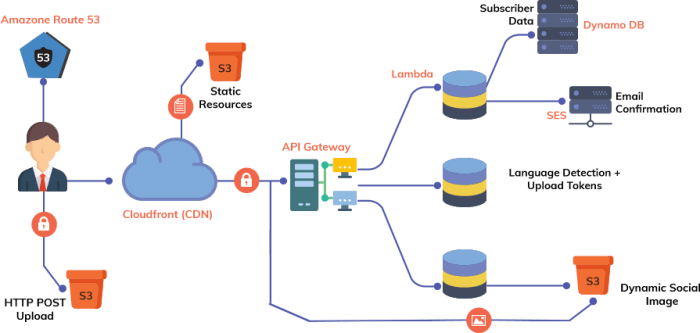
The publish-subscribe (pub-sub) pattern in serverless represents a paradigm shift in how applications communicate and react to events. It decouples components, enabling independent scaling, improved resilience, and a more flexible architecture. Instead of direct point-to-point communication, pub-sub introduces a message broker, acting as an intermediary that facilitates asynchronous message exchange between publishers and subscribers. This architecture allows for the creation of highly responsive and scalable serverless applications, perfectly suited for event-driven environments.
This approach allows for a robust and scalable system where components are less reliant on each other. This allows for the system to evolve and adapt to changing requirements, offering flexibility and maintainability, particularly in cloud environments. We will delve into the core concepts, benefits, and implementation strategies of the pub-sub pattern, focusing on how it transforms the development of serverless applications.
Core Concept: Defining Pub-Sub in Serverless
The publish-subscribe (pub-sub) pattern is a messaging paradigm that enables asynchronous communication between independent software components. In the context of serverless architectures, pub-sub provides a crucial mechanism for decoupling services, promoting scalability, and improving system resilience. This allows different serverless functions or applications to interact without direct knowledge of each other, leading to a more flexible and maintainable system.
Definition of Pub-Sub and Communication Facilitation
Pub-Sub, short for publish-subscribe, is a messaging pattern where publishers (also known as producers) send messages to a central message broker (also known as a message queue or topic). Subscribers (also known as consumers) then receive these messages from the broker. This architecture facilitates asynchronous communication, meaning that the publisher doesn’t need to wait for the subscriber to process the message before continuing its operations.
The core principle is that publishers and subscribers are decoupled; they don’t know about each other directly. This decoupling is a key advantage in serverless environments, allowing components to scale independently and evolve without impacting other parts of the system.
Roles of Publishers, Subscribers, and the Message Broker
The pub-sub system relies on three primary components: publishers, subscribers, and the message broker. Each component plays a distinct role in facilitating message exchange.
- Publishers: Publishers are the entities that generate and send messages. They create messages containing data or events and publish them to a specific topic on the message broker. Publishers do not need to know who the subscribers are or how many subscribers are listening to a particular topic. The only responsibility of a publisher is to format and send the message.
- Subscribers: Subscribers are the entities that receive and process messages. They subscribe to specific topics on the message broker to indicate their interest in receiving messages published to those topics. When a message is published to a topic a subscriber is listening to, the message broker delivers a copy of the message to the subscriber. Subscribers can process the message and perform any necessary actions.
The number of subscribers can scale independently of the number of publishers.
- Message Broker: The message broker acts as the central hub for message exchange. It receives messages from publishers, routes them to the appropriate subscribers based on their subscriptions, and manages the message delivery process. The broker provides a buffer for messages, ensuring that even if subscribers are temporarily unavailable, messages are not lost. The broker also handles message persistence, delivery guarantees (such as at-least-once or at-most-once delivery), and potentially message filtering and transformation.
Examples of message brokers used in serverless architectures include Amazon SNS, Google Cloud Pub/Sub, and Azure Event Grid. The broker’s core functions include:
- Message Routing: Directing messages from publishers to the correct subscribers based on topic subscriptions.
- Message Persistence: Storing messages temporarily or permanently to ensure delivery even if subscribers are unavailable.
- Delivery Guarantees: Ensuring messages are delivered at least once, at most once, or exactly once, depending on the configuration.
Benefits of Pub-Sub in Serverless Environments

The adoption of the pub-sub pattern in serverless architectures offers significant advantages, primarily due to the inherent characteristics of serverless computing. Serverless environments, with their focus on event-driven execution and automatic scaling, are ideally suited for pub-sub implementations. This architectural style fosters decoupled components, enhances scalability, and simplifies application management, leading to more resilient and efficient systems.
Scalability and Elasticity
Serverless pub-sub architectures excel in scalability and elasticity. This is achieved by decoupling the components, allowing them to scale independently based on demand.
- Automatic Scaling: Serverless platforms automatically scale the compute resources for both publishers and subscribers based on the volume of events and the processing needs. This eliminates the need for manual provisioning and management of infrastructure, allowing applications to handle fluctuating workloads seamlessly. For example, a retail application using pub-sub to process order confirmations can scale its order processing function (subscriber) independently of the order placement function (publisher).
During peak sales periods, the order processing function can scale up to handle the increased volume of order confirmation events, while the order placement function continues to function normally.
- Event-Driven Architecture: The event-driven nature of pub-sub enables asynchronous processing. Subscribers can react to events in real-time, without being directly coupled to the publishers. This asynchronous communication model prevents bottlenecks and allows for more efficient utilization of resources.
- Reduced Operational Overhead: The serverless platform handles the underlying infrastructure, including scaling, patching, and maintenance. This significantly reduces the operational overhead associated with managing the application, allowing developers to focus on writing business logic.
Decoupling and Loose Coupling
Pub-sub inherently promotes decoupling between components, which is a cornerstone of a well-designed serverless application. This decoupling offers several benefits.
- Independent Development and Deployment: Publishers and subscribers can be developed and deployed independently. This means that changes to one component do not necessarily require changes to the other, accelerating the development cycle and reducing the risk of cascading failures. For instance, a new feature can be added to an event subscriber without affecting the publisher.
- Improved Fault Tolerance: Because publishers and subscribers are decoupled, the failure of one component does not necessarily impact the others. Events can be buffered and retried, and subscribers can be designed to handle failures gracefully. For example, if an email notification service (subscriber) fails, the system can queue the email events for later processing, ensuring that critical notifications are still delivered.
- Increased Flexibility: Decoupling allows for easier integration of new services and functionalities. New subscribers can be added to an existing system without modifying the publishers. This promotes modularity and reusability. A new fraud detection service (subscriber) can be easily integrated into an existing e-commerce system by subscribing to order events, without requiring any changes to the order placement service (publisher).
Event-Driven Architecture and Real-Time Processing
The pub-sub pattern facilitates the creation of event-driven architectures, enabling real-time processing and responsiveness.
- Real-time Data Processing: Events can trigger immediate actions, enabling real-time data processing and responsiveness. This is particularly useful for applications that require immediate reactions to events, such as financial trading platforms or IoT applications.
- Improved User Experience: Real-time updates and notifications can significantly improve the user experience. Users can receive instant feedback on their actions, such as order confirmations, payment updates, or new messages.
- Simplified Integration: Pub-sub simplifies the integration of various services and systems. Different components can subscribe to relevant events and react accordingly, creating a more cohesive and integrated system.
Comparison with Direct API Calls
Direct API calls and pub-sub represent different communication models with distinct trade-offs in serverless environments.
| Feature | Direct API Calls | Pub-Sub |
|---|---|---|
| Coupling | Tightly coupled | Loosely coupled |
| Scalability | Can be limited by synchronous nature | Highly scalable due to asynchronous nature |
| Fault Tolerance | Potential for cascading failures | Improved fault tolerance through decoupling |
| Complexity | Simpler for basic interactions | More complex, especially for initial setup |
| Real-time Capabilities | Can be challenging to implement real-time updates | Excellent for real-time updates |
Direct API calls are suitable for simple, synchronous interactions where immediate responses are required. However, they can lead to tightly coupled systems and scalability challenges. Pub-sub is preferable when decoupling, scalability, and real-time processing are crucial. For instance, consider an e-commerce application. A direct API call might be used to retrieve product details, while pub-sub is better suited for handling order processing (asynchronously) or sending real-time notifications.
Scenarios Where Pub-Sub is Particularly Beneficial
Pub-sub is particularly advantageous in several serverless application scenarios.
- Asynchronous Task Processing: Offloading tasks to background processes using pub-sub allows for increased responsiveness and scalability. For example, image processing, video encoding, or data transformation can be performed asynchronously.
- Real-time Notifications and Updates: Pub-sub enables real-time notifications and updates to users, such as order confirmations, chat messages, or stock price alerts.
- Event-Driven Integrations: Pub-sub facilitates the integration of various services and systems by allowing them to react to specific events. This is useful for building microservices architectures.
- IoT Applications: Pub-sub is well-suited for handling data from IoT devices, enabling real-time monitoring, analysis, and control. The large volume of data generated by IoT devices can be efficiently processed using a pub-sub architecture.
- Data Streaming and Analytics: Pub-sub can be used to stream data from various sources, enabling real-time analytics and insights.
Serverless Message Brokers and Their Functions
Message brokers are the central nervous system of a pub-sub architecture in serverless environments. They act as intermediaries, decoupling publishers and subscribers and facilitating the asynchronous exchange of messages. This decoupling is crucial for the scalability, resilience, and flexibility that define serverless applications. The choice of message broker significantly impacts the performance, cost, and operational complexity of a serverless system.
Serverless Message Broker Roles
Message brokers in serverless pub-sub systems perform several key functions. They receive messages from publishers, route them to the appropriate subscribers based on predefined criteria (filtering), and manage the delivery of these messages. They also handle error conditions, retrying message delivery when necessary and providing mechanisms for monitoring and logging message flow. Furthermore, message brokers offer features such as message persistence, allowing messages to be stored and replayed in case of subscriber unavailability or system failures.
This ensures data integrity and prevents message loss.
Serverless Message Broker Comparison
Different serverless message broker services offer varying features and functionalities. Choosing the right broker depends on the specific requirements of the application, considering factors such as message volume, latency requirements, filtering capabilities, and cost. The following table provides a comparison of three prominent serverless message broker services: AWS SNS, Google Cloud Pub/Sub, and Azure Event Grid.
| Broker Name | Features | Pricing Model |
|---|---|---|
| AWS SNS (Simple Notification Service) |
|
|
| Google Cloud Pub/Sub |
|
|
| Azure Event Grid |
|
|
Message Delivery, Filtering, and Error Handling
Message brokers employ various mechanisms for message delivery, filtering, and error handling.Message delivery strategies are designed to ensure messages reach subscribers.
- Delivery Mechanisms: Brokers employ push and pull delivery models. Push models automatically send messages to subscribers (e.g., HTTP endpoints), while pull models allow subscribers to actively retrieve messages from the broker. AWS SNS supports push delivery to various endpoints, while Google Cloud Pub/Sub supports both.
- Delivery Guarantees: Brokers offer different levels of delivery guarantees, such as at-least-once or at-most-once delivery. At-least-once delivery ensures that each message is delivered at least once, even if it means potential duplicates. At-most-once delivery guarantees that each message is delivered at most once, but some messages may be lost if delivery fails.
Filtering allows subscribers to receive only the messages they are interested in.
- Filtering Criteria: Brokers use filtering criteria, such as message attributes, topic subscriptions, or content-based filtering, to route messages. AWS SNS allows filtering based on message attributes, while Google Cloud Pub/Sub and Azure Event Grid offer more sophisticated filtering capabilities.
- Filtering Mechanisms: Filtering is often performed at the broker level, minimizing the workload on subscribers. This ensures that subscribers only receive the messages relevant to them.
Error handling is crucial for maintaining the reliability of the system.
- Error Handling Strategies: Brokers implement various error handling strategies, such as retrying message delivery, dead-letter queues, and exponential backoff. When a message delivery fails, the broker may retry the delivery a certain number of times or move the message to a dead-letter queue for later analysis.
- Dead-Letter Queues (DLQs): DLQs store messages that could not be delivered successfully after multiple attempts. This allows developers to investigate the cause of the failure and potentially reprocess the messages.
- Monitoring and Logging: Brokers provide monitoring and logging capabilities to track message flow, identify errors, and measure performance. This information is critical for troubleshooting and optimizing the system.
Components and Interactions

The core functionality of the Pub-Sub pattern in serverless architectures hinges on the seamless interaction between distinct components. These components – publishers, subscribers, and events – are orchestrated through a message broker, facilitating asynchronous communication and enabling decoupled architectures. This section details the roles of each component and the mechanics of their interactions, emphasizing the event-driven nature of the system.
Publisher-to-Topic Communication
Publishers are responsible for generating and disseminating messages, also known as events, to a specific topic or channel within the message broker. This action initiates the data flow within the system. The publisher doesn’t need to know about the subscribers; its sole responsibility is to publish events.The process involves the following steps:
- Event Generation: A publisher, such as a microservice or a serverless function, detects a significant event, like a user signup or a product purchase.
- Message Creation: The publisher formats the event data into a message, typically in a structured format like JSON or Protocol Buffers. This message encapsulates the relevant information about the event.
- Topic Selection: The publisher identifies the appropriate topic or channel to which the message should be published. This topic acts as a logical grouping for related events. For instance, all user signup events might be published to a “user-signup” topic.
- Message Publication: The publisher sends the message to the designated topic through the message broker’s API. The broker then handles the distribution of the message to all relevant subscribers.
For example, consider an e-commerce platform. When a customer places an order, the “order service” (the publisher) creates an “order placed” event and publishes it to the “order-events” topic. This action triggers other services (subscribers) to take actions, such as updating inventory or sending a confirmation email.
Subscriber Message Reception and Processing
Subscribers, representing various services or functions, are designed to receive and react to messages published to a specific topic. The subscriber is decoupled from the publisher, allowing for independent scaling and evolution of the system.The process a subscriber follows to receive and process messages includes:
- Subscription to a Topic: A subscriber registers its interest in receiving messages from a specific topic or channel. This subscription is managed by the message broker.
- Message Reception: The message broker delivers messages published to the subscribed topic to the subscriber. The delivery mechanism depends on the specific broker, potentially using push (e.g., HTTP endpoints) or pull (e.g., polling) methods.
- Message Processing: Upon receiving a message, the subscriber processes the event data. This could involve various actions, such as updating a database, triggering another serverless function, or sending notifications.
- Acknowledgment (Optional): In some messaging systems, subscribers are required to acknowledge the successful processing of a message. This allows the broker to track message delivery and handle potential failures.
Continuing with the e-commerce example, the “inventory service” (a subscriber) subscribes to the “order-events” topic. When an “order placed” event is published, the inventory service receives the message, updates the inventory levels, and acknowledges the successful processing of the order. Another subscriber, the “email service,” would receive the same message and send a confirmation email to the customer. The decoupling ensures that the inventory service and email service can be updated independently, without affecting the order service.
The key principle is asynchronous communication, where the publisher doesn’t wait for the subscriber to complete its processing, promoting scalability and resilience.
Event-Driven Architecture with Pub-Sub
Pub-Sub (Publish-Subscribe) plays a crucial role in enabling event-driven architecture within serverless environments. This architectural style promotes loose coupling and asynchronous communication between services, enhancing scalability, resilience, and agility. Instead of direct service-to-service communication, services publish events to a central message broker, and other services subscribe to those events, reacting accordingly. This approach allows for independent scaling and evolution of services, as they are not directly dependent on each other.
Enabling Event-Driven Architecture with Pub-Sub
Pub-Sub facilitates event-driven architecture by decoupling event producers (publishers) from event consumers (subscribers). The core mechanism revolves around events, which are significant occurrences within a system. Publishers generate events, and subscribers register their interest in specific event types. The message broker then acts as an intermediary, routing events from publishers to the appropriate subscribers.The benefits of this architecture include:
- Asynchronous Communication: Services communicate without requiring immediate responses, improving performance and availability.
- Loose Coupling: Services are independent and can evolve without affecting other services.
- Scalability: The system can handle increased workloads by scaling individual services independently.
- Resilience: Failures in one service do not necessarily impact others, increasing overall system stability.
- Flexibility: New services can be easily added to respond to existing events without modifying existing code.
Common Events and Triggered Actions
Numerous events can trigger actions within a serverless application, leveraging the pub-sub pattern. These events represent significant occurrences that require a response. Examples include:
- File Uploads: When a user uploads a file to a storage service (e.g., Amazon S3, Google Cloud Storage, Azure Blob Storage), an event is published. Subscribers, such as image processing services, virus scanners, or metadata extractors, can then react to this event.
- Database Updates: Changes in a database (e.g., new records, updates, deletions) can generate events. Subscribers, such as search indexers, reporting services, or notification systems, can react to these events to update their respective data stores or trigger notifications.
- Order Placements: When a customer places an order, an event is published. Subscribers, such as inventory management systems, payment processors, and shipping services, can then initiate their respective processes.
- User Sign-Ups: A new user registration can trigger an event. Subscribers might include email marketing services, onboarding systems, or analytics dashboards.
- System Health Metrics: Monitoring systems can publish events based on system health metrics (e.g., CPU usage, memory consumption). Subscribers, such as auto-scaling services or alerting systems, can then react to these events.
Designing a Serverless Application Reacting to Events
Designing a serverless application that effectively reacts to events using pub-sub involves several key steps. The process leverages serverless message brokers and functions.
- Event Definition: Define the types of events your application will generate and consume. Each event should have a clear structure, including relevant data (payload) and metadata (timestamp, event source, etc.).
- Publisher Implementation: Implement services that publish events to the message broker. These services should be responsible for generating and formatting events according to the defined schema.
- Subscriber Implementation: Develop serverless functions (e.g., AWS Lambda, Google Cloud Functions, Azure Functions) that subscribe to specific event types. These functions are triggered automatically when an event matching their subscription criteria is published.
- Message Broker Configuration: Configure the message broker (e.g., Amazon SNS, Google Cloud Pub/Sub, Azure Event Grid) to route events from publishers to subscribers. This involves setting up topics, subscriptions, and filtering rules.
- Error Handling and Retries: Implement robust error handling and retry mechanisms to handle potential failures during event processing. This ensures that events are processed reliably, even in the face of transient errors.
- Monitoring and Logging: Implement comprehensive monitoring and logging to track event flow, function execution, and any errors. This provides insights into the application’s behavior and helps identify and resolve issues.
Consider the following example: an e-commerce platform. When a customer places an order, the order service publishes an “OrderPlaced” event to the message broker. A payment processing service subscribes to this event, initiating the payment process. An inventory management service also subscribes, updating the available stock. A shipping service subscribes, preparing the order for shipment.
This architecture allows each service to operate independently and scale based on its specific needs. If the payment service experiences an issue, the order processing and inventory management can continue unaffected, providing a more resilient user experience.
Implementing Pub-Sub
Implementing a pub-sub system in a serverless environment involves several steps, from choosing a message broker to writing the code for publishers and subscribers. The specific implementation details vary depending on the chosen cloud provider and the complexity of the system. This section provides a practical guide, using AWS as an example, to illustrate the key concepts and procedures involved.
Setting up the Serverless Message Broker (AWS SNS & SQS)
Setting up the serverless message broker is the first step in implementing a pub-sub system. AWS offers two primary services for this: Simple Notification Service (SNS) for publish-subscribe and Simple Queue Service (SQS) for queueing. A common pattern involves using SNS to fan out messages to multiple SQS queues.
Here’s how to configure SNS and SQS:
- Create an SNS Topic: This is the central point where publishers will send messages.
- Create SQS Queues: These queues will receive messages from the SNS topic. Each subscriber will be associated with a specific SQS queue. This allows for decoupling and resilience.
- Subscribe SQS Queues to the SNS Topic: This establishes the connection between the topic and the queues. Messages published to the SNS topic will be delivered to all subscribed SQS queues.
- Configure Access Policies: Ensure the appropriate permissions are set for publishers to publish to the SNS topic and for subscribers (e.g., Lambda functions) to read from the SQS queues. These policies typically use IAM roles.
This architecture leverages the strengths of both SNS and SQS: SNS for broadcasting messages and SQS for providing a durable, scalable, and fault-tolerant message storage. This approach ensures that even if subscribers are temporarily unavailable, the messages are not lost.
Publishing Messages (Python Example)
Publishing messages involves sending data to the SNS topic. The following Python code example uses the AWS SDK for Python (Boto3) to publish a message. This script is intended to run on a system that has appropriate AWS credentials configured, either through environment variables, IAM roles, or the AWS configuration file.
Here’s an example:
“`pythonimport boto3import json# Configure AWS credentials and regionsns_client = boto3.client(‘sns’, region_name=’your-aws-region’) # Replace with your AWS regiontopic_arn = ‘arn:aws:sns:your-aws-region:your-account-id:your-topic-name’ # Replace with your SNS topic ARNdef publish_message(message, subject): “””Publishes a message to the SNS topic.””” try: response = sns_client.publish( TopicArn=topic_arn, Message=json.dumps(message), Subject=subject ) print(f”Message published.
MessageId: response[‘MessageId’]”) except Exception as e: print(f”Error publishing message: e”)# Example usagemessage_data = ‘event_type’: ‘order_created’, ‘order_id’: ‘12345’, ‘timestamp’: ‘2024-01-20T10:00:00Z’publish_message(message_data, ‘New Order’)“`
This code snippet performs the following actions:
- Imports necessary libraries: `boto3` for interacting with AWS services and `json` for serializing the message data.
- Configures AWS client: Initializes an SNS client, specifying the AWS region. Replace `’your-aws-region’` with the appropriate region, such as ‘us-east-1’. The `topic_arn` must be updated with the ARN (Amazon Resource Name) of the SNS topic created previously.
- Defines the `publish_message` function: This function takes the message and subject as input, converts the message to a JSON string, and then calls the `publish` method of the SNS client. The `Subject` parameter is optional but recommended for filtering and easier message identification.
- Example Usage: Demonstrates how to create a sample message and publish it to the SNS topic. The message data is formatted as a dictionary, which is then serialized to JSON before being sent. The subject provides a human-readable description of the message.
Subscribing to Messages (Python Example with AWS Lambda and SQS)
Subscribing to messages involves creating a consumer that receives messages from the SQS queue. In a serverless environment, this is often implemented using an AWS Lambda function triggered by the SQS queue.
Here’s an example:
“`pythonimport jsonimport boto3sqs_client = boto3.client(‘sqs’, region_name=’your-aws-region’) # Replace with your AWS regionqueue_url = ‘https://sqs.your-aws-region.amazonaws.com/your-account-id/your-queue-name’ # Replace with your SQS queue URLdef lambda_handler(event, context): “””Lambda function to process messages from SQS.””” for record in event[‘Records’]: try: message_body = json.loads(record[‘body’]) print(f”Received message: message_body”) # Process the message (e.g., update a database, send an email) # Example: If the message contains an order_id, you might look up the order details order_id = message_body.get(‘order_id’) if order_id: print(f”Processing order: order_id”) # Delete the message from the queue after processing (optional, handled by Lambda by default) except Exception as e: print(f”Error processing message: e”) # Handle errors, e.g., by sending the message to a dead-letter queue return ‘statusCode’: 200, ‘body’: json.dumps(‘Messages processed successfully!’) “`
This code illustrates how to process messages:
- Imports necessary libraries: Includes `json` and `boto3`.
- Configures the SQS client: Initializes an SQS client, specifying the AWS region. Replace `’your-aws-region’` with the appropriate region. The `queue_url` must be updated with the URL of the SQS queue.
- Defines the `lambda_handler` function: This is the entry point for the Lambda function. It receives an `event` parameter, which contains the messages from the SQS queue.
- Iterates through messages: The code iterates through the records in the `event[‘Records’]` list. Each record represents a message from the queue.
- Parses message body: The message body is parsed from JSON.
- Processes the message: The code extracts data from the message and performs the necessary actions. This could involve updating a database, sending an email, or triggering other serverless functions.
- Handles errors: Includes a `try…except` block to catch potential errors during message processing. In a production environment, you would implement error handling, such as sending the failed message to a dead-letter queue for further investigation.
- Returns a response: The function returns a 200 OK status code upon successful processing. Lambda automatically handles deleting messages from the SQS queue after the function successfully completes.
Important Considerations:
- IAM Roles: The Lambda function’s IAM role must have permissions to read messages from the SQS queue. The publisher also requires the correct permissions to publish messages to the SNS topic.
- Queue Visibility Timeout: Configure the visibility timeout for the SQS queue appropriately. This setting determines how long a message remains invisible to other consumers after it has been retrieved by a Lambda function. If the function fails to process the message within the timeout, the message becomes visible again.
- Dead-Letter Queues (DLQ): Implement a DLQ to handle messages that fail to be processed multiple times. This helps to prevent message loss and allows for debugging and troubleshooting.
- Message Filtering: SNS supports message filtering, allowing subscribers to receive only messages that match specific criteria. This reduces unnecessary processing by subscribers.
By following these steps and adapting the code examples to your specific needs, you can effectively implement a pub-sub system in a serverless environment, enabling asynchronous communication, decoupling, and scalability. The combination of SNS and SQS offers a robust and reliable architecture suitable for various use cases, from event-driven applications to microservices communication.
Message Filtering and Routing Strategies
Efficient message filtering and routing are critical for the effective operation of pub-sub systems, particularly within serverless architectures. These mechanisms ensure that subscribers receive only the messages they are interested in, minimizing unnecessary processing and resource consumption. This selective delivery is achieved through a combination of filtering criteria and routing strategies.
Message Filtering Techniques
Message filtering is the process of selectively delivering messages to subscribers based on predefined criteria. Several techniques are employed to achieve this, each with its own strengths and limitations.
- Topic-Based Filtering: Subscribers express interest in messages by subscribing to specific topics. A topic is a logical channel or category. When a message is published, it’s assigned to a topic. The message broker then delivers the message to all subscribers of that topic. This is the simplest form of filtering.
For example, a subscriber might subscribe to the topic “orders.created” to receive notifications about new orders.
- Attribute-Based Filtering: Messages can contain attributes or metadata, such as message headers or payloads. Subscribers can define filters based on these attributes. The message broker examines the attributes of each message and delivers it only to subscribers whose filters match. This provides more granular control than topic-based filtering. For instance, a subscriber might filter for messages with the attribute “region” set to “US-East” and “status” set to “shipped.”
- Content-Based Filtering: This involves examining the content of the message payload to determine if it should be delivered to a subscriber. This is the most flexible, but also the most computationally intensive, filtering method. It often involves using regular expressions or other parsing techniques. An example could be filtering for messages that contain a specific product ID within the message body.
- Combination Filtering: Many systems allow a combination of filtering techniques. This provides a more powerful and flexible approach. For example, a subscriber might subscribe to a topic and then apply attribute-based filtering to further refine the messages it receives.
Examples of Filtering Criteria
The criteria used for filtering can vary depending on the specific pub-sub system and the needs of the application. Several examples illustrate this diversity.
- Message Attributes: Filtering based on message attributes allows for precise targeting. Consider an e-commerce platform. A subscriber might filter for messages with attributes like:
- `order_status = “shipped”`
- `customer_region = “Europe”`
- `order_value > 100`
This allows for specific notifications to be sent to relevant parties.
- Topic Subscriptions: Subscriptions to specific topics represent a fundamental filtering mechanism. For instance, a financial application might use topics like “stock.AAPL,” “currency.EURUSD,” and “market.news.” Subscribers interested in Apple stock would subscribe to “stock.AAPL,” ensuring they only receive relevant updates.
- Message Payload Content: Analyzing the message payload enables highly specific filtering. A monitoring system might filter for messages containing error codes, such as:
- `error_code = “500”`
- `severity = “critical”`
This allows for rapid identification and response to critical issues.
Routing Strategies
Routing strategies dictate how messages are delivered from publishers to subscribers. Different strategies are suitable for various scenarios, impacting performance, scalability, and message delivery guarantees.
- Direct Routing: In direct routing, a message is sent directly to a specific subscriber. This is common in systems where the subscriber is known in advance.
- Topic Routing: Messages are routed based on their topic. Subscribers subscribe to topics, and the message broker forwards messages to all subscribers of the matching topic.
- Fanout Routing: The message broker delivers a copy of the message to all subscribers, regardless of their subscription criteria. This is suitable for scenarios where all subscribers need to receive the message.
- Routing Key Based Routing: This strategy utilizes a routing key, often a string, that is associated with the message. Subscribers bind to the message broker using a binding key, which is then matched against the routing key of published messages. This allows for more flexible routing patterns than topic-based routing.
- Multicast Routing: Messages are delivered to a group of subscribers. This is similar to fanout, but the message broker may optimize delivery by sending a single copy of the message to the group.
Error Handling and Message Delivery Guarantees
Error handling and ensuring message delivery are critical aspects of any pub-sub system, particularly within a serverless environment where components are distributed and ephemeral. These mechanisms are essential for maintaining data integrity, preventing message loss, and ensuring the reliability of the event-driven architecture. Effective strategies mitigate failures and provide the necessary guarantees for the consistent flow of information.
Mechanisms for Handling Errors and Ensuring Message Delivery
Serverless pub-sub systems leverage a combination of techniques to address errors and ensure message delivery. These mechanisms often involve built-in features of the message broker, as well as custom implementations within the subscriber functions.
- Dead-Letter Queues (DLQs): DLQs are queues where messages that cannot be processed successfully are sent. This allows for isolating problematic messages for later inspection, debugging, or manual intervention. Serverless message brokers like AWS SQS, Azure Service Bus, and Google Cloud Pub/Sub offer built-in DLQ support.
- Retry Mechanisms: Automatic retry mechanisms are implemented to attempt message processing again after a failure. The retry strategy (e.g., exponential backoff) is crucial to avoid overwhelming the system with repeated failures.
- Circuit Breakers: Circuit breakers are used to prevent cascading failures. If a subscriber repeatedly fails, the circuit breaker “opens,” temporarily preventing new messages from being delivered to that subscriber, protecting the system from being overloaded.
- Monitoring and Alerting: Robust monitoring and alerting systems are essential for detecting and responding to errors. Metrics like message processing latency, failure rates, and DLQ sizes should be monitored to identify and address issues proactively.
- Idempotency: Ensuring that message processing is idempotent (can be executed multiple times without unintended side effects) is crucial. This helps mitigate the impact of retries and duplicate message deliveries.
Strategies for Dealing with Message Failures and Retries
Effective strategies for handling message failures and retries involve careful planning and implementation of various techniques. The goal is to minimize message loss and ensure that the system recovers gracefully from errors.
- Exponential Backoff with Jitter: Exponential backoff is a retry strategy where the time between retries increases exponentially. Adding jitter (randomness) to the backoff interval prevents multiple subscribers from retrying simultaneously, which can overload the system.
- Configurable Retry Limits: Setting appropriate retry limits prevents infinite loops and ensures that a message is eventually moved to a DLQ if it continues to fail.
- Error Logging and Tracing: Comprehensive error logging and distributed tracing are crucial for debugging failures. Logs should include the message ID, timestamp, error details, and relevant context. Distributed tracing allows for following a message’s journey across different components.
- Exception Handling in Subscriber Functions: Subscriber functions should include robust exception handling to catch and handle errors gracefully. This includes logging the error, potentially sending the message to a DLQ, and potentially triggering a retry.
- Message Content Validation: Validating message content before processing can prevent errors caused by malformed or invalid data. This can be done using schemas or other validation mechanisms.
Message Delivery Guarantees and Their Implications
Message delivery guarantees define the level of assurance that a message will be delivered and processed. The choice of delivery guarantee has significant implications for system design, complexity, and cost.
- At-Most-Once Delivery: This guarantee means that a message will be delivered at most once. This is the simplest guarantee, but it carries the risk of message loss if a failure occurs before or during processing. It is often used in scenarios where message loss is acceptable or where duplicate messages have minimal impact.
- At-Least-Once Delivery: This guarantee means that a message will be delivered at least once. This requires a mechanism to handle duplicate messages, such as idempotent processing or message deduplication. It ensures that messages are not lost but may result in duplicate processing.
- Exactly-Once Delivery: This is the strongest guarantee, ensuring that a message is delivered and processed exactly once. This is the most complex to implement and often requires distributed transaction management and message deduplication.
The choice of message delivery guarantee depends on the specific requirements of the application. For example, a system that processes financial transactions might require exactly-once delivery to prevent data inconsistencies, while a system that processes sensor data might be able to tolerate at-least-once delivery.
Consider a retail application. If a customer places an order, the system needs to ensure that the order is processed and the inventory is updated. In this scenario, at-least-once delivery would likely be appropriate. If a message is lost, the order might not be processed. If the message is duplicated, the inventory might be incorrectly decremented, leading to inconsistencies.
For high-value transactions, exactly-once delivery is crucial. This might involve using a distributed transaction manager to ensure atomicity and consistency. The choice of delivery guarantee directly impacts the complexity and cost of the system. A system that requires exactly-once delivery is generally more complex and expensive to build and maintain than a system that uses at-least-once or at-most-once delivery.
Use Cases and Real-World Applications
The pub-sub pattern in serverless architectures finds extensive application across various industries, enabling real-time data processing, efficient event-driven interactions, and improved system scalability. Its asynchronous nature allows for decoupled components, promoting resilience and fault tolerance. This section will explore specific use cases, providing detailed examples of its application in e-commerce, IoT, and data processing.
E-commerce Applications
E-commerce platforms leverage pub-sub for several crucial functionalities, enhancing the customer experience and operational efficiency. This is particularly evident in handling order processing, inventory management, and real-time updates.
- Scenario: An online retailer processes thousands of orders daily, with varying fulfillment timelines and payment methods. The platform must handle these orders efficiently while keeping customers informed about their order status.
- Events:
- Order Placed: A customer successfully places an order.
- Payment Received: The payment for an order is confirmed.
- Inventory Updated: The inventory count for ordered items is adjusted.
- Order Shipped: An order is dispatched for delivery.
- Delivery Update: Real-time updates on the delivery status are available.
- Components and Interactions:
- Order Service (Publisher): Responsible for receiving and validating order details. Publishes an “Order Placed” event to the message broker.
- Payment Service (Subscriber): Listens for “Order Placed” events. Upon receiving an event, it initiates payment processing. Publishes a “Payment Received” event upon successful payment.
- Inventory Service (Subscriber): Listens for “Order Placed” and “Payment Received” events. Decreases the inventory count for the ordered items. Publishes an “Inventory Updated” event.
- Shipping Service (Subscriber): Listens for “Payment Received” and “Inventory Updated” events. Prepares and ships the order. Publishes an “Order Shipped” event.
- Notification Service (Subscriber): Listens for “Order Shipped” and “Delivery Update” events. Sends real-time notifications to customers via email, SMS, or push notifications.
- Message Broker (e.g., AWS SNS/SQS, Google Pub/Sub): Acts as the central hub, routing events between services.
- Business Need Addressed:
- Real-time Order Tracking: Customers receive instant updates on their order status, enhancing satisfaction.
- Scalability: The decoupled architecture allows services to scale independently based on demand.
- Fault Tolerance: If one service fails, the others continue to operate, ensuring order processing isn’t entirely disrupted.
- Efficient Inventory Management: Real-time inventory updates prevent overselling and optimize stock levels.
IoT Applications
The pub-sub pattern is integral to managing and processing data generated by a large number of IoT devices. This is particularly relevant for applications involving smart homes, industrial automation, and connected vehicles.
- Scenario: A smart home system monitors various sensors, such as temperature sensors, door sensors, and security cameras, to provide real-time monitoring and control.
- Events:
- Temperature Reading: A temperature sensor sends a reading.
- Door Opened/Closed: A door sensor detects a change in state.
- Motion Detected: A motion sensor detects movement.
- Camera Feed: A security camera streams video.
- Components and Interactions:
- Sensors (Publishers): IoT devices, such as temperature sensors, publish data as events (e.g., “Temperature Reading”).
- Data Ingestion Service (Subscriber): Collects and preprocesses the sensor data, filtering out irrelevant information.
- Real-time Analytics Service (Subscriber): Analyzes the data to identify trends and anomalies, generating alerts.
- Control Service (Subscriber): Receives alerts and controls actuators (e.g., turning on the air conditioning).
- Notification Service (Subscriber): Sends notifications to the user (e.g., via a mobile app).
- Message Broker (e.g., AWS IoT Core, Google Cloud IoT Core): Acts as the intermediary, routing events from the sensors to the services.
- Business Need Addressed:
- Real-time Monitoring and Control: Users can monitor and control their smart home devices from anywhere.
- Proactive Alerts: The system detects anomalies and alerts users to potential issues (e.g., unusual temperature changes).
- Efficient Data Processing: The pub-sub architecture enables efficient processing of large volumes of data from multiple devices.
- Scalability: The system can easily accommodate new devices and data streams.
Data Processing Applications
Pub-sub patterns facilitate data pipelines, enabling efficient data ingestion, transformation, and analysis. This is crucial for various applications, including fraud detection, data warehousing, and real-time analytics.
- Scenario: A financial institution monitors transaction data in real-time to detect fraudulent activities.
- Events:
- Transaction Initiated: A new transaction is initiated.
- Transaction Approved: A transaction is approved.
- Transaction Declined: A transaction is declined.
- Components and Interactions:
- Transaction Service (Publisher): Publishes “Transaction Initiated” events when a new transaction occurs.
- Fraud Detection Service (Subscriber): Analyzes transaction data in real-time to identify potentially fraudulent activities. Publishes “Transaction Declined” or “Transaction Approved” events.
- Alerting Service (Subscriber): Receives “Transaction Declined” events and alerts relevant stakeholders.
- Reporting Service (Subscriber): Consolidates transaction data for reporting and analysis.
- Message Broker (e.g., Apache Kafka, Google Pub/Sub): Handles the routing of transaction events between services.
- Business Need Addressed:
- Real-time Fraud Detection: Transactions are analyzed in real-time, minimizing the risk of financial loss.
- Improved Efficiency: Automated fraud detection reduces manual review efforts.
- Scalability: The system can handle large volumes of transaction data.
- Reduced False Positives: Sophisticated analysis techniques help reduce false positives, improving the customer experience.
Final Wrap-Up
In conclusion, the pub-sub pattern emerges as a cornerstone of modern serverless architectures, offering unparalleled advantages in terms of scalability, decoupling, and event-driven capabilities. From orchestrating complex workflows to enabling real-time data processing, the applications of pub-sub are vast and varied. By embracing this pattern, developers can unlock the full potential of serverless environments, building applications that are not only highly efficient but also incredibly adaptable to the evolving demands of today’s digital landscape.
The adoption of pub-sub is key to building the next generation of responsive and scalable serverless solutions.
User Queries
What is the main benefit of using pub-sub in serverless?
The primary benefit is decoupling, which allows components to scale independently, improve resilience, and foster greater flexibility.
How does a message broker work in a pub-sub system?
A message broker acts as an intermediary, receiving messages from publishers, routing them to relevant subscribers, and managing message delivery and queuing.
What are some common use cases for pub-sub in serverless?
Common use cases include real-time data streaming, event notifications, IoT device communication, and asynchronous task processing.
What are the different message delivery guarantees?
The message delivery guarantees are “at-least-once” (message delivered at least once, potentially duplicates) and “at-most-once” (message delivered at most once, may be lost).