentication: Enforce strict access controls on trace data stores and monitoring tools. Use strong authentication mechanisms, such as multi-factor authentication (MFA), to prevent unauthorized access. Regularly review and audit access permissions to ensure they align with the principle of least privilege.
- Encryption: Encrypt trace data at rest and in transit to protect it from unauthorized access. Use encryption keys managed by a secure key management service (KMS). Implement Transport Layer Security (TLS) for secure communication between services and the tracing backend.
- Data Integrity Verification: Implement mechanisms to verify the integrity of trace data, such as digital signatures or checksums, to detect any tampering attempts. This ensures that the trace data is reliable and can be trusted for security audits and incident investigations.
- Rate Limiting and Quotas: Implement rate limiting and quotas on tracing to prevent excessive logging and potential denial-of-service attacks. This limits the volume of trace data generated and stored, protecting the system from resource exhaustion.
- Regular Auditing and Monitoring: Regularly audit your tracing system for security vulnerabilities and misconfigurations. Monitor trace data for suspicious activity, such as unusual API calls, failed authentication attempts, or unexpected data patterns. Use security information and event management (SIEM) tools to correlate trace data with other security events.
- Security Awareness Training: Educate developers and operations staff about the security implications of distributed tracing and the importance of protecting sensitive data. Emphasize the need for secure coding practices and the proper handling of trace data.
- Compliance and Regulatory Requirements: Ensure your tracing practices comply with relevant industry regulations and data privacy laws, such as GDPR and CCPA. Implement data retention policies and data deletion procedures to meet compliance requirements.
- Use a Dedicated Tracing Backend: Consider using a dedicated, managed tracing backend provided by a reputable vendor. These backends often offer built-in security features, such as data masking, access controls, and encryption, to help secure your trace data. For example, AWS X-Ray, Google Cloud Trace, and Azure Application Insights all offer features to help manage the security of your tracing data.
Best Practices for Distributed Tracing in Serverless

Distributed tracing, while offering invaluable insights into serverless application behavior, requires careful implementation to maximize its effectiveness and minimize overhead. Adhering to best practices ensures accurate, performant, and actionable trace data, ultimately leading to improved application reliability and efficiency. This section Artikels key strategies for successfully implementing and managing distributed tracing in serverless environments.
Instrumentation Strategy
Proper instrumentation is the cornerstone of effective distributed tracing. The choice of instrumentation method should be aligned with the serverless platform and the application’s architecture.
- Automated Instrumentation where possible: Leverage auto-instrumentation agents provided by tracing vendors or cloud providers. These agents automatically inject tracing code into application code, reducing manual effort and ensuring consistent tracing across services. However, they might not always cover every aspect of a serverless application, especially custom integrations or libraries.
- Manual Instrumentation for Custom Code: Manually instrument custom code, third-party libraries, and integrations that are not automatically covered. This involves using tracing SDKs provided by tracing vendors to create spans, propagate context, and record relevant data.
- Context Propagation Best Practices: Implement robust context propagation mechanisms. Serverless architectures often involve complex chains of invocations across different services and platforms. Correctly propagating trace context (e.g., trace IDs, span IDs) is crucial for linking spans together and reconstructing end-to-end traces.
- Consistent Span Naming and Metadata: Establish a standardized naming convention for spans and include meaningful metadata. Span names should accurately reflect the operation being performed (e.g., “HTTP Request,” “Database Query”). Metadata, such as request parameters, user IDs, and service names, enriches traces and facilitates filtering and analysis.
- Strategic Sampling: Implement intelligent sampling strategies to manage the volume of trace data. While capturing every trace might seem ideal, it can lead to excessive storage costs and performance bottlenecks. Employ sampling techniques based on factors like request type, error rates, or service priority to capture a representative subset of traces.
Trace Data Management
Effective management of trace data is crucial for ensuring its usability and cost-effectiveness.
- Data Retention Policies: Define clear data retention policies based on business needs and compliance requirements. Determine how long trace data should be stored and archived to balance the need for historical analysis with storage costs. Consider different retention periods for different types of data (e.g., longer retention for critical errors).
- Data Aggregation and Summarization: Utilize data aggregation and summarization techniques to reduce the volume of raw trace data. Group similar spans together to identify performance trends and reduce the need to analyze individual traces. For example, calculate average response times, error rates, and throughput metrics.
- Trace Data Security: Implement appropriate security measures to protect sensitive data within traces. Mask or redact sensitive information, such as Personally Identifiable Information (PII) or API keys, to prevent unauthorized access and maintain compliance with data privacy regulations.
- Cost Optimization Strategies: Optimize tracing costs by carefully considering data volume, storage options, and the use of sampling. Choose cost-effective storage solutions and evaluate the trade-offs between data granularity and storage costs. Leverage vendor-specific features for cost management.
Operational Considerations
Operational aspects play a significant role in the overall success of distributed tracing.
- Monitoring and Alerting Integration: Integrate tracing data with monitoring and alerting systems to proactively identify and address performance issues. Configure alerts based on key metrics derived from traces, such as high latency, error rates, or resource utilization.
- Performance Impact Assessment: Regularly assess the performance impact of distributed tracing on serverless functions. Monitor function execution times, resource consumption, and cold start times to ensure that tracing does not introduce unacceptable overhead.
- Regular Review and Tuning: Continuously review and tune tracing configurations to optimize performance and ensure data accuracy. Analyze trace data to identify areas for improvement, such as poorly instrumented code or inefficient sampling strategies.
- Team Training and Documentation: Provide comprehensive training and documentation to development and operations teams on the use of distributed tracing tools and techniques. Ensure that teams understand how to interpret trace data, troubleshoot performance issues, and contribute to the instrumentation process.
Checklist for Effective Distributed Tracing
This checklist summarizes key steps to ensure the successful implementation of distributed tracing in serverless environments.
- Define clear objectives for distributed tracing (e.g., identify performance bottlenecks, troubleshoot errors).
- Select a suitable tracing vendor or platform.
- Instrument all relevant services and functions, including custom code and integrations.
- Implement robust context propagation mechanisms.
- Establish a standardized naming convention for spans and include meaningful metadata.
- Implement intelligent sampling strategies to manage trace data volume.
- Define data retention policies and optimize storage costs.
- Integrate tracing data with monitoring and alerting systems.
- Regularly review and tune tracing configurations.
- Provide training and documentation to development and operations teams.
Common Pitfalls to Avoid
Avoiding common pitfalls is essential for a successful distributed tracing implementation.
- Ignoring Context Propagation: Failing to propagate trace context correctly, resulting in fragmented and incomplete traces.
- Over-instrumentation: Instrumenting too much code, leading to excessive data volume and performance overhead.
- Under-instrumentation: Not instrumenting critical parts of the application, resulting in blind spots and incomplete visibility.
- Lack of Standardized Span Naming: Using inconsistent or ambiguous span names, making it difficult to analyze and interpret trace data.
- Insufficient Metadata: Failing to include relevant metadata, limiting the ability to filter and analyze traces effectively.
- Ignoring Performance Impact: Neglecting to monitor the performance impact of tracing on serverless functions, leading to unexpected overhead.
- Lack of Data Retention Planning: Not defining data retention policies, resulting in uncontrolled storage costs and potential compliance issues.
- Poor Security Practices: Failing to protect sensitive data within traces, exposing it to unauthorized access.
- Lack of Training and Documentation: Not providing adequate training and documentation, hindering team adoption and understanding of tracing tools.
- Not Integrating with Monitoring and Alerting: Failing to integrate tracing data with monitoring and alerting systems, missing opportunities to proactively identify and address performance issues.
Final Conclusion
In conclusion, distributed tracing is indispensable for serverless applications. By providing unparalleled visibility into the inner workings of complex systems, it empowers developers to optimize performance, troubleshoot issues with precision, and build robust, scalable applications. Embracing distributed tracing is not merely an enhancement; it is a fundamental shift towards a more informed and efficient approach to serverless development, ensuring that the journey of a request, no matter how intricate, remains transparent and manageable.
FAQ Corner
What is a “span” in distributed tracing?
A span represents a single unit of work within a trace, such as a function call or a database query. It contains information like start and end times, operation name, and any relevant metadata (attributes).
How does distributed tracing differ from traditional application monitoring?
Traditional monitoring often focuses on aggregate metrics and individual service performance. Distributed tracing, however, tracks the complete path of a request across multiple services, providing end-to-end visibility and context for troubleshooting.
What are the main benefits of using distributed tracing in serverless applications?
Distributed tracing helps identify performance bottlenecks, debug complex issues, understand service dependencies, and optimize application performance by providing detailed insights into request flows.
What tools are commonly used for distributed tracing in serverless environments?
Popular tools include Jaeger, Zipkin, AWS X-Ray, and commercial solutions like Datadog and New Relic.
How is trace context propagated in serverless applications?
Trace context is typically propagated using HTTP headers, message queues, or other mechanisms to ensure that a trace can follow a request across different services and functions.